目次
導入
こんにちは。InsightEdgeのデータサイエンティストの小柳です。
本記事では前回の記事で紹介したPyMCの使い方を学ぶ一環として、PyMConの紹介をしようと思います。 突然ですが、PyMCに限らずモジュールの使い方を学ぶ際にはいくつか困難がありますよね。 PyMC固有の話とそうでない話を混ぜて挙げてみると
- 使う人があまり多くない。機械学習ならいざしらず、統計系の人は組織に少なくなりがち。したがって詳しい人が近くにおらずあまり人に聞けない。
- 公式ドキュメントを読んでもなんだかよくわからなかったり、なぜ例としているコードになったのかがわからないことがある。使用例のコードがない時もある。
- 教科書がない。あったとしても新しくて効率的な構文のキャッチアップができないことが多い。
これらを克服するためには忍耐強くデモコードを読み解いたり、実装を遡る必要があり大変です。 今回取り上げるベイズ統計用のMCMCサンプラーであるPyMCはコミュニティ作りを意識的にしており、PyMConウェブシリーズという名前でYouTubeに動画投稿をしています。 このシリーズの動画はPyMCの開発者や世界中で活躍するエンジニア、学校の先生たちがケーススタディー的に教えてくれていてすごくありがたいです。最新の機能のキャッチアップにもなります。 今回はこの動画シリーズの紹介をしようと思います。自分のやりたい分析に近いものがあったら見てみると新たな発見があるかもしれません。
PyMConは2020年位に始まったWebシリーズで、2020年に投稿されたものは'PyMCon 2020'とサムネに書いてあリますが、それ以降のやつは年度を切るのをやめてしまったみたいです。 全部紹介しているときりがないので、2023年に投稿されたものをいくつか紹介していきます。
動画紹介1
リンク:https://www.youtube.com/watch?v=0B3xbrGHPx0
テーマ:Automatic Probability
スピーカー:Ricardo Vieira (PyMC Labs所属)
Automatic Probabilityは自動微分のアナロジーです。 自動微分は偏微分を実行するルーティンであり、チェインルール、指数の微分ルール、積や商の微分ルール等を用いて機械的に微分を計算します。機械学習には必須で、最適化の勾配法やMCMCのNUTS、変分法に使われます。 一方自動確率は確率を自動で計算できるようにしたルーティンのセットで、列挙や、変数の交換などなどを行い確率を計算します。ベイズ統計には必須であり当然PyMCの内部でも使われている技術で、その紹介動画です。 内容はPyMCとそのバックエンドであるPyTensorを使った単純な分布の確率密度の計算や、変数変換時の確率密度計算、打ち切り分布の密度計算、条件付き確率密度の計算、混合分布の確率密度計算等です。
いくつか例示してみます。例えば確率密度の計算は以下の通りです。\ ->のところは出力だと思ってください。
import pymc as pm
x = pm.Normal.dist()
z = x + 5
def prob(rv, value):
return pm.logp(rv, value).exp()
prob(x,0.98146052).eval()
-> array(0.24645622)
prob(z,5.98146052).eval()
-> array(0.24645622)
このように、zの分布を指定していないのに変数変換ができています。 これは正規分布が平行移動しているだけなので難しくないですがそうでない場合も対応可能です。 例えば1対1変換で
import pytensor.tensor as pt x = pm.Normal.dist() z = pt.exp(x) prob(x,-1.18149583).eval() -> array(0.1985122) prob(z,0.30681945).eval() -> array(0.64700006)
と計算できます。ヤコビアンをかけてきちんと変数変換できているか確認してみましょう。
import numpy as np prob(z,0.30681945).eval()*np.exp(-1.18149583) -> 0.19851219823788108
うまくいっていますね。
次は多対1変換。実はこれもできます。
x = pm.Normal.dist(0,1)
z = pt.abs(x)
np.isclos(
prob(x,0.3).eval(),
(prob(z,0.3) /2).eval()
)
-> True
打ち切り変換もできます。
rv = pm.Normal.dist(shape=(3,))
clipped_rv = pt.clip(rv, -1, 2)
censored_rv = pm.Censored.dist(rv, lower=-1, upper=2)
clipped_value = [-1, 0.5, 2]
print(
prob(clopped_rv, clipped_value).eval(),
prob(censored_rv, clipped_value).eval(),
sep="/n"
)
->[0.159 0.352 0.023]
->[0.159 0.352 0.023]
確率変数が2つ以上の時の確率密度や、条件付き確率密度も算出できます。
import pytensor
import pytensor.tensor as pt
from pymc.logprob.basic import conditional_logp
x = pm.Normal.dist()
y = pm.Normal.dist()
z = x-y
def conditional_prob(rvs_to_values: dict, fn=True):
logps = conditional_logp(rvs_to_values).values()
probs = [logp.exp() for logp in logps]
if fn:
values = list(rvs_to_values.values())
return pytensor.function(values, probs)
else:
return probs
x_value = pt.scalar('x_value')
y_value = pt.scalar('y_value')
z_value = pt.scalar('z_value')
prob_fn = conditional_prob({x: x_value, y:y_value})
print(prob_fn(x_value=0.5, y_value=0.9))
->[array(0.35206533), array(0.26608525)]
prob_fn = conditional_prob({x: x_value, z:z_value})
print(prob_fn(x_value=0.5, z_value=0.9+0.5))
->[array(0.35206533), array(0.26608525)]
prob_fn = conditional_prob({y: y_value, z:z_value})
print(prob_fn(y_value=0.9, z_value=0.5-0.9))
->[array(0.26608525), array(0.35206533)]
このような感じで、条件付き分布の確率密度が柔軟に計算できます。 直接使う方法はすぐには出てきませんが、PyMCとPyTensorの柔軟性を垣間見られて面白いかと思います。
動画紹介2
リンク:https://www.youtube.com/watch?v=b47wmTdcICE&t=1455s
テーマ:Bayesian Causal Modeling
スピーカー:Thomas Wiecki (PyMC Labs所属)
最近界隈で盛り上がっている因果推論系がテーマです。前半は実際にベイズを使った因果推論ですが、後半は最近出たPyMCシリーズのマーケティング用ツールPyMC-Marketingを使ったケーススタディで、ベイズとMMMを使って広告効果モデリングをした話です。 動画の詳細欄を見ればわかるのですが、スライドとコードが公開されているので詳細には立ち入らずちょっとした紹介程度にします。
前半はオーソドックスな因果推論の話で、扱う題材も広告効果です。 背景としてある商品の売上を上げるために、Google Adsでネット広告とTVCMを行った時に、本当にGoogle Adsに効果があるのかを知りたいという状況を考えます。 Google Adsを打った時と打っていない時での架空の売上のヒストグラムは以下の通りで、
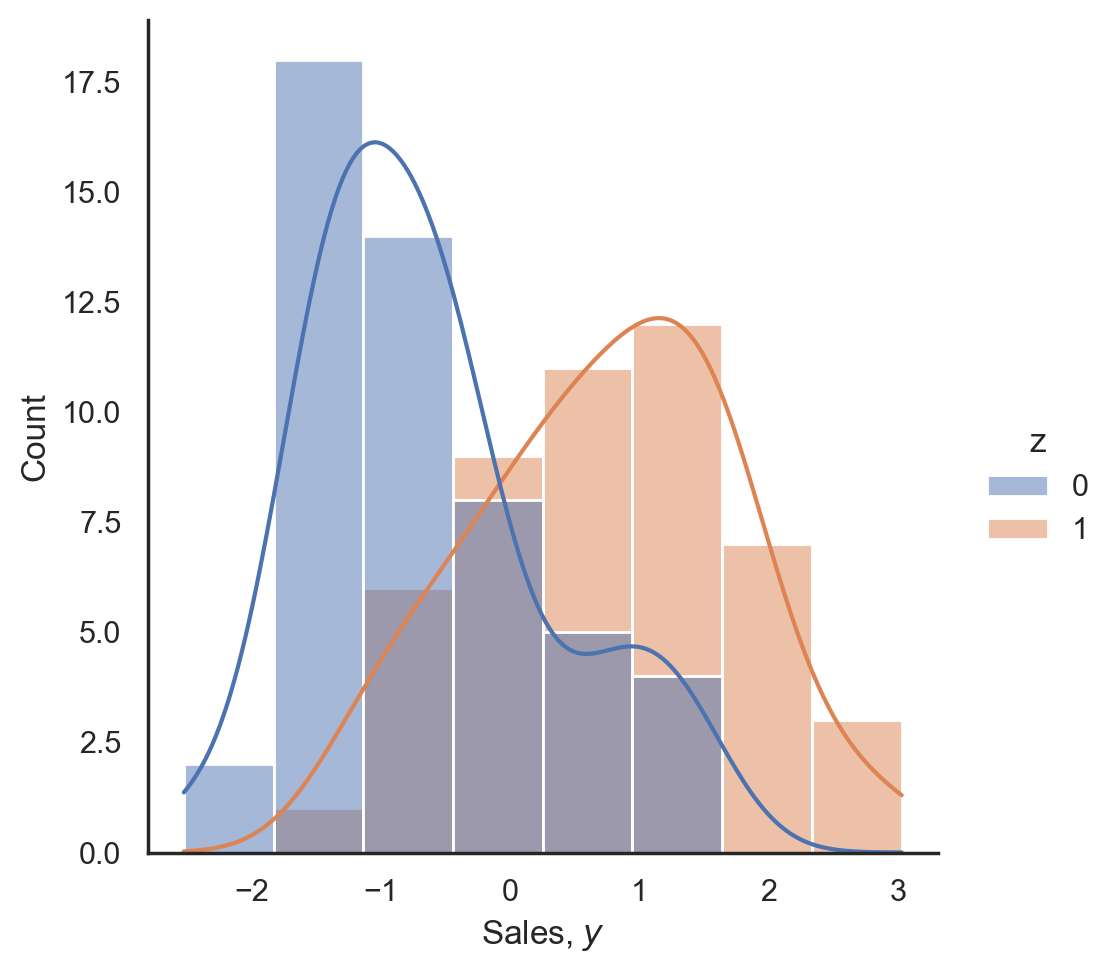
t検定やベイズ的検定のどれを使ってもバッチリ差があると判定される結果です。 実はこのデータは人工的に作られたもので、その生成過程的には効果なしと出て欲しいものです。
さて、この状況に対し3つの変数とそれらの生成過程を以下のようにを考えます。
C:TVCM費用。連続値を取る。売上に影響を及ぼすし、相乗効果を狙うためGoogle Adsのオンオフにも影響を与える。
Z:Google Adsのオンオフ。0か1の二値を取る。売上に影響を与える。
Y:売上。連続値を取る。
この時のデータ生成過程を以下のように考えます。
このモデルに対し適当な事前分布をおいてやり、の事後分布を見てやれば良いわけです。
今回の話は本来それで終わらせられるのですが、PyMCは5.8から因果推論系の機能を足したようでdo-operator等が紹介されています。本動画はそれを用いており、モデルの書き方は以下のようになります。ここまでは通常のモデリングと同じです。
with pm.Model() as model:
# CからY,Zへの効果の事前分布
beta_c = pm.Normal('beta_c', shape=3)
# ZからYへの効果の事前分布
beta_z = pm.Normal('beta_z', shape=2)
# Yの観測ノイズ
sigma_y = pm.HalfNormal('sigma_y')
c = pm.Normal('c', mu=0, sigma=1, observed=tv_spend)
z = pm.Bernoulli('z', p=pm.invlogit(beta_z[0] + beta_z[1]*c),
observed=search_spend)
y_mu = pm.Deterministic('y_mu', beta_c[0] + (beta_c[1] * z) + (beta_c[2] * c))
y = pm.Normal('y', mu=y_mu, sigma=sigma_y, observed=sales)
idata = pm.sample()
これに対して、do-operatorを用いてzをCから切り離して決定するモデルを定義しさらにそこからYをサンプリングするのは以下のコードになります。
from pymc_experimental.model_transform.conditioning import do
model_z0 = do(model, {'z': 0})
model_z1 = do(model, {'z': 1})
with model_z0:
idata_z0 = pm.sample_posterior_predictive(idata)
with model_z1:
idata_z1 = pm.sample_posterior_predictive(idata)
そして、平均介入効果の計算も簡単です。
ATE = idata_z1.predictions - idata_z0.predictions
このように非常に簡単にATEが計算できるようになっています。実際にこのデータでATEを算出すると、-0.1から0.1のあたりに分布しており、無事効果がないことがわかります。 今回挙げたような線形な関係性であればこれを使う必要はありませんが、非線形な効果が絡んでくるようなモデルを考える場合は便利になりそうです。
後半はMMMをベイズと組み合わせ分析のケーススタディになっています。実はここで紹介されているものはPyMC Labsが分析した事例で、PyMCon2020の動画に詳しい説明があるので興味があればご覧ください。 あまりMMMに詳しくないので、この事例では通常固定値とされるMMMのパラメータ時間とともに推移するようにモデリングしたようで、同様のモデルがPyMC-Marketingで使えるようです。 PyMC-Marketingは名前の通り広告効果分析に特化していて、ROAS(広告の費用対効果らしいです)や広告費を事後的にあの時いくらにしていたら的な分析、CLV(Customer Lifetime Value)推定等マーケティングで知りたくなりそうな分析は揃っているようです。
動画紹介3
リンク:https://www.youtube.com/watch?v=2dGrN8JGd_w
テーマ:A Soccer-Factor-Model
スピーカー:Maximilian Goebel (Università Bocconi所属)
そもそもサッカーファクターモデルとは何でしょうか? 私は聞いたことがありませんでした。 これは金融業界で使われるファクターモデルというものから派生したものだそうです。 ファクターモデルとはリスク資産のリターンのモデルで、資産iのリターンを 1.その資産固有のリターン、2.すべての資産に影響を与える複数の要因の影響の線形結合、3.エラー項の3つの和として分解したもののようです。 サッカーファクターモデルよりは知名度があるようで、ファクターモデルでGoogle検索すると このページ を筆頭にいくつもヒットしますし、Wikipediaにも ページ があります。サッカーの方はヒットしません。 そのファクターモデルを使うことのご利益は2つあります。1つ目はファンドが市況の影響をどのように受けるかが推定できることです。そして2つ目はファンドのパフォーマンスから市況の影響を除去することでマネージャーがどれだけ優秀か=どれだけリターンを高められるかを推定できることです。
この2つ目のご利益を横展開して、チームスポーツにおいて個人の強さを推定してやろうというのが今回の動画のテーマです。 本動画ではサッカーをモチーフに各選手が試合でゴールを決める確率をモデリングします。
このが以下の確率を持つベルヌーイ分布に従うようなモデルを考えます。
これの各パラメータ、特にを見ることで、その選手のパフォーマンスから例えばチーム全体の調子や、チームのアシスト力のような要素を除去し本来のパフォーマンスを測ることができるのだそうです。
当然この手法の応用先は別にサッカーに限らず、チームスポーツだったり営業チームのパフォーマンスだったりと様々な例が考えられそうです。
モデルの良し悪しはROC、LogProb、RMSE等で測定していましたが、これは取り扱うテーマ次第でしょう。
分析に関してはそれほど難しい話ではないので省略します。 アイデアの面白さや応用先の広さ、ファクターをどうするか等を考えると分析者の力量が出そうなトピックでした。
動画紹介4
リンク:https://www.youtube.com/watch?v=ri5sJAdcYHk
テーマ: Introduction to Hilbert Space GPs in PyMC
スピーカー:Bill Engels(PyMC Labs所属)
この動画のテーマはヒルベルト空間ガウス過程です。
私はそこまでガウス過程に詳しくないので正直このまとめはあまり自信がありません。 この動画ではそんなガウス過程初心者のために通常のガウス過程の特徴や長短所そしてその短所の乗り越え方としてのHSGP(Hilbert Space Gauss Process)を解説してくれています。といっても別に理論を詳細に扱うわけではありません。
ガウス過程の長所として
- 柔軟なモデリング。線形モデルもニューラルネットワークも可能
- 解釈可能。モデリング次第だが解釈可能なモデルも作れる。
- 不確実性の定量化。各地点の分散も計算可能
一方圧倒的な短所として
- 遅い。計算量が
。
が挙げられます。この短所に対して多くのアプローチが提案されており、その1つが今回の動画で紹介されているヒルベルト空間ガウス過程です。もちろんいつでも使えるわけではなく、
- PPL(Probabilistic Programming Language:確率的プログラミング言語)を使う必要あり
- 入力変数次元は最大4
- カーネル関数に制限あり
等の制約があります。このような特徴なので他のPPLでも実装できて、StanやBRMS、NumPyroで実施した例があるようです。
さて、PyMCでの実装です。まず通常のガウス過程をPyMCで実施する際には以下のようにします。 (注意:このコードはこのままでは動きません。詳細は https://github.com/bwengals/hsgp/blob/main/cherry_blossoms_hsgp.ipynb を参照ください。動画と同じコードがあります。)
with pm.Model(coords=coords) as model:
# Set prior on GP hyperparameters
eta = pm.Exponential("eta", lam=0.25)
ell_params = pm.find_constrained_prior(
pm.InverseGamma,
lower=10, upper=200,
init_guess={"alpha": 2, "beta": 20},
)
ell = pm.InverseGamma("ell", **ell_params)
# Specify covariance function and GP
cov = eta**2 * pm.gp.cov.Matern52(1, ls=ell)
gp = pm.gp.Latent(cov_func=cov)
f = gp.prior("f", X=df["year"].values[:, None], dims="year")
これをHSGPにするには
gp = pm.gp.HSGP(m=[400], c=2.0, cov_func=cov)
とするだけで、非常に簡単です。
PyMCを使ってHSGPを行うことにはいくつか長所があります。
- インプットデータの次元を変えるのが簡単でpm.gp.HSGPの引数mを変えればよいだけ。
- 共分散関数を加法的に定義できる。covを2つ書いてHSGPの引数にcov_func=cov1+cov2をとるだけ。
- 好きなカーネル関数が書きやすい。よく使われる二乗指数カーネル、指数カーネル、Maternカーネルあたりはすでに実装されていますが、変わったものが使うことも可能。
- 基底と共分散を線形化した形で出力できる。これを使うことで予測時に高速に計算可能。
私があまりガウス過程に詳しくないのでこの機能の素晴らしさや使いやすさが伝えきれなかったかもしれませんが、ガウス過程の理解に役立てば幸いです。
まとめ
本記事ではPyMConの紹介をするための動画をいくつか紹介しました。各動画のテーマはバラエティに富んでいて、この記事を読むような方々なら恐らくどれかにはご興味いただけるかと思いますし、新しい知識を得るのに非常に役立ちそうな予感は感じられると思います。
PyMC界隈、特に日本語コミュニティはまだまだ活発になる余地は十分にあると思います。本記事がその一助になれば幸いです。
Insight EdgeではPyMCに限らず、様々な技術に興味を持っているデータサイエンティス・エンジニアを募集しています! カジュアル面談も行っていますので、興味がある方は以下サイトを御覧ください!