こんにちは! 分析チームの梶原(悠)です。今回はクラス間不均衡問題について議論します。
目次
クラス間不均衡問題とは
実務で扱われる多くの分類問題はクラス間のサイズに偏りがあります。 いくつかのクラスのデータが他のクラスよりも著しく多いとき、分類器は小さなクラスを無視しやすくなります。 これは、クラス間不均衡問題と呼ばれます。
問題の定式化にまつわる議論
クラス間不均衡問題は、「分類問題の構造の複雑さ」「訓練データの大きさ」「クラス間のサイズの偏り」などの条件が絡みあって起きます [1]。
一方で、Lingらは、学習器が正解率(accuracy)の最大化を目標として訓練される分類タスクの設定自体に問題があると指摘しています [2]。 そして不均衡問題には、ビジネスコストを考慮した学習で効果的に対処できると主張しています。また、訓練データが小さいことの悪影響は、不均衡とは別の問題であるとする立場をとっています。
本稿では「クラス間不均衡問題への対処にあたって、ビジネスコストを正確に考慮する必要があるか?」という論点を実務寄りの観点から検討してみます。
比較シミュレーションの設定
実務上は、ビジネスインパクトに強く影響する要因が重要で、影響しない要因は無視できます。 今回は、きわめて単純化された仮想企業の損益を、乱数実験によりシミュレートし、クラス間不均衡問題への対処手法のビジネスインパクトを比較してみます。
仮想企業Y社のビジネス設定.
仮想企業Y社は、農作物の種子を売り掛け販売し、一定の支払猶予期間ののち、代金を回収するビジネスを営んでいます。 Y社は、種子のメーカーZ社から単価95円で種子を調達し、顧客企業に単価120円で販売します。 顧客企業Z社は、購入した種子から花を育てて花市場で販売し、得られた売上からY社に代金の支払いを行います。 顧客企業Z社は、花の不作や価格下落により資金繰りができなくなるとY社に代金を支払うことなく倒産します。 仮想企業Y社は、1,000社の顧客企業のそれぞれと月に数回の頻度で取引をします。倒産による貸し倒れの割合は1%です。
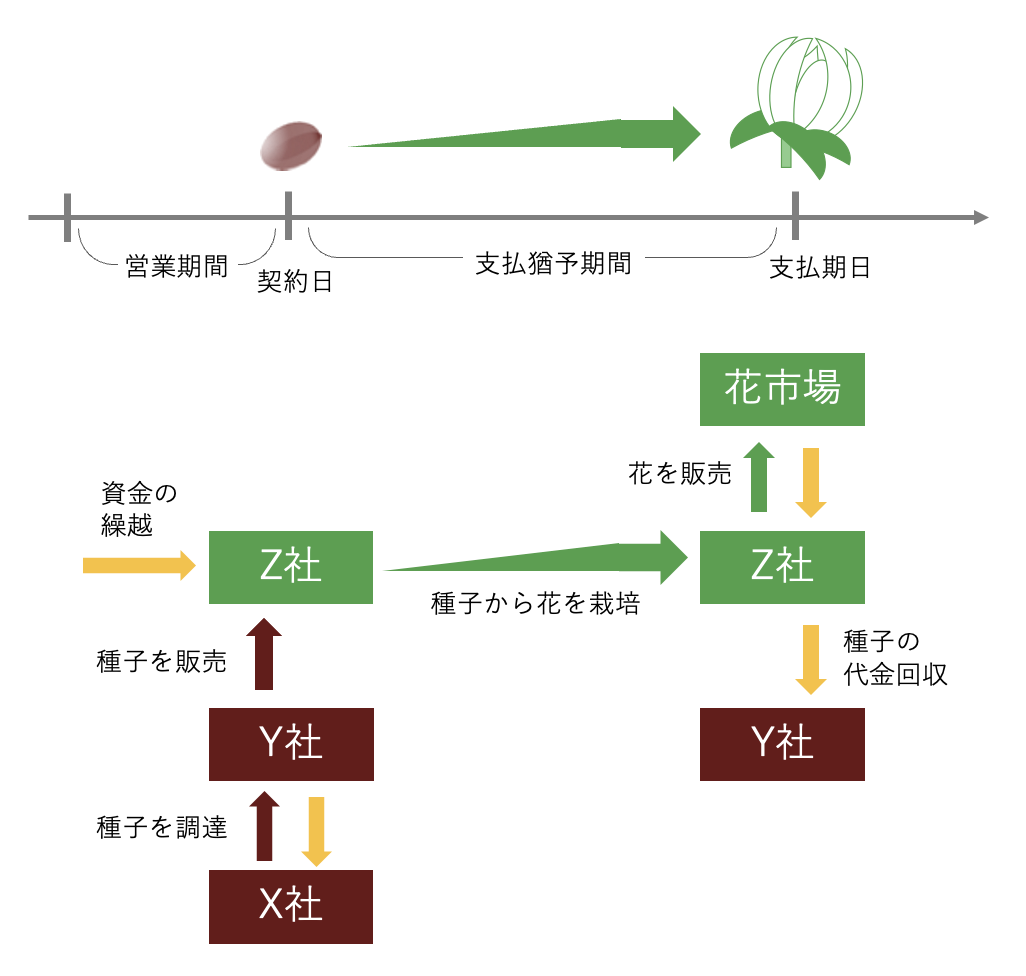
ダミーデータの生成.
乱数シミュレーションにより、上記設定のY社と顧客企業との契約データを生成しました。
ビジネスインパクトの評価.
契約時点のデータから倒産による貸し倒れを予測するモデルを構築します。 倒産が予測される場合は、業務に介入し、契約を未然に取り止めます。 介入しない場合と比較した貸し倒れや機会損失の影響を考慮すると、種子1個あたりのビジネスコストは以下になります。
| 実績="継続" | 実績="倒産" | |
|---|---|---|
| 予測="継続" | 0円 | 0円 |
| 予測="倒産" | +(120-95)円 | -95円 |
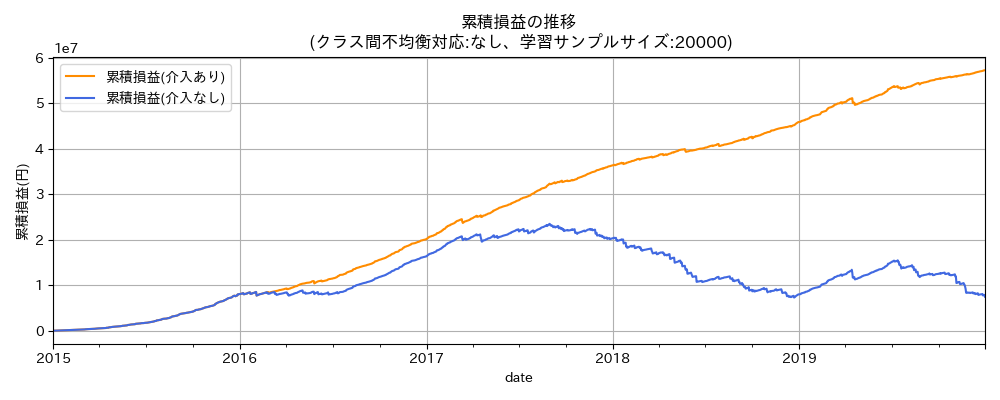
このコストを累積したものは、介入あり・なしの累積損益の差に一致します。 これを介入のビジネスインパクト(pl_impact)とします。
不均衡対応の手法
倒産の予測モデルはすべてlightGBMで作成し、不均衡対応は以下の5手法を比較しました。なお、説明変数は、「種子の個数」「支払い猶予期間」「花の市場価格」の3つのみを用います。
- クラス間不均衡に対処しない. (NAIVE)
- モデルの出力した倒産確率をビジネスインパクトが最大になる閾値で切る. (OPTIMIZED_THRESHOLD)
- サンプルの重みによるコスト考慮学習で対処する. (COST_SENSITIVE_LEARNING) [4]
- SMOTE (Synthetic Minority Oversampling Technique)で前処理する. (SMOTE) [5]
- 損失関数をFocal lossにする. (FOCAL_LOSS) [6]
学習・検証データ分割
学習データは顧客企業500社との契約データからランダムサンプリングし、 検証データは残り500社の顧客企業との契約データの全量とします。
比較シミュレーションの結果
不均衡問題の確認.
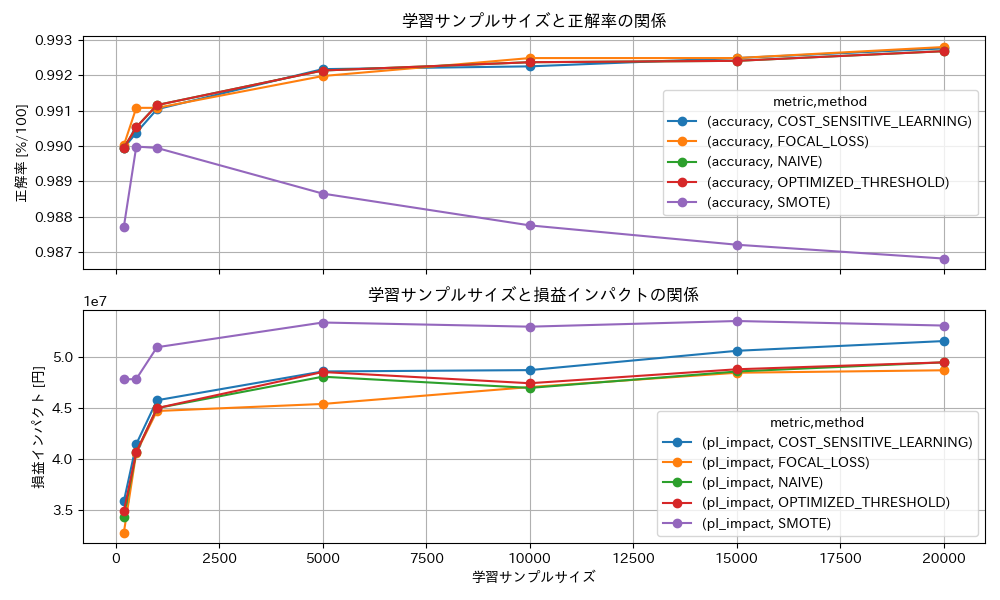
不均衡に対処しないモデル(NAIVE)による予測の精度を確認します。今回のデータとモデルはかなり構造が単純ですが、不均衡の悪影響が見られます。また、学習データが小さくなると、不均衡問題の悪影響も強まっています。(各値は、学習における乱数シードを変えた20回の試行の中央値。)
| 学習サンプルサイズ | 倒産確率 (実績値) |
倒産確率 (推定値) |
MCC | 正解率 (Accuracy) |
再現率 (Recall) |
Cohen's kappa | AUC | Brier score |
|---|---|---|---|---|---|---|---|---|
| 500 個 | 0.014 | 0.011 | 0.620 | 0.991 | 0.556 | 0.604 | 0.775 | 0.0088 |
| 20,000 個 | 0.014 | 0.011 | 0.715 | 0.993 | 0.649 | 0.712 | 0.823 | 0.0060 |
手法のビジネスインパクトの比較
ビジネスインパクトの比較では、ビジネス構造の知識を持たないSMOTEが、コスト考慮学習よりも良い結果となりました。この事例の不均衡データでは、タスクの定式化にビジネス構造を取り込むことよりも、訓練データが小さいことへの対処の方が、実務上重要であると考えられます。(各値は、学習における乱数シードを変えた20回の試行の中央値。)
考察
今回はダミーデータが小さすぎて確認できませんでしたが、訓練データのサイズを大きくしていけば、漸近的には、どの手法のビジネスインパクトも同じになると期待されます。すなわち、漸近的にはビジネス構造の知識を持つ手法と持たない手法は同等になるはずです。
一方、訓練データのサイズが小さい非漸近的な領域では、ビジネス構造の知識を持たないSMOTEの方が、コスト考慮学習より大きなビジネスインパクトを持つ現象が確認できました。この事例においては、不均衡問題の本質が、分類タスクの定式化におけるビジネス構造の不在ではなく、マイナークラスの少数データ問題側にあることを示唆すると思われます。
だとすると、コスト考慮学習による方向を追求しても、実務上の意味のある形で不均衡問題への視座を得ることはできないのではないか、という疑いを覚えます。Jamalらはクラスの均衡化をドメイン適応の問題として捉える視点を紹介しています [3]。クラス不均衡問題の正しい定式化は、あるいは、こうした方向にロバスト性が加えられたようなものかもしれないと想像します。
[1] Japkowicz, N., & Stephen, S. (2002). The class imbalance problem: A systematic study. Intelligent data analysis, 6(5), 429-449.
[2] Ling, C. X., & Sheng, V. S. (2008). Cost-sensitive learning and the class imbalance problem.
[3] Jamal, M. A., Brown, M., Yang, M. H., Wang, L., & Gong, B. (2020). Rethinking class-balanced methods for long-tailed visual recognition from a domain adaptation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7610-7619).
[4] Elkan, C. (2001, August). The foundations of cost-sensitive learning. In International joint conference on artificial intelligence (Vol. 17, No. 1, pp. 973-978). Lawrence Erlbaum Associates Ltd
[5] Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357.
[6] Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988).