はじめに
はじめまして、InsightEdge 分析チームの中野です。 今回は自然言語からCypherクエリを生成する手法について、LLM(大規模言語モデル)を用いたアプローチを紹介します。
最近、RAG(Retrieval-Augmented Generation)という手法が注目されています。これは、LLMが外部の知識ベースを検索し、その情報を基に回答を生成するプロセスです。また、外部知識にナレッジグラフを利用することでデータを構造化し、より関連性の高い情報を抽出することも注目されています。
ナレッジグラフを使用するにはneo4jのようなグラフデータベースを使用することが一般的です。 しかし、このRAGプロセスではテキストからグラフクエリ言語であるCypherクエリを生成する必要があります。
この記事では、このRAGプロセスでCypherクエリを生成する際の課題と、Chain-of-Thought(CoT)を使用して精度向上を試みた結果について紹介します。
text-to-cypherの課題
ナレッジグラフを使用したRAGプロセスでは、テキストからCypherクエリを生成するステップが必要となります。 しかし質問文ではクエリの構成を具体的に指定しないため、必ずしも適切なクエリを生成できないという問題があります。
例として Twitchのソーシャルネットワーク を使い、簡単なクエリの生成を試みます。 このTwitchのネットワークは、ユーザーやゲームのノードで構成されており、どのユーザーがどのゲームをプレイしたか、誰が誰にコメントしたかといった情報が含まれています。 このグラフデータベースに対して「人気のゲームのタイトルを教えてください。」というテキストから、Cypherクエリを生成させてみます。
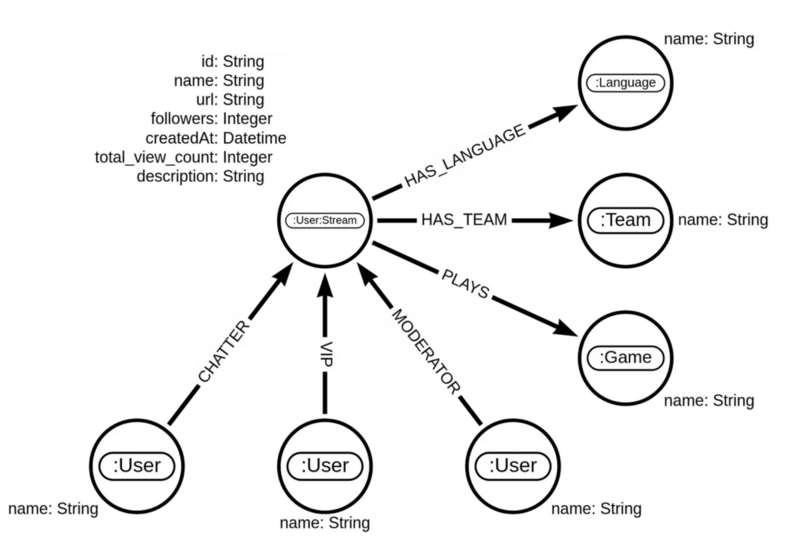
「人気のゲームのタイトルを教えてください。」という問いに対し、gpt-3.5-turboを用いた生成結果ではプレイされたゲームを一覧表示するクエリが生成されました。しかし、これは配信者がプレイしたゲームすべてを列挙するため出力が数万から数百万件に及ぶ可能性があり、適切なクエリとは言えません。
-- gpt-3.5-turboを使用して「人気のゲームのタイトルを教えてください。」から生成したクエリ -- NG:応答が多すぎて、適切なクエリではない。 MATCH (s:Stream)-[:PLAYS]->(g:Game) RETURN g.name
一方、gpt-4を用いた場合は配信者がプレイしたゲームを列挙した後、ゲーム名ごとにプレイ回数を集計し、人気のゲームを上位10件表示するクエリが生成されました。このクエリは、人気のゲームを知りたいならば、ゲームごとにプレイした人数を調べればよいという意図を反映した、適切なクエリと言えます。
-- gpt-4を使用して「人気のゲームのタイトルを教えてください。」から生成したクエリ -- OK:ゲームごとにプレイした人数が調べられているため、適切なクエリである。 MATCH (s:Stream)-[:PLAYS]->(g:Game) RETURN g.name AS Game_Title, COUNT(*) AS Popularity ORDER BY Popularity DESC LIMIT 10
このようにgpt-3.5-turboでは簡単な集計を必要とするクエリですら満足に生成することはできません。gpt-4では適切にクエリを生成できているもののコストがgpt-3.5-turboの約20倍、速度が10分の1️と非常に低速です。そのためエージェントなど何度もグラフに問い合わせを必要とする用途では、なんとかしてgpt-3.5-turboのような軽量なLLMに回答を作成させたいところです。
対策と検証
精度向上のために、今回はChain-of-Thought(CoT)を試します。CoTは、入力から出力に至るまでの中間過程を明示することで、複雑な問題にも対応できる手法です。 この手法を用いることで、軽量なLLMでも高精度な出力を実現できる可能性があります。
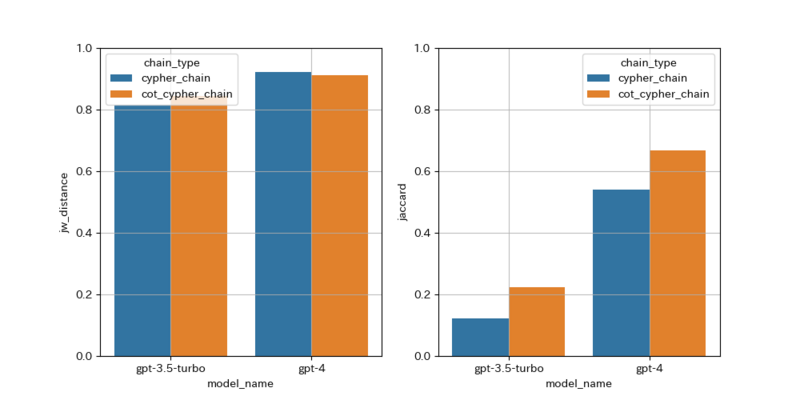
改善施策の効果を検証するために、10個程度の質問文とクエリのペアを手作業で作成し、gpt-3.5-turbo、gpt-4、それにCoTを加えたバージョンの4つについて、生成されたクエリとその応答結果を比較します。 クエリの精度はJaro-Winkler距離で、応答結果の精度はJaccard係数で測定します。
Chain-of-Thought Promptingの実装
実装はLangChain(0.1.0)を使用します。 まず通常のcypherクエリだけを出力するChainを以下のように定義します。
# Chain-of-Thought Promptingを使用しない class CypherResponse(BaseModel): query : str = Field(title="Cypher Query") def get_cypher_chain(graph, model): parser = PydanticOutputParser(pydantic_object=CypherResponse) prompt = PromptTemplate( template="""Based on the Neo4j graph schema below, write a Cypher query that would answer the user's question: {format_instructions} {schema} Question:{question} JSON OUT:""", input_variables=["question"], partial_variables={ "schema":graph.schema, "format_instructions": parser.get_format_instructions() } ) chain = prompt | model | parser return chain
次にChain-of-Thoughtを使用する場合は以下のように定義します。queryの他に思考過程も出力させます。
# Chain-of-Thought Promptingを使用する class ChainOfThougthCypherResponse(BaseModel): chain_of_thought : str = Field(title="Thought process in the process of generating a cypher query") query : str = Field(title="Cypher Query") def get_cot_cypher_chain(graph, model): parser = PydanticOutputParser(pydantic_object=ChainOfThougthCypherResponse) prompt = PromptTemplate( template="""Based on the Neo4j graph schema below, write a Cypher query that would answer the user's question: {format_instructions} {schema} Question:{question} Lets think step by step. JSON OUT:""", input_variables=["question"], partial_variables={ "schema":graph.schema, "format_instructions": parser.get_format_instructions() } ) chain = prompt | model | parser return chain
テストデータ
テストデータとして質問文とCypherクエリのペアを10組程度作成しました。
data = [
{
"question": "韓国語(ko)を使用するストリーマを調べて。",
"cypher": "MATCH (s:Stream)-[:HAS_LANGUAGE]->(l:Language) WHERE l.name = 'ko' RETURN s.name AS Streamer "
},
{
"question":"人気のゲームのタイトルを5つ教えてください。",
"cypher":"MATCH (g:Game)<-[:PLAYS]-(s:Stream) RETURN g.name AS game, COUNT(*) AS streamCount ORDER BY streamCount DESC LIMIT 5"
},
...
]
評価指標
評価方法については こちらのブログ を参考としました。 生成されたクエリの精度はJaro-Winkler距離を使用して測定し、応答結果はJaccard係数を使用して測定します。
- Jaro-Winkler距離 は、2つの文字列の類似性を測定するための手法です。生成したクエリと正解のクエリがどれだけ似ているかを測定するために使用します。完全に一致する場合は1になり、完全に異なる場合は0となります。
- Jaccard係数 は、2つの集合の類似性を測定するための手法です。生成したクエリを使い検索されたデータと正解のデータにどれだけ一致しているかを測定するために使用します。完全に一致する場合は1になり、完全に異なる場合は0となります。
結果
gpt-3.5-turbo、gpt-4、gpt-3.5-turbo+CoT、gpt-4+CoTに対して、生成されたクエリとクエリの応答結果を比較します。CoTを使用することでクエリの応答結果の精度が向上することを確認できました。
まとめ
本記事では、Chain-of-Thoughtを使用して、gpt-3.5-turboのような軽量なLLMでもgpt-4のような高精度な出力を実現できることを示しました。 今後は、Chain-of-Thoughtを活用して、テキストからCypherクエリを生成する手法をさらに精度向上させていきたいと考えています。