こんにちは。12月からInsight Edgeに参画したData Scientistのカイオと申します。 入社してから早速、ChatGPT案件やデータサイエンス案件をいくつか担当しています。
今回は、とある案件で使用したMLパイプライン管理ツール「Kedro」について紹介したいと思います。
目次
Kedroとは
まず、Kedroとは何かの説明から始めましょう。
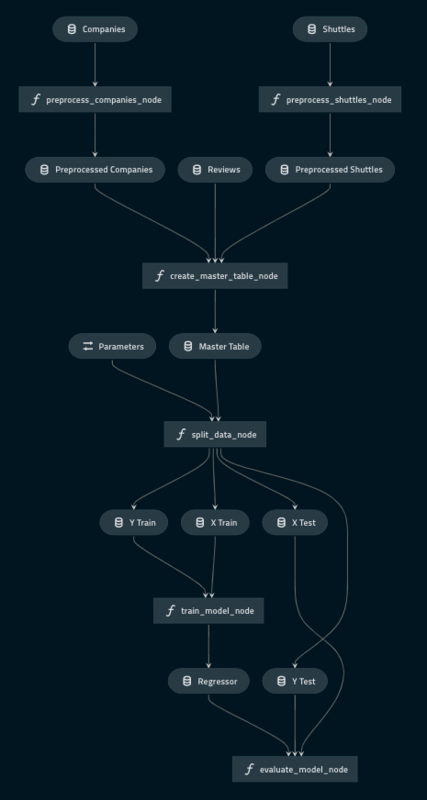
Kedroとは、データサイエンスのパイプラインを管理するツールです。データ収集、変換やモデル学習、ハイパーパラメータ調整の管理から精度評価までまとめて簡単にしてくれます。
パイプライン中の処理の中間成果物やモデルを簡単にアクセスできるようにしてくれます。
なぜKedroを選んだか
今担当している案件では、事前処理の段階で色々な関数を実行しています。datetime⇨datetime + timezoneに変換したり、ダミー変数を作成したりしています。
複雑な処理がたくさんある中で、途中の成果物を常に確認する必要があります。 例えば: before_preprocessing.csv ⇨ after_preprocessing.csv ⇨ train.csv, test.csv, validation.csv
それぞれのステップの時点でファイルの中身を確認したいですね。毎回 .to_csv() を実行するのは面倒だし、フォーマットは簡単に変えられない。
Kedroを使うと自動で生成されるだけではなくて簡単にフォーマットを変えられます。もちろん、csvからPickleまで幅広いフォーマットをサポートしているだけでなく、バージョン管理やリモートアクセスもできます。変数名をcatalog.ymlに記入すると変数として使えるだけでなくファイルとして保存されます。
それがKedroを選んだ1つの理由です。以下はそのcatalog.ymlの一例です。 もちろん、products_rawなどもそのままパイプライン内で変数として使われます。
products_raw: type: pandas.CSVDataset filepath: data/01_raw/products_raw.csv products_preprocessed: type: pandas.CSVDataset filepath: data/02_intermediate/products_preprocessed.csv lgb_model: type: pickle.PickleDataset filepath: data/06_models/final_model.pkl results: type: pandas.ParquetDataset filepath: s3://customer_bucket/results.pq
もう1つの理由は、プロジェクトの構成を決めてくれる機能です。
kedro new を実行すると自動でテストや、データ格納ディレクトリまで作ってくれます。
複数人で同じプロジェクトを開発するとき、個人のディレクトリ構成のばらつきを気にする必要がなくなります。
最後の理由は、それぞれのパイプラインを単独で実行できるところです。
何かパラメータを変えた時、
kedro run --pipeline=training
というふうに実行でき、一部を簡単に飛ばせます。
他のツールとの比較
よく比較されるツールの中で、私の使ったことがあるのはOptunaとMLflowなので、Kedroと比較してみます。
MLflow
- MLflowは実験を管理するツールです。モデルやデータセットのバージョン管理ができて精度などの可視化ができる
- Kedroでcatalog機能を使えばデータセットやモデルのバージョン管理はできるが可視化やmetrics測定はそこまで得意ではありません
Optuna
- Optunaはハイパーパラメータ調整フレームワークです。Kedroでも同じようなことができるが、そこまで向いていない気もします。ただし、2つを組み合わせることによってよりパワーフルなパイプラインを作ることができる(実際にその使い方をしている案件があります)
SageMaker Pipelines(おまけ)
- SageMakerはAWSの機械学習向けのサービスです。クラウドのサービスと比較するのは少し無理がありますが、共通点が多いのも事実です
- S3にデータのバージョン管理ができるところはKedroのカタログ機能に似ていて同じようにパイプラインを設計できます
メリット
- 中間成果物が自動で保存される(個人的にこれが一番大きい)
- プロジェクトごとによる構成の差分が少なくなる
- パイプラインの一部だけ実行できる(例:評価部分だけ実行したい)
デメリット
- パイプライン実行中にエラーが発生した際、Tracebackが長く問題箇所まで辿りづらい
- 中間成果物のフォーマットによって、忠告なしに情報が失われる
- 例:PandasのDataframeをcsvとして保存したら、csvがサポートしていない型の変数は勝手に変換されて情報が消える
- Poetryとの相性が悪い
- 共存できるという方もいますが個人的にやってみたら色々難航して結局pip-compileでいきました
- 早いプロトタイピングには向いていない
- 簡単な使い捨てプログラムなどの場合はJupyterのほうがいい
まとめ
Insight Edgeに入社してから初めてKedroというツールを知りました。今まで数年間、機械学習関連の案件をやってきたのに、Kedroの存在を知らなかったのは少し恥ずかしいです。
色んな背景の方々や幅広い専門知識を持っている優秀なエンジニアが周りにいて毎日新しい知識を身に付けられるのは当社の素晴らしいところだと思います。これからも新しい技術やツールを学ぶとともにソフトなスキルを磨いて、周囲のエンジニアと切磋琢磨していき、プロジェクトで活用していきたいです!