こんにちは。ビジネスイノベーションスペシャリストの森です。
最近コードを書くときは、Github CopilotとGPT-4を使っていますが、実装スピードが10倍(体感)になりました。
微妙な部分を書き換えながら使うので、初心者がコーディングできるようになるのは難しいと思いますが、 コーディングの単純作業部分を全部任せられるのは非常に便利です。
こんなこともあり、Tech業界は最近生成AI一色です。Insight Edgeでも、数多くのChatGPT(LLM)活用プロジェクトに取り組んでいます。
この記事では、本格的なLLMのビジネス現場活用に向け、日々取り組んでいるテーマと、その技術的な課題を紹介します。
また、本記事のタイトル含め、LLMと記載すべきところをChatGPTという単語を使っている箇所があります。 OpenAI社のChatGPTというサービス名称ではなく、概念(一般名詞)としてChatGPTという言葉の使い方をしていることを予め補足します。
目次
はじめに
2023年3月のGPT-4リリース以降、ChatGPTをはじめとした大規模言語モデル(以降LLM)が注目されています。 Insight Edgeとしても、住友商事グループの生成AI活用に向けたグループ横断のワーキンググループであるSC-AI HUB に参画し、生成AIのビジネス活用に取り組んでいます。
企業や組織におけるLLMの活用では、いわゆる「セキュアなChatGPT」の取り組みが有名です。多くの企業や自治体が、Microsoft社のAzure OpenAI Serviceで提供されているエンタープライズ用途のChatGPTを用いたセキュアなChatGPTの導入を進めています。
一方、セキュアなChatGPT以外の大規模な本格導入例は、ほとんど出てきていません。 一時期話題となったAutoGPTなどエージェント機能を組み合わせるアイデアや、ChatGPT Pluginで色々なサービスを利用する機能もリリースされていますが、 現状、アーリーアダプターがX(旧:Twitter)で使い方を紹介するくらいで、大規模に実用されるまでは至っていません。
企業活動において最も期待されているユースケースとして、企業内のデータを組み合わせてLLMを使う用途があります。
RAG(Retrieval Augmented Generation) やREALM(Retrieval Augmented Language Model) などの論文で提案された手法を使って実現することが有名ですが、本記事では説明を割愛します。
Microsoft Azureでも、このユースケースを実現するためにAdd Your Data や、Cognitive Search のベクトルサーチ対応など、新しい機能を積極的にリリースしています。
しかしながら、企業内の情報検索のユースケースとして、ビジネス現場で活用されている例は、ほとんど出てきていません。 Insight EdgeもこのユースケースのPoCに数多く取り組んでいますが、ビジネス現場での実運用に向けては様々な課題に直面しています。
例えば、元データのPDFがスキャン画像だったり、テキスト化が難しいフローチャートや表に重要な情報が含まれていたりと、アルゴリズム以前に元データの整備が必要なケースがあります。
また、Stuffと呼ばれる最もシンプルな情報検索のパイプラインでは対応できない質問が業務上想定されるユースケースだったりもします。 後述しますが、与えた文書に対する要約と質問の両方を自然に回答することですら、割と難しかったりします。
現在リリースされているほとんどのサービスは、最もシンプルな情報検索のユースケースしか実装されていない状況です。 少し凝ったことをやろうとすると、Langchainやsemantic kernelを使って、スクラッチで実装する必要があります。
LLMを業務に活用する場合の課題
外部データの取り込み
ChatGPT PluginsのPopular Pluginsを見てみると、上位3件はPDFの取り込みプラグインです。 エンタープライズ用途同様に、ChatGPTに独自の情報を加えるユースケースは、一般的にも最も注目されているようです。
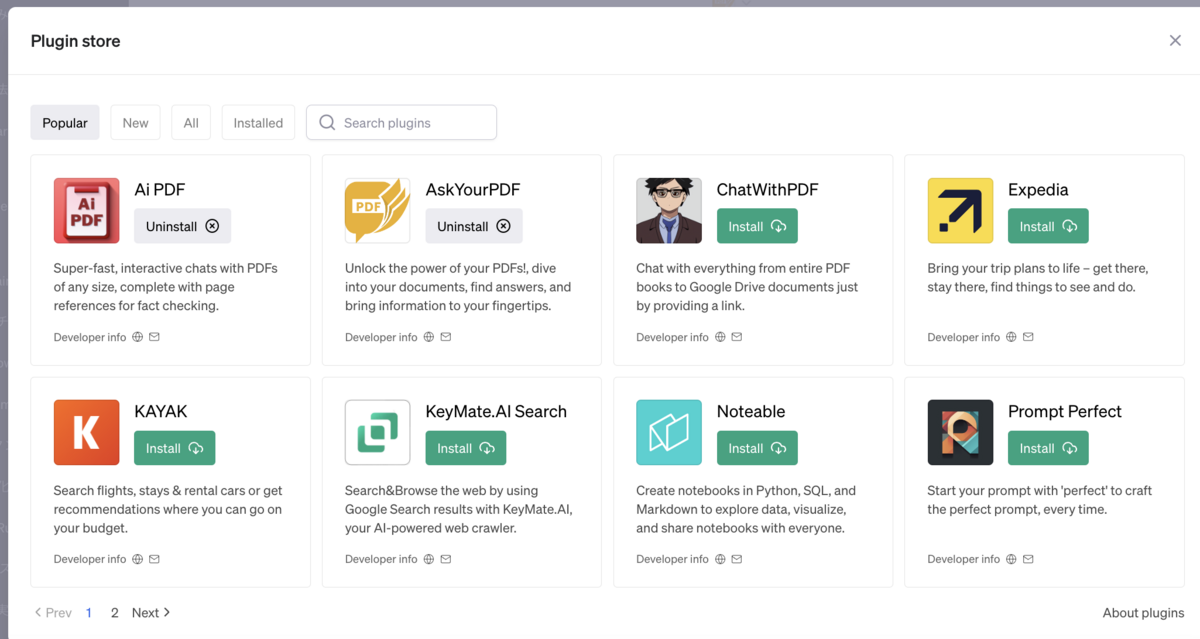
実際にPDFを取り込むプラグインを使って、課題を説明します。 Insight EdgeでPoCを実施する中で困っていることの1つが、ユーザーは文書に対する質問(情報検索)と要約を意図せずに利用することです。
OpenAIなど、LLMをクラウド型で提供するサービスでは、一度のリクエストで取り込めるトークン数(文字数)の制限があります。そのため、情報検索と要約は同じ処理では実現できません。
情報検索は、文書中の該当部分だけを抽出してChatGPTにプロンプトとして入力します。
要約は、全文を参照する必要がありますが、全文を一定文字数ごとに区切って、順番に入力して処理をしていきます。要約を実現する処理パイプラインとしては、Map Reduce型と、Refine型に大別されます(後述)。
つまり、ユーザーからのリクエストが情報検索か要約かによって、システム側で処理を切り替える必要がでてきます。
ChatGPTの人気プラグインが、この問題にどうやって対処しているのか確認してみましょう。
一番人気のプラグインである「AI PDF」を使って、全体で20ページほどの論文の要約を指示してみます。 ChatGPT Pluginでは、以下のように、APIにどのようなリクエストが飛んだかを確認できます。
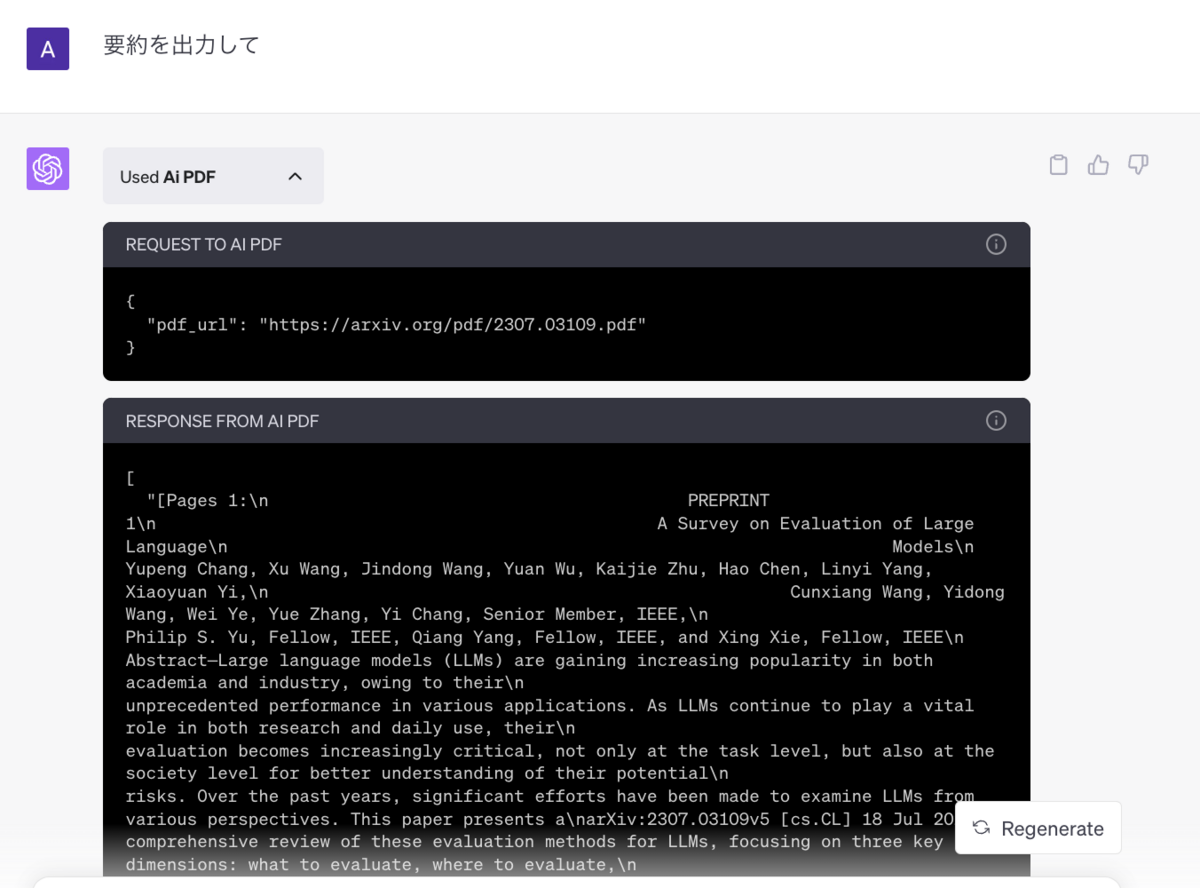
実際のリクエストを確認してみると、要約の指示をしたのにも関わらず、APIリクエストには文書の冒頭2ページ分しか入力されていませんでした。 幸い論文だと、冒頭にAbstractがあるため何となく良さそうな結果が返ってきますが、他のデータだとうまくいかなそうです。
実行結果の抜粋が以下になります。

やはり、明らかに冒頭2ページしか参照していません。つまり、このプラグインでは要約の処理は実装されておらず、要約の指示であっても質問回答用の処理しか実行されないことがわかりました。 人気のプラグインであっても、この程度のようです。まだまだこのユースケースの実用にはハードルがあることがわかります。
特に、冒頭2ページしか読み込んでいないのに、全文を処理しましたと出力する仕様となっているのは、ちょっといただけません。
補足ですが、Azureでは、Azure OpenAI Studio Add Your Dataというサービスでこのユースケースをサポートしています。 しかし、現状Azure OpenAI StudioのUI経由でしか利用できないため、システムに組み込みたい場合や、企業内ユーザーへの公開用途には使えません。
また、Bing Chat Enterprise では、 ユーザーがPDFデータをアップロードする機能が搭載されています。 上述したOpenAIのPlugin同様、まだ実用に課題はあるものの、ビジネス用途で利用できるサービスの一つです。
このBing Chat Enterpriseは、セキュアなChatGPT用途にも使用することができます。
冒頭記載した通り、多くの企業でセキュアなChatGPTの導入が進んでいます。 元々、ベンダーへの委託を含め自社で開発する選択肢しかありませんでしたが、今ではBing Chat Enterpriseのような外部サービスをそのまま利用する選択肢もあります。
住友商事では、セキュアなChatGPTをはじめ、シンプルなユースケースには外部のサービスを利用し、 業務に特化した複雑なユースケースをInsight Edgeを中心に開発する取組み方をしています。
出力形式の指定 (Function Calling)
ChatGPTを含むLLMからの回答を使って、別の処理を実施したい場合、プロンプトで回答形式を指定することが一般的です。 しかし、jsonなど決まったフォーマットで出力させようとしても、思ったように出力できないことが多いです。
体感ですが、GPT3.5を使った場合、上手く出力できる確率は良くて5割程度、GPT4だと8~9割です。 パラメータ数の少ないLLMでは、Finetuneしない場合、決まったフォーマットでの出力は絶望的です。
また、決まったフォーマットでの回答ニーズは、通常のチャット用途においても高まっています。 Chain-of-Thought Prompting や、メタ認知プロンプティング のように、LLMに段階的に推論をさせることで回答の精度を上げる手法が考案されています。
これらの手法は、以下の画像のように、LLMに対して思考の過程をプロンプトで定義します。 このように、段階的な思考の指示することで、回答の精度を向上・担保します。
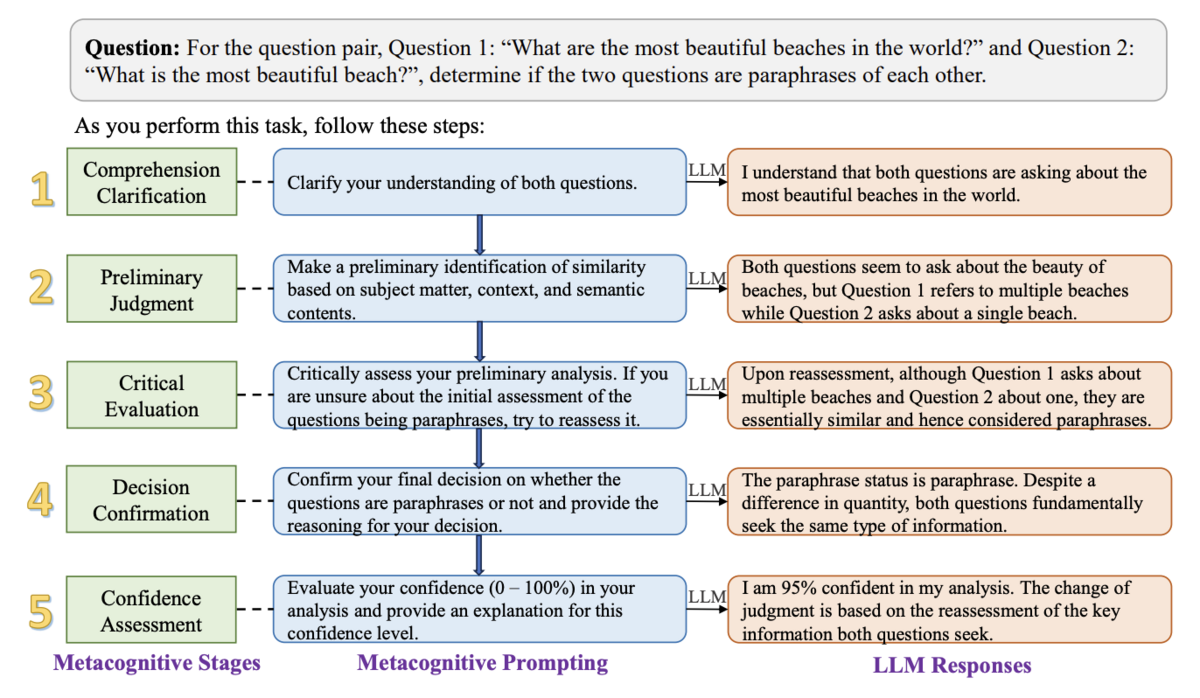
この手法を使う場合、段階的な推論の全てのログをユーザーに表示してしまうと、回答量が多くなりUXを損ねる場合があります。 多くの場合において、ユーザーに提示するのは段階的な推論の最終段階の結果のみで十分です。
つまり、システムへの組み込み用途だけでなく、LLMからの回答精度を上げる場合にも、出力形式の指定が必要となります。
ChatGPTでは、出力を決まった形式に指定するための機能として、Function Callingというサービスを提供しています。 これだけでも他のLLMではなくChatGPTを使う理由となるくらい、今後重要となる可能性があるサービスだと思います。
パイプラインの管理
セキュアなChatGPT用途では、単にAPIにユーザーからの質問を投げて、APIからの回答をそのままユーザーに提示するだけの処理で実現できます。
しかしながら、社内情報を使った回答の用途を含め、業務的に実用レベルのユースケースを実現しようとすると、 単にAPIに質問を投げて回答を取得するだけの処理では実現できません。
以下に一般的なパイプラインを紹介します。
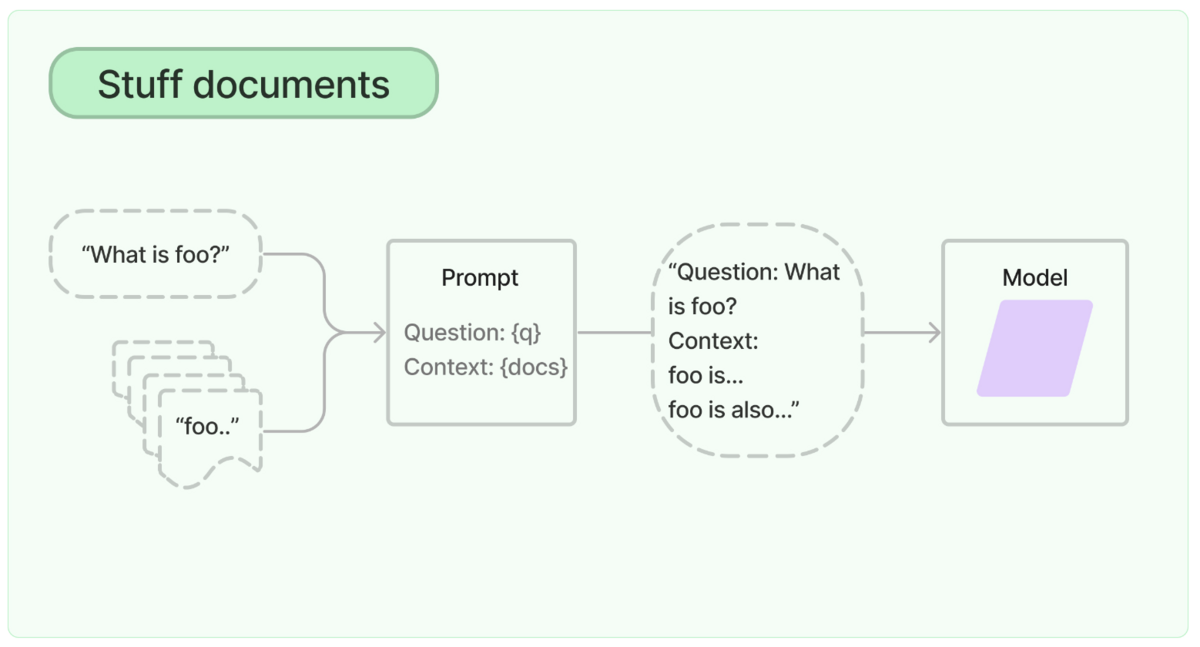
外部情報を組み合わせたユースケースで最もシンプルなパイプラインは、Stuff Documents パイプラインです。
仕組みは簡単で、プロンプトと参考情報をセットにしてAPIにリクエストを投げるパイプラインです。 上述の通り、外部情報を取り込める既存サービスのほとんどは、このStuffが実装されています。
一方、これまでのプロジェクトの経験上、Stuffを実装しただけではユーザーに提供できるクォリティの回答が得られません。
セキュアなChatGPT以降の事例が出てこない理由の1つはここにあると思っていて、 いろいろな企業がこのStuffを試し始めているものの、なかなか上手くいってないのではないかと思います。
文書の要約では、別のパイプラインが必要です。 Stuffは、文書の必要な部分を渡す処理ですが、要約では、全文を取り込む必要があります。 しかし、文字数の多い文書の場合は、一度のAPIリクエストで全文を取り込むことができないため、パイプラインで工夫する必要があります。
Map Reduceは、一定量ごとに区切った文書(chunk)をそれぞれ1回要約して、最後に全ての要約結果を集約して2回目の要約を実施する処理です。 1回目の要約部分は並列処理できるので、速度重視の場合はこのパイプラインを選びます。 Azure OpenAI Serviceなど、クラウド提供型のLLMの場合、Rate Limitが厳しいため、 Rate Limitの問題をケアして実行する必要があります。

要約では、Refineというパイプラインも選択肢として考えられます。 Refineは、一定量ごとに区切った文書(chunk)を順番に読み込んでいき、都度要約を繰り返す方式です。 処理が直列なので、Map Reduceと比較すると時間がかかります。
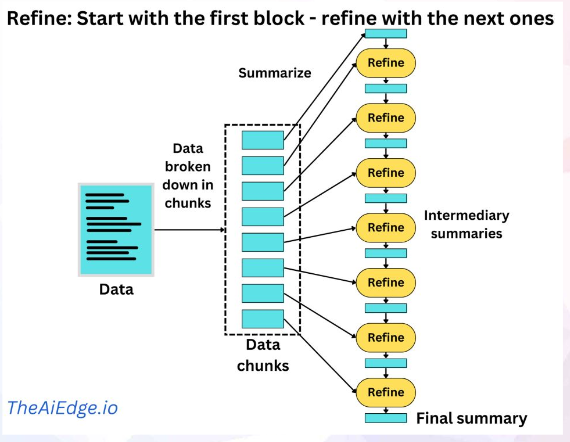
上述しましたが、このように、情報検索と要約は同じパイプラインで実現できません。 利用者の立場からすると、意図せずに情報検索と要約の両方を質問することに加え、要約の後に質問を続けたいという利用ニーズもあります。 この他にも、回答精度を上げようとしたり、利用者の業務ニーズに応じて複雑なパイプラインが必要となります(prompt chaining)。
プロジェクトでは、パイプラインが複雑になるにつれて、開発したエンジニアしか処理内容を把握していない状況になりがちです。 継続的な運用を考えると、パイプラインの設計や管理を実施する必要が出てきます。
Microsoft Azureでは、prompt flowというパイプライン管理ツールを提供しています。 一見ローコードツールのような外見ですが、肝心の処理自体はpythonで記述する必要があり、 Airflowやkedroのように、パイプライン管理の用途を想定して作られていると思います。
まだプレビュー版で、prompt flowも実用的なレベルではありませんが、LLMops領域のサービスは重要となってきそうです。

終わりに
本記事では、本格的なLLMのビジネス現場活用に向け、日々取り組んでいるテーマと、その技術的な課題を紹介しました。 現状では、スクラッチでトライアンドエラーしながら開発できるエンジニアがいないと、LLMを活用してやりたいことを実現するのは難しいです。
LLMを本格的にユーザー企業が活用して成果を出すには、まだまだ技術的なハードルが高いように感じています。
例えばディープラーニングも、色々なツールが徐々に整備され、今では誰でもちょっとした学習ならできるようになりましたが、 LLMの活用もディープラーニングの黎明期と同じような雰囲気を感じます。
現在、アカデミア含め、ものすごいスピードで目下の技術課題が解決されています。 最新技術のキャッチアップを欠かさずに、着実にできることを増やしていきたいと思っています。