Introduction
こんにちは、住友商事のDXを加速する為の技術専門会社である Insight Edge にてデータサイエンティストをしております佐藤優矢です。
今回は、前職のメガベンチャーで担当していたレコメンドエンジンを、その歴史的経緯を踏まえて、協調フィルタリングからニューラルネットを用いたモデルの構築•評価までご紹介したいと思います。
目次
初期のレコメンドエンジン
レコメンドエンジン初期は協調フィルタリングによるレコメンドが主な方法でした。
概要としては、ユーザーとアイテムからなるマトリックスを作成し、このユーザーがこのアイテムを購入したなどの情報をマトリックスに埋めていく方法をとります。
よく使われるのは、Alternating Least Square という最適化アルゴリズムであり、このソルバーがpythonで使えるので、それを用いると推定スコア(おすすめ度)が得られます。
長所としては、手軽に精度の良いレコメンドエンジンが作れることで、短所としては、特にマトリックスがスパースな状況では精度が悪いことです。
協調フィルタリングの改善策
歴史的に、協調フィルタリングには様々な改善策が考えられています。
- アイテムベクトルによる類似度と混ぜてみる
- アイテムの説明文をベクトル化するなど
- アイテムの類似度と、協調フィルタリングによるおすすめ度を混ぜ合わせる形でおすすめ度を算出する。「正係数による距離の重み付け和はまた距離になる」に近い考え方で算出する
- 私が試したところ、あまり効果はなかった
- ユーザーベクトルによる類似度と混ぜてみる
- ユーザーのbioをベクトル化するなど
- 私が試したところ、これもあまり効果はなかった
ちなみに、協調フィルタリングをナイーブにニューラルネット化したモデルでは精度が逆に落ちることがわかっています。
協調フィルタリングを超える精度のレコメンドエンジン
最近になって、Variational Auto-Encoder を用いたモデルなど、協調フィルタリングを超える精度のニューラルネットベースのレコメンドエンジンが開発されてきています。 それらを一気に試すフレームワークにRecBoleがあり、メガベンチャーの人と話したところ、多くのメガベンチャーの会社が使っているようでした。 使い方は、クックパッドでの紹介記事に詳しく載っています。
どのモデルを選べば良いかですが、データによって異なるので一概には言えません。ただ、マトリックスがスパースな時に精度が良かったモデルは、グラフニューラルネットを使ったモデルでした。ユーザーに繋がっているアイテムがあり、それに繋がっているユーザーがあるという形に連結していき、同じものを購入したユーザー同士を繋げるようなアルゴリズムになっています。 これらは先のクックパットの結果と大きく異なり、データによって最適な手法は異なることを表しています。
独自アルゴリズムの精度評価基盤の構築方法
最新のアルゴリズムはRecBoleにアップデートされることが多いですが、if-thenなどの独自アルゴリズムを後処理として付け加える(フィルターなど)ことが考えられます。その際は独自に評価基盤を整えます。
特定の精度指標による評価をアルゴリズムとして実装し、その評価指標による精度をもとに、モデルがいままでより良いものかどうかを判断していきます。
指標は Precision@k と Recall@k がよく用いられます。

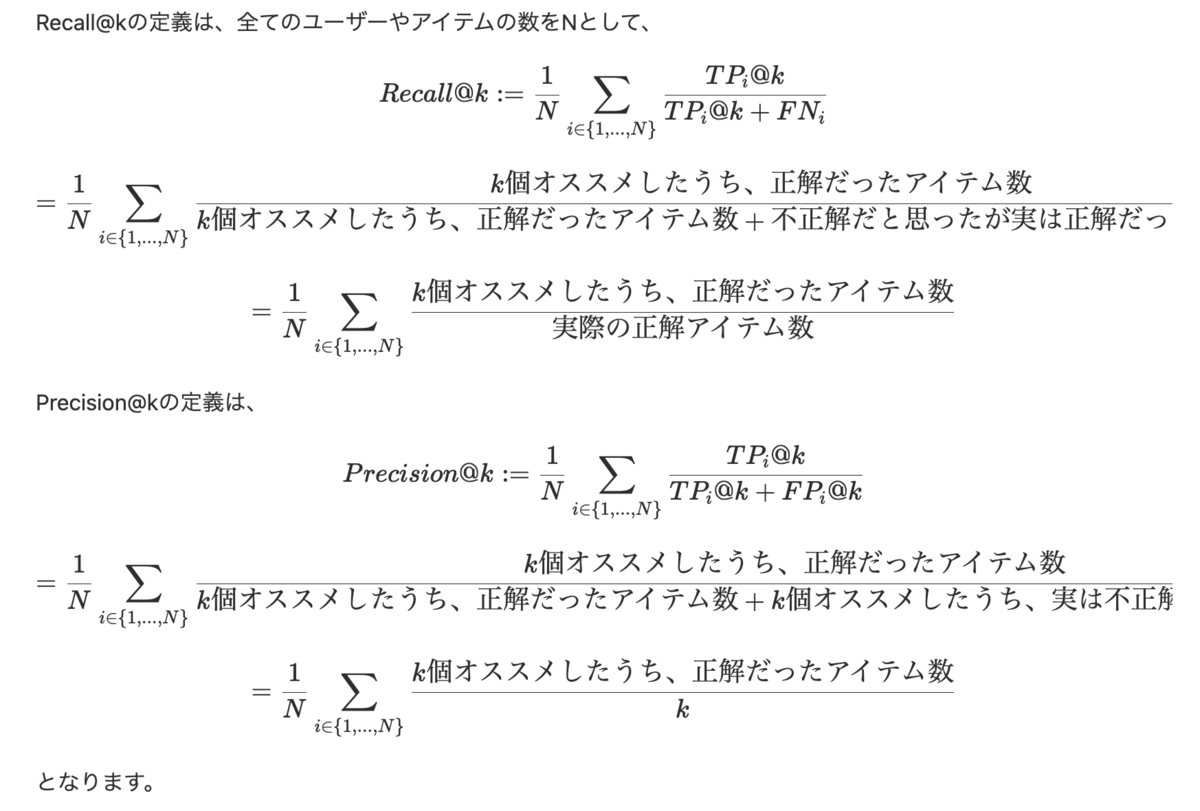
レコメンドエンジンの精度を測る指標
Precision@k と Recall@k の定義の違いを考えると、異なる部分は分母のうち、正解データに絞るかどうかという点です。
専門書などでも触れられているのをみたことはありませんが、Precision@kだと、取れた正解データ(実際のユーザーの遷移データなどから取ってきます)の量が少ないと小さく見積もられてしまいます。データの量に応じて精度が変わってくるということが起こるわけです。
それに対して、Recall@kではその影響が抑えられています。なので、レコメンドエンジンのモデルの精度を測る時の指標はRecall@kがよく用いられるということかと思います。
まとめ
本稿では、歴史的によく用いられてきた協調フィルタリングから、ニューラルネットによるモデルのツールによる実装、またその最新モデルをカスタムした状況で必要になる評価基盤についてざっと振り返りました。この記事からさらに深い議論が起こると嬉しいです。