こんにちは!Lead Engineerの筒井です。
このテックブログでも何度かテーマに上がっていますが、住友商事グループでは生成AI活用の取り組みが進んでおり、Insight Edgeもその推進を技術面から強く支援しています。 様々な取り組みがありますが、LLMの使われ方として基本的にはRAGを用いて回答を行うような、単発の特定タスクを解くというものが多いです。 今後はLLMに様々なツールを与えておき、より多様なタスクを状況に応じて自律的にこなしてもらうような、エージェント的な利用も模索していきたいと考えています。 そこで、今回は簡単な自律型のエージェントを、Prompt flowとFunction callingを用いて作成してみました。
もくじ
Prompt flowについて
Prompt flowは、Microsoftによりメンテナンスされている、LLMアプリケーション開発のためのOSSです。 詳細は割愛しますが、特にAzure AI Studioとの統合により、LLMアプリケーションのライフサイクルにおける開発の効率化や、評価・改善を継続的に行うための基盤として利用ができるというところに強みを持っています。LLMアプリケーションの評価については、最終の出力のみでなく、例えばRAGであればユーザー入力から生成した検索フレーズ、検索結果から得られた参照ドキュメントなど、中間出力についても精度を検証していくことが重要となります。Prompt flowでは各処理をノードとして扱い、各ノードの出力を評価対象とすることができるため、処理ごとの評価・改善を効率的に実施することができます。
自律型エージェントの概要
今回作成する自律型エージェントには、以下のようなタスクを行わせたいと思います。
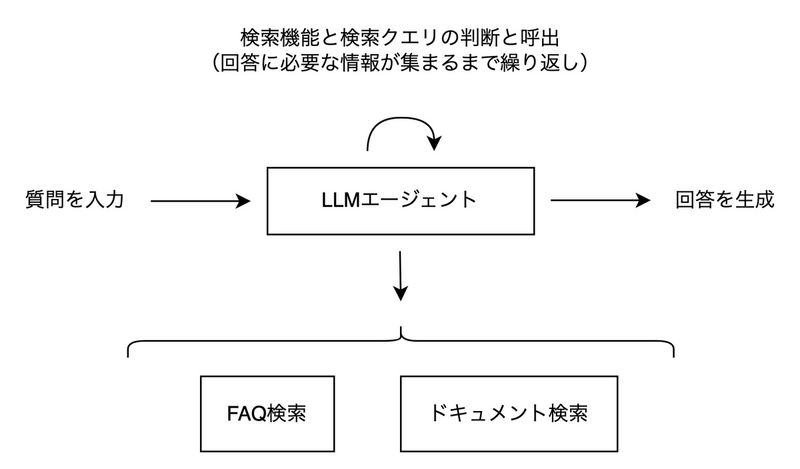
すでに用意されたFAQから答えられるものはそのFAQをベースに回答を返し、それ以外の質問についてはドキュメントから回答に合う部分を探して回答を返す、RAGをベースとした構成です。 RAGの実現方法は様々あると思いますが、ここではいずれもベクトル検索を用いて回答を返すこととします。
さて、これをPrompt flowでどのように構成するかですが、この構成は考えてみると不定な長さの繰り返し処理を含んでいます。 一方、Prompt flowはDAG(有向非巡回グラフ)でフローを構成する仕組みのため、繰り返し処理を含むフローを表現することができません(NodeCircularDependencyエラーが発生します)。 Pythonコードで書くならば、while文を使って繰り返し処理を行うことができますが、その場合は単一ノードで全ての処理を行うことになってしまい、上述したようなPrompt flowのメリットを活かすことができません。
というわけで結論としては今回取ろうとしているような自律型エージェントの構成をPrompt flowで実現するのは向いていないということになるのですが、 それでブログ記事が終わるとちょっと寂しいので、固定超の繰り返し処理を含むフローでやれるところまでやってみようと思います。
構成を以下のように変更します。 また、具体的に扱うデータとして、個人情報保護法のQ&Aとガイドラインを利用します。
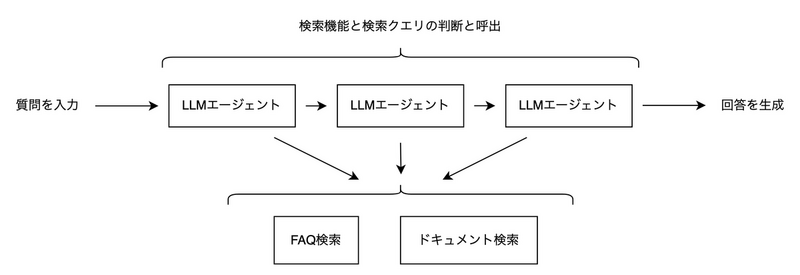
Prompt flowによる自律型エージェントの作成
この構成をPrompt flowで以下のように作成しました。 せっかくなので、LLMの呼び出しにはLLMノードを使っています。 今回はベクトルDBとしてAI Searchを利用しているため、ベクトル検索もIndex Lookupノードを利用できるのですが、そもそも向いていない処理を無理やりやらせていることもあり、フローが複雑になりすぎるので、今回はPythonコード中で処理をしています。
また、Prompt flowでは同じコード(pyファイル)やプロンプト(jinja2ファイル)を複数のノードに割り当てることができるので、同じ処理を繰り返し実行するという元の構成の意図を残し、各ノードに個別の実装をするのではなく共通の実装を各ノードに割り当てるようにしています。

format_inputノードの処理
format_inputは、各ステップをまたいで状態を維持するためのオプジェクトデータを作成する処理です。 各ステップで適切な処理を行うことができるように、以下の状態を持つようにします。
- finished
- 回答の生成が完了したかどうか。元の構成では回答が終了した場合にループを抜けますが、Prompt flowではそのような処理ができないため、各ノードでの処理をスキップするために使用します
- query
- ユーザーからの質問文
- function_results
- 各ステップで実行したFunction callingの結果。使った関数の名前と引数、戻り値をリストにして保持します
agentノードの処理
agentは3つのノードがありますが、先述の通りすべて同じプロンプト設定を持っており、上述の finished の値が True の場合は処理をスキップするように設定しています。
具体的なプロンプトは以下の通りです。ここで、 input は先述の状態オブジェクトです。
# system: Function callは必要に応じて利用してください。 あなたは個人情報保護法に関する質問に回答するアシスタントです。事前に用意されたQ&A資料やガイドライン資料を参照して、ユーザーからの質問に回答してください。 Q&A資料を参照して回答の根拠が見つからなかった場合、ガイドライン資料を参照してください。 回答を述べる際は、その根拠となる資料中の文章を引用して回答に含めてください。 {% for result in input.function_results %} # assistant: Function generation requested, function = {{result.name}}, args = {{result.arguments}} # function: ## name: {{result.name}} ## content: {{result.content}} {% endfor %} # user: {{input.query}}
プロンプトの記載方法は、こちら1を参考にしました。
# system や # assistant などはそれぞれOpenAIのAPI呼び出し時に、roleに変換されるようです。2
執筆時点でサポート済みの記載が見つけられませんでしたが、 # function 内も特定の書き方をしないとエラーになるため、変換に対応しているようです。
各ノードには別途Function calling用の関数が指定してあり、内容は次のfunctionsノードの処理で説明します。
functionノードの処理
こちらも先述の通り3箇所すべてに同じ関数定義がされています。 agentノードがFunction callingを選択した場合はその処理を行い、agentノードが回答の出力を選択した場合はそれをそのまま次の処理に流します。 内部で呼び出しているsearch関数は質問のベクトル化とAI Searchでのベクトル検索を実行する関数ですが、ほぼ公式ドキュメントのSDKサンプル3を参考にしているので、ここでは省略します。 また、Function calling部分の実装はこちら[^1]を参考にしています。
def qanda_search(query): return search("qanda", query) def guideline_search(query): return search("guideline", query) @tool def run_function(inputs: dict, agent_message: dict) -> dict: # 直前のagentノードが実行されていない=すでに回答生成済みの場合 # 現在の回答をそのまま格納する if agent_message is None: return { "finished": True, "content": inputs["content"] } # 直前のagentノードが実行され、回答が生成された場合 # 状態を回答済みとし、生成した回答を格納する if agent_message["function_call"] is None: return { "finished": True, "content": agent_message.get("content", "") } # 直前のagentノードが実行され、Function callingが呼び出された場合 # 指定された関数を実行し、実行結果をリストの末尾に追加する function_call = agent_message.get("function_call", None) function_name = function_call["name"] function_args = json.loads(function_call["arguments"]) result = globals()[function_name](**function_args) function_results = inputs["function_results"] + [{ "name": function_name, "arguments": function_args, "content": [result] }] return { "finished": False, "query": inputs["query"], "function_results": function_results }
agentノードでのFunction callingの設定は以下のようにしました。 Q&A資料が質問にうまくマッチする場合はその方が精度が高いというユースケースを想定し、先に参照するように指示しています。
[ { "name": "qanda_search", "description": "Q&A資料を参照する時に利用します。すでに一度呼び出している場合は呼び出さないでください。検索用のクエリを指定して検索をします。", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "検索用のクエリ。基本的にはユーザーの質問そのものを使いますが、必要に応じてタイポの修正やベクトル類似度による検索に適した形への修正をしても構いません" } }, "required": [ "query" ] } }, { "name": "guideline_search", "description": "ガイドライン資料を参照するときに利用します。Q&A資料を参照して適切な回答がない場合はこちらを呼び出してください。検索用のクエリを指定して検索をします。", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "検索用のクエリ。基本的にはユーザーの質問そのものを使いますが、必要に応じてタイポの修正やベクトル類似度による検索に適した形への修正をしても構いません" } }, "required": [ "query" ] } } ]
作成したフローの実行
今回作成したベクトルDBには、個人情報保護委員会が公開している個人情報保護法のQ&Aと、個人情報保護法のガイドラインが登録されています。4 ガイドラインについては、「個人情報の保護に関する法律についてのガイドライン(通則編)」のPDFのみを利用し、Q&Aについては、同じく「ガイドライン(通則編)」に対応するQ&Aのうち、一部のみを登録しました。そうすることで、未登録の質問についてはQ&Aのみだと回答が見つからない状態にしています。
フローを実行すると、以下のような結果が得られました。まずは、Q&Aに存在するのと同じ質問を入力した場合です。 先に参照したQ&Aの内容で回答可能と判断してガイドラインの参照をスキップし、Q&Aの内容を引用して回答を返しています。

次に、Q&Aのみでは見つからない質問をしてみます。先に参照したQ&Aの内容では回答が見つからないため、さらにガイドラインも参照して回答を返しています。
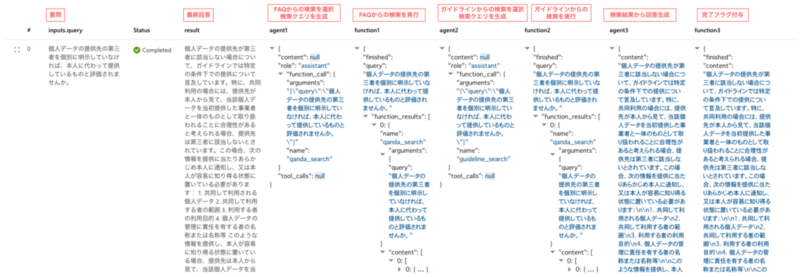
今回作成したフローでは、プロンプトを含むRAGの精度については十分に精査していないため、必ずしもこれらのように適切な動作をするわけではないものの、少なくとも想定したような動作ができることは確認できました。
フローの評価方法についてはここでは詳細を割愛しますが、上記の通り各ノードごとに個別の入力と出力を取得できるため、単にユーザーの質問と最終出力のみでなく、各ステップごとの処理まで深掘りして評価することができます。 また、Azure AI Studio上でバルク実行をすることで、複数の質問に対して一括で回答を生成し、まとめて評価を行うことも可能です。
まとめ
今回はPrompt flowを使って、固定長の処理を行う自律型エージェントを作成してみました。 Prompt flowは事前に定義されたノードやツール、Azure AI Studioとの統合による評価の容易さなど、様々なメリットがある一方で、繰り返し処理が必要となる自律型のエージェントの作成には向いていなさそうです。 既にクローズされたIssue5にも言及がある通り、DAGという性質上の難しさはあると思いますが、なんらかの機能サポートに期待しつつ、他の方法での実現も模索していきたいと思います。