はじめに
こんにちは。Insight Edge, Data Scientistのnakanoです。
これまで機械学習モデルを使用する際は、データの前処理、特徴量エンジニアリング、モデルの選択、 ハイパーパラメータの調整といった複雑な手順を専門知識を持つデータサイエンティストが手作業で行う必要がありました。 しかし最近は、クラウドベンダーが提供しているAutoMLサービスの認知度も上がり、 サービスに料金を支払うことでモデル構築プロセスを自動化することが身近になりつつあります。 そのため、技術者として機械学習モデルを構築する業務はだいぶ楽になってきた一方で、 サービスへの課金額を考慮しなければならなくなりました。
私自身、Vertex Forecast(Google Cloudが提供する時系列予測向けのAutoMLサービス)を使う際にどれだけ課金すれば良いのか迷った経験があります。 そこで今回は、その経験を元にVertex Forecastの課金額の決定方法やノウハウを説明します。
Vertex Forecastとは
Vertex Forecastとは、Google Cloudが提供している時系列データ向けのAutoMLサービスです。 2021年5月にプレビュー版が公開され、2022年6月にGA版が公開されました。 AWSのAmazon Forecastが2019年8月にGA版が公開されていることを考えると、比較的新しいサービスといえます。 Amazon Forecastに比べて設定できるパラメータが少ないこともあり、非技術者でも使いやすく作られたサービスと感じます。
Vertex Forecastの料金体系
まずVertex Forecastの料金体系を紹介します。 Vertex Forecastでは、学習と予測の2つのプロセスがあり学習は時間単位、 予測はデータポイント数(予測する値の数)に応じて課金されます。
- 学習(Training)
- トレーニング時間1時間分あたり、$21.25
- 予測(Prediction)
- 予測値1000個あたり、$0.20 (0-1M points)
- 予測値1000個あたり、$0.10 (1M-50M points)
- 予測値1000個あたり、$0.02 (>50M points)
- 引用:Vertex AI pricing,Vertex AI Forecast
ケース:1000店舗の1週間後までの客数予測モデル
具体的なケースで費用を計算してみます。 たとえば1000店舗を運営しているレストランチェーン店のデータサイエンティストとして勤務していたとし、 店舗から仕込みや発注の都合で直近1週間の客数予測を毎週1回把握したいと要望があったとします。 またデータサイエンティストの事前の分析結果から、 客数予測モデルは毎月1回 (ここでは仮に)10時間分のコストをかけて再トレーニング させる必要があるとします。
この場合の費用は以下のとおり、$218.1/月と見積もれます。
- 学習(Training)費用
- $21.25/時間 * 10時間 * 1回/月 = $212.5/月
- 予測(Prediction)費用
- $0.2/1000 * 1000店舗 * 7日/週 * 4週/月 = $5.6/月
トレーニング時間の課題
上記のレストランチェーン店のケースでは、 トレーニング時間を仮に10時間分と設定しましたが、実際はどのように決めればよいのでしょうか? 使用するモデルが既に決定している場合は、学習用データと検証用データの損失関数を参照することでトレーニングが十分であるかどうかを確認できます。 しかし、Vertex Forecastでは損失関数を確認できません。 他のVertex Forecastユーザーもこの点について言及されていたので、学習の進捗がわからない点はユーザーならば認識している課題のようです。 (ML: Vertex AI Forecast AutoML ではじめる需要予測)
そのため、トレーニング時間決定にノウハウが必要となります。
トレーニング時間の決定方法
トレーニング時間の目安
まずトレーニング時間の参考値として、公式ドキュメントの表を紹介します。 この表では、行数、特徴量数、予測ホライズン(予測期間の長さ)によってトレーニング時間の目安が記載されています。 留意点として、この表の値はあくまで目安であり、コンテキストウィンドウ(入力期間の長さ)や特徴量の内容によっても必要なトレーニング時間は変わってきます。
コンテキストウィンドウ(入力期間の長さ)は、ユーザーが学習時に設定する値です。 大きいほど、モデルの精度が向上しますが、トレーニング時間も増加します。 ではコンテキストウィンドウは、どのように設定すればよいのでしょうか?
| 行数 | 特徴量の数 | 予測ホライズン(予測期間の長さ) | トレーニング時間 |
|---|---|---|---|
| 1,200 万 | 10 | 6 | 3~6 時間 |
| 2,000 万 | 50 | 13 | 6~12 時間 |
| 1,600 万 | 30 | 365 | 24~48 時間 |
予測ホライズン、コンテキストウィンドウとは
- 予測ホライズンとは、モデルがどれくらい先まで予測するかを設定する値です。日ごとの時系列データで1週間先まで予測する場合は7となります。
- コンテキストウィンドウとは、モデルがどれくらいの期間を遡ってデータを参照して予測するかを設定する値です。予測に直近4週間の値を入力する場合は、28となります。
コンテキストウィンドウの目安
次に、コンテキストウィンドウの決定方法についてまとめます。 公式ドキュメントに記載された手順をフローチャートにまとめました。 ざっくりとしたプロセスですが、精度に満足するまでコンテキストウィンドウを増やしていくというものです。 このとき、コンテキストウィンドウの増加とともにトレーニング時間も比例的に増やす必要があります。
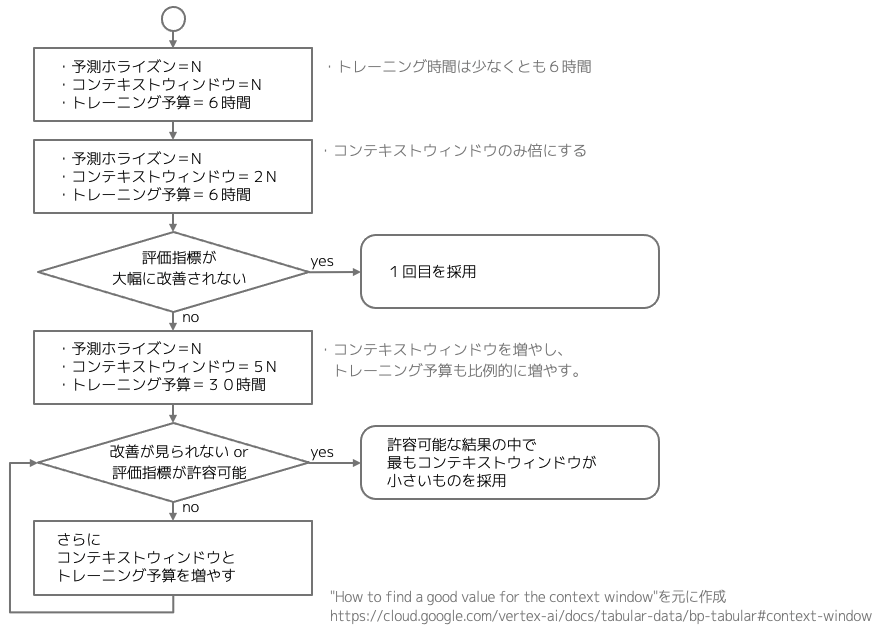
私見
ここまで公式ドキュメントで紹介されているトレーニング時間とコンテキストウィンドウの決定方法について説明しました。 私自身の経験と所感、結論をまとめます。
経験
以前、以下のケースで時系列データ予測をVertex Forecastで検証しました。
- 特徴量:4個(タイムスタンプ列(日付):1個、カテゴリ変数列2個、ターゲット変数列1個)
- タイムスタンプ列とターゲット変数列以外の特徴量が2件しか無いのは、トレーニング時間を抑えるため最低限の特徴量だけを特に前処理せずに入れたためです。
- コンテキストウィンドウ:50
- 予測ホライズン:10
- 行数:約100万行(時系列識別子1000件、データポイント1000件)
このケースでは、12時間のトレーニング時間まで精度が向上しました。 公式ドキュメントのトレーニング時間の目安と比べて、これはやや長めの時間を必要としました。 標準的なトレーニング時間よりも多くの時間を必要とした要因としては、 特徴量のうち2個は数10のカテゴリ数を持つカテゴリ変数だったことや、 今回のデータが特定の日や曜日でイベントを持つデータだったため日付列から作成できる特徴が多かったことなどが、 考えられます。
所感
AutoMLサービスというと、手元のデータをアップロードするだけで簡単にモデルが構築できるというイメージがありました。 実際に使ってみたところ、私のケースでは簡単に精度の高いモデルが作成できました。 一方で、使えそうなデータをやみくもにトレーニングさせるのは、コスト面で現実的ではありません。 精度に寄与しない特徴量を削除するなど、工夫は必要となります。
欲張って特徴量を増やしすぎず、また学習を一度で完結させようとするのではなく適切な課金を確保することが、AutoMLをうまく利用する上でのポイントだと感じました。
結論
最後に推奨方法と私見をあわせて、結論をまとめます。
- 課金額に余裕があるとき。
- 公式ドキュメントのベストプラクティスに沿って、コンテキストウィンドウと予測ホライズンは同じ値にして、トレーニング時間6時間から始め適切なコンテキストウィンドウを探す。
- 適切なコンテキストウィンドウが見つかったら、時間を増減させて、トレーニング時間を調整する。
- 課金額に余裕がないとき(ちょっと触ってみたいとき)
- 特徴量を減らす。(計算量を減らすため)
- コンテキストウィンドウと予測ホライズンは同じ値にする。(計算量を減らすため)
- トレーニング時間1時間と2時間でトレーニングさせる。(重要:節約のため最小単位の1時間分($21.25)だけ試してみたいところですが、2時間分も動かしておいて、精度の伸びしろを確認しておくことは重要だと考えています。)