初めまして、去年の11月にInsight Edgeへ参画したEngineerの田島です。 現在の業務では生成AI用いたDX案件や住友商事グループ事業のソフトウェア開発に携わっています。
まだ加入してから数ヶ月ですが、Insight Edgeの特徴として「小回りの良さと技術選定の幅の広さ」を強く感じています。 出島組織なので開発を柔軟に進めていくことが可能であり、 幅広いビジネスをしている総合商社ならではの様々な課題に対応すべく、 幅の広い技術選定が求められるように感じます。 また、エンジニア・データサイエンティスト・コンサルタントが互いにリスペクトし、プロフェッショナルとして働いてるので、成長の場としても適しているかと思います。
本記事ではComputer Visionのシステムを題材に、生成AIの活用で注目が集まっているAzureを用いたMLOpsの実現について紹介したいと思います。
概要
想定ケース
ビジネスシーンとして、各カメラから取得される人流情報を防犯や空調の最適化に活かすことを想定します。

複数のカメラを用いたシステムの課題
カメラシステムを実際に運用する上で、設置条件は個体毎に異なります。 これにより、カメラ毎の認識精度がばらつくと想定されます。 例えば、暗所による撮影における感度自動制御で、下図のようなノイズが生じます。 (感度自動制御とはカメラ信号処理の一部で、適正な明るさが得られない場合などに電気的に信号を増幅させることで適正な明るさの画像を得る処理のことです。) 同じカメラにおいても長期期間システムを運用するうえでは、季節や周辺環境の変化により影響度が変化します。
このカメラの精度ばらつきが、本ユースケースの人流情報の効果的な利用の問題になると考えられます。

システムの概要
本記事では、認識精度のばらつきを自動的に補正する画像認識システムを考えます。 これにより、安定した認識率のシステムを構築するだけでなく、 従来はカメラの設置条件などを変えるなどしていた作業をシステムとアルゴリズムが肩代わりすることで、保守工数を削減したシステムを構築します。 このシステム構築にあたっては、Azure Custom VisionのOptimization機能を用いて、カメラ毎の条件に合わせて再学習します。
(*) 本記事ではセンサーノイズや画像処理の詳細には踏み込みません。あくまでシステム構築に主眼を置きます。
システムの内容
MLOps
機械学習の社会実装をするうえで、他のシステムと同様に継続的なインテグレーションとデリバリーが求められます。 MLOpsはこれを実現するエコシステムを指し、Googleの提唱する 実現レベル が有名です。 この実現レベルの概要は以下の通りです。
- レベル0:手動による学習プロセス。モデルの変更が稀なケースを想定します。
- レベル1:学習パイプラインの自動化。パイプライントリガーによって自動的にモデルを更新します。
- レベル2:CI/CDパイプラインの自動化・効率化。モデルの変更アイデアを迅速に反映・検証します。
そこで本記事ではレベル1を題材に、継続的にモデルを更新することで、設置環境の変化によるノイズ影響の解決を考えます。
インフラ構成
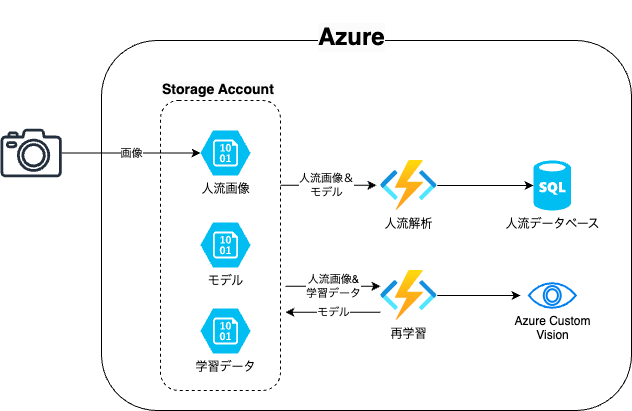
本記事で構築するシステムのアーキテクチャは以下の通りです。
Azure Custom Vision
Azure Custom Visionは特定のドメインに特化した画像認識モデルを作成可能なサービスです。 利用にあたっては機械学習モデルの専門知識は必要なく、WebUIまたはREST APIでサービスを利用できます。 レベル1のMLOpsに必要不可欠な要素であるモデルのテストやエッジ環境などへデプロイに対応しています。
2024/02現在は、1枚の画像をクラス分類するClassificationと画像中に物体位置を認識するObject Detectionに対応しています。 本記事では、画像中から対象物の数を抽出するためにObject Detectionを採用し、REST APIを用いてカメラ毎に適切な学習を自動的に行います。
インフラ構成の説明
カメラで取得された画像データは、AzureのBlobストレージにアップロードされるものとします。 このアップロードをトリガーとして、Azure Functionsを起動させ、人物検出します。 人物検出には上のAzure Custom Visionで生成したONNXモデルをStorageからダウンロードします。 そして、検出された人物の数がSQLデータベースに記録されます。
また、Azure Functionsの定期実行を用いて、モデルを更新します。 モデル更新用に撮影された複数枚の画像から統計的なばらつきを推定し、それらの影響を学習データに付加して、カメラ環境に合った学習データを生成します。 この学習データをAzure Custom Visionにアップロードし、モデルの再学習します。学習終了後にStorageのモデルを更新します。 今後エッジでの検出処理を想定し、モデルデータのエクスポートします。 仮にクラウドでの処理に完結させる場合は、モデルのAzure Custom VisionのAPIエンドポイントとしてパブリッシュすることで、システムを簡略化可能です。
ソースコード
ソースコードは以下のレポジトリで公開しています。
デプロイメント
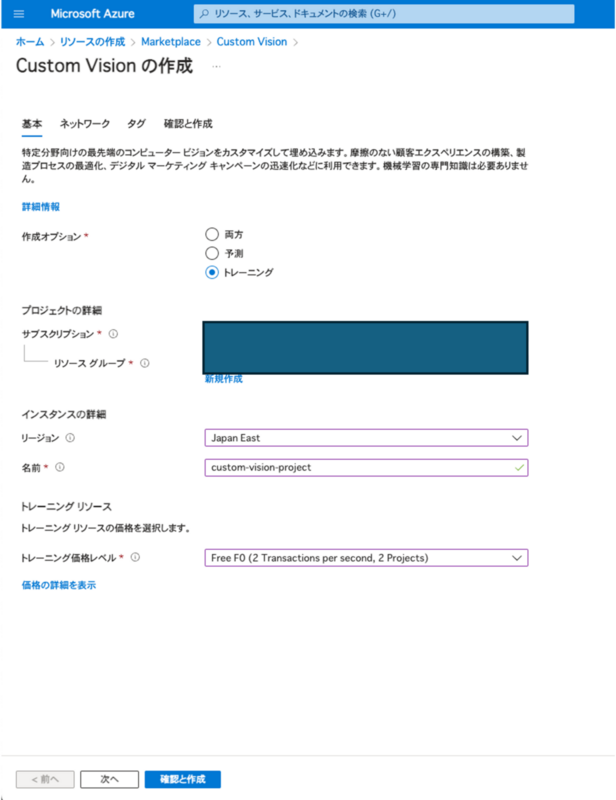
ソースコード中のterraformを用いてクラウドリソースのデプロイが可能です。 一方でCustom Visionについては、Microsoftの「AIの責任ある使用」に関するポリシーに同意する必要があるためAzure Portalで行います。 MarketPlaceよりCustom Visionを選択し、「作成オプション」を「トレーニング」にしてリソースを作成します。 モデルをエクスポートせずに、学習済みモデルをREST APIとして実行する場合は「両方」を選択してください。 トレーニングの価格レベルは要件に合わせて選択しますが、PoC段階ということで「Free F0」を選択します。
MLワークフロー
本記事ではソースコードのMLワークフローおよびAzure Custom Visionについて説明します。
学習データの準備
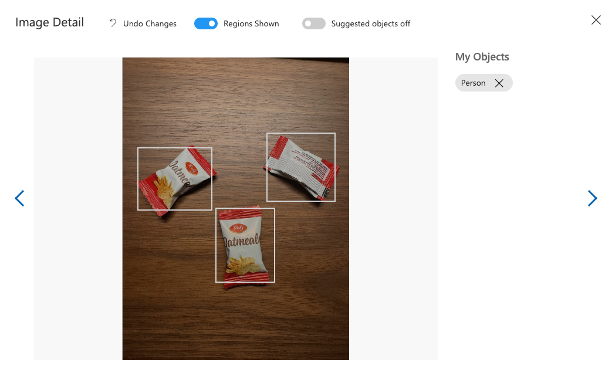
人物検知に向けた学習データの作成にあたり、ここでは商用可能なものを選定または作成する必要があります。 しかし、このデータセットの用意は本記事のシステム構築の趣旨から外れるため、検証用としてお菓子袋の検出を考えます。 ここで用意した画像に、以下のような検出用のバウンディングボックスを設定し、それらの情報を保存します。 ここまでの準備をシステム構築前に行います。

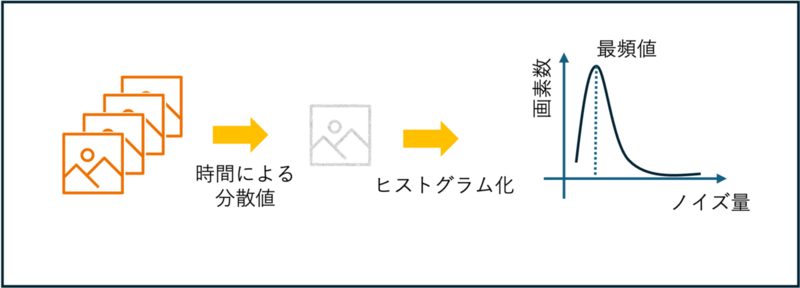
再学習時には、この学習データにガウシアンノイズを付与します。 ガウシアンノイズの分散値には、被写体の時間変化が少ない期間に撮影された複数枚の画像から、画素ごとに分散値を算出し、全画素の最頻値を採用します。 これにより、被写体が一定であるときのランダムノイズの代表値を近似的に取得します。
(*) この方法では信号量に依存したノイズ量を正しく見積もることができません。より精度を求める場合は改善の余地があります。
モデル学習
Custom VisionをPython向けのSDK越しに用いて、学習データをアップロードします。 モデル学習のタスクをキューに追加し、一定期間待機することで学習が終了します。 以下はソースコードの一部を抜粋し、コメントを加えたものです。
from azure.cognitiveservices.vision.customvision.training import (
CustomVisionTrainingClient,
)
from azure.cognitiveservices.vision.customvision.training.models import (
Region,
ImageFileCreateEntry,
ImageFileCreateBatch,
)
from msrest.authentication import ApiKeyCredentials
``` 省略 ```
credentials = ApiKeyCredentials(in_headers={"Training-key": TRAINING_KEY})
trainer = CustomVisionTrainingClient(ENDPOINT, credentials)
# ドメインの作設定
# エッジデバイスへのデプロイを見越して`compact`を選定
# `compact`を選定しない場合はWebAPI越しの実行しかできない
obj_detection_domain = next(
domain
for domain in trainer.get_domains()
if domain.type == "ObjectDetection" and domain.name == "General (compact)"
)
# プロジェクトを作成
project = trainer.create_project(
"People Counting Project",
domain_id=obj_detection_domain.id,
)
# タグの作成
person_tag = trainer.create_tag(project.id, "Person")
# アップロード画像のリスト化
# 上で保存した情報(ファイル名とバウディングボックス)が"json_data"に格納
tagged_images_with_regions = []
for data in json_data:
image_file = data['fileName']
tags = data["tags"]
regions = [
Region(
tag_id=person_tag.id,
left=tag["left"],
top=tag["top"],
width=tag["width"],
height=tag["height"],
)
for tag in tags
]
with open(image_file, "rb") as image_contents
tagged_images_with_regions.append(
ImageFileCreateEntry(
name=image_file,
contents=image_contents.read(),
regions=regions,
)
)
# ファイル群のアップデート
trainer.create_images_from_files(
project.id, ImageFileCreateBatch(images=tagged_images_with_regions)
)
# 学習タスクをキューに入れる(ここでは1イテレーションのみ)
iteration = trainer.train_project(project.id)
プロジェクトの作成とファイル群のアップデートに成功すると、Custom Visionポータルからアップロードされたファイルとタグ情報を確認できます。 また、Custom Visionポータルからも画像のアップロードとタグ付けが可能です。
学習の確認
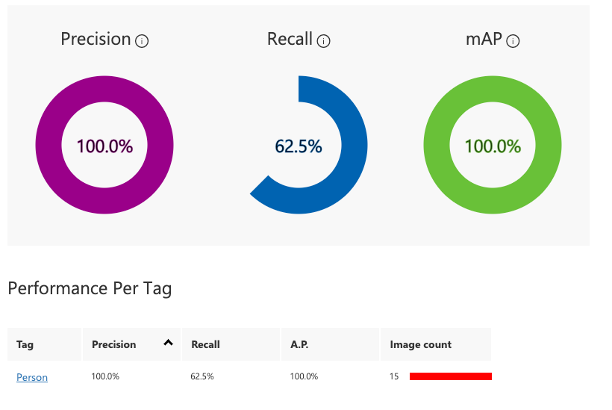
トレーニング終了後に、学習にデータにおける精度、再現率、平均精度を確認できます。 これにより、学習が成功したかを確認できます。 この内容はCustom VisionポータルのPerformanceタブからも確認可能です。
# interation.status == "Completed" で学習終了
iteration_id = iterations[0].id # 最新のイテレーション
iteration_performance = trainer.get_iteration_performance(
project_id, iteration_id
)
# パフォーマンス指標の表示
print("Precision: {:.2f}".format(iteration_performance.precision))
print("Recall: {:.2f}".format(iteration_performance.recall))
print("Average Precision: {:.2f}".format(iteration_performance.average_precision))
モデルデプロイおよび実行
SDKよりモデルURLを取得し、ダウンロードできます。 ダウンロードされたzipファイルには、実行用のPythonソースコードとモデルデータ("*.onnx")が含まれます。 本記事のシステムでは、このモデルデータをBlobストレージに置き、ソースコードはAzure Functionにデプロイします。
# モデルのエクスポート
export = trainer.export_iteration(project_id, iteration_id, "ONNX")
while export.status != "Done":
export = trainer.get_export(project_id, iteration_id, export.id)
time.sleep(10)
# URLの取得とダウンロード
model_url = export.download_uri
export_file = requests.get(model_url)
with open("export.zip", "wb") as file:
file.write(export_file.content)
実際にコードを実行すると以下のように出力され、検出物のリストが出力されます。 このリスト長を人流データとして記録します。
$ python python/onnxruntime_predict.py test_001.png
[
{'probability': 0.96306247, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.6113374, 'top': 0.1495378, 'width': 0.23059763, 'height': 0.18790943}},
{'probability': 0.93494284, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.31712056, 'top': 0.43989411, 'width': 0.28013505, 'height': 0.18385402}},
{'probability': 0.86241835, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.18591469, 'top': 0.15347767, 'width': 0.22360932, 'height': 0.20324681}},
{'probability': 0.86202902, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.38832647, 'top': 0.13814446, 'width': 0.25019577, 'height': 0.22316483}},
{'probability': 0.83257216, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.04233004, 'top': 0.41069869, 'width': 0.17654971, 'height': 0.19467201}},
{'probability': 0.78080565, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.58802276, 'top': 0.39514219, 'width': 0.20800796, 'height': 0.2052871}},
{'probability': 0.66069514, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.72162047, 'top': 0.49268371, 'width': 0.24379058, 'height': 0.19499978}},
{'probability': 0.39772633, 'tagId': 0, 'tagName': 'Person', 'boundingBox': {'left': 0.18672522, 'top': 0.35396666, 'width': 0.23256654, 'height': 0.19639073}}
]
今後の展望
ブログの趣旨としてCustom Visionを用いたシステム構築のPoCに終始してきました。 その他の構成については、上で紹介したソースコードにて公開しています。
現状は学習パイプラインの起動をスケジュール実行しており、 学習データやカメラ台数の増加により計算リソース面で破綻することが想定されます。 「MLOpsレベル1:MLパイプラインの自動化」を実現するにあたり、モデル認識精度を監視し、 効率的な学習のパイプラインのトリガー策定が不可欠です。
また、実用化や精度向上にむけて、学習データの拡充やエッジ処理によるスループットやプライバシーリスクの改善を検討したいと考えています。
まとめ
Azure Custom Visionを用いて、簡易的なMLフローを構築しました。 このサービス強みとして、既存の学習モデルに無いドメインや実用上の課題を解決した画像識別モデルを、容易に生成できることにあると思います。 ただし、今後ChatGPT4 with VisionなどのLLMによるプロンプトエンジニアリングで解決できるようになる可能性があり、このようなサービスはLLMや生成形AIがリーチしにくいエッジ領域にシフトしていくかと思います。 今後の発展を注視しつつ、Insight Edgeでは現状でベストな選択をしていきたいと思います。