こんにちは! Lead Data Scientistの梶原(悠)です。 Insight Edgeには商社内の資源系ビジネス部門から市況・需要予測系の相談が多くよせられます。 しかし、この種の案件は予測モデリングの本質的な難易度とユーザーからの期待値のずれが大きく、なかなか有効な活用に繋がりにくい印象があります。 こうした現況の改善に向けて技術的な論点は色々あるのですが、今回は、市況が急変するなどしてデータの分布が大きく変わるケースの対処をテーマに、簡易なツール調査を行います。
目次
データドリフトとは
データドリフトは、時間の経過によって特徴量の分布が変化してしまう現象です。 例えば、金属価格を予測する機械学習モデルを訓練し、継続的に運用するサービスを考えます。 このモデルの説明変数の分布は、イノベーションや地政学的なショックにより変化する可能性があります。 学習時点では現れなかったようなサンプルが頻出すると、予測の信頼性が悪化する可能性があります。 関連する概念として、コンセプトドリフトやラベルドリフトなどが挙げられます。
| 概念 | 継続的運用やオンライン学習の文脈 | バッチ学習の文脈 |
|---|---|---|
| 説明変数と目的変数の関係の変化 | コンセプトドリフト(Concept drift) |
コンセプトシフト(Concept shift) |
| 目的変数の分布の変化 | ラベルドリフト(Label drift) |
ラベルシフト(Label shift) |
| 説明変数の分布の変化 | データドリフト(Data drift) |
データセットシフト(Dataset shift) / 共変量シフト(Covariate shift) |
データドリフトの影響を緩和するために、定期的なデータの監視とモデルの再学習が有効です。 運用環境のデータと訓練データとの間で分布の差異を監視することで、ドリフトの早期検出が可能になります。
ドリフトの検出ツール
オープンソースのドリフト検出ツールは多数存在します。 使える手法の豊富さや可視化機能の充実度合いなどによる差別化が見られます。
| ツール名 | ライセンス | プログラミング言語 | フレームワーク | ドキュメンテーション |
|---|---|---|---|---|
| Seldon Alibi-detect | Apache 2.0 | Python | TensorFlow, PyTorch | https://docs.seldon.io/projects/alibi-detect/en/latest/ |
| Evidently Drift Detection | Apache 2.0 | Python | scikit-learn | https://docs.evidentlyai.com/ |
| TorchDrift | MIT | Python | PyTorch | https://torchdrift.org/ |
| Deequ | Apache 2.0 | Scala, Java | Apache Spark | https://github.com/awslabs/deequ |
検出デモ
Seldon Alibi-detectによるシンプルなドリフト検知デモを行います。
確率分布間の距離の指標であるMMD(Maximum Mean Discrepancy)を使ってドリフトを検知するalibi_detect.cd.MMDDriftOnlineクラスを使用します。
ある企業では翌日の金属価格の予測モデルを日次で運用しているとします。
さらにこのユーザーは、説明変数にガス・石油の燃料価格を用いているとします。
これらの変数のドリフトを捉えたいとします。
まず、セントルイス銀行のWebサイトからガスと石油のサンプルデータを取得してみます。
import pandas as pd import pandas_datareader.data as web import datetime tickers = {"PNGASJPUSDM":"Gas", "DCOILBRENTEU":"Oil"} data_df = ( web.DataReader( tickers.keys(), "fred", start=datetime.datetime(2016,1,1), end=datetime.datetime(2023,2,1) ) .interpolate() .dropna() .rename(columns=tickers) )
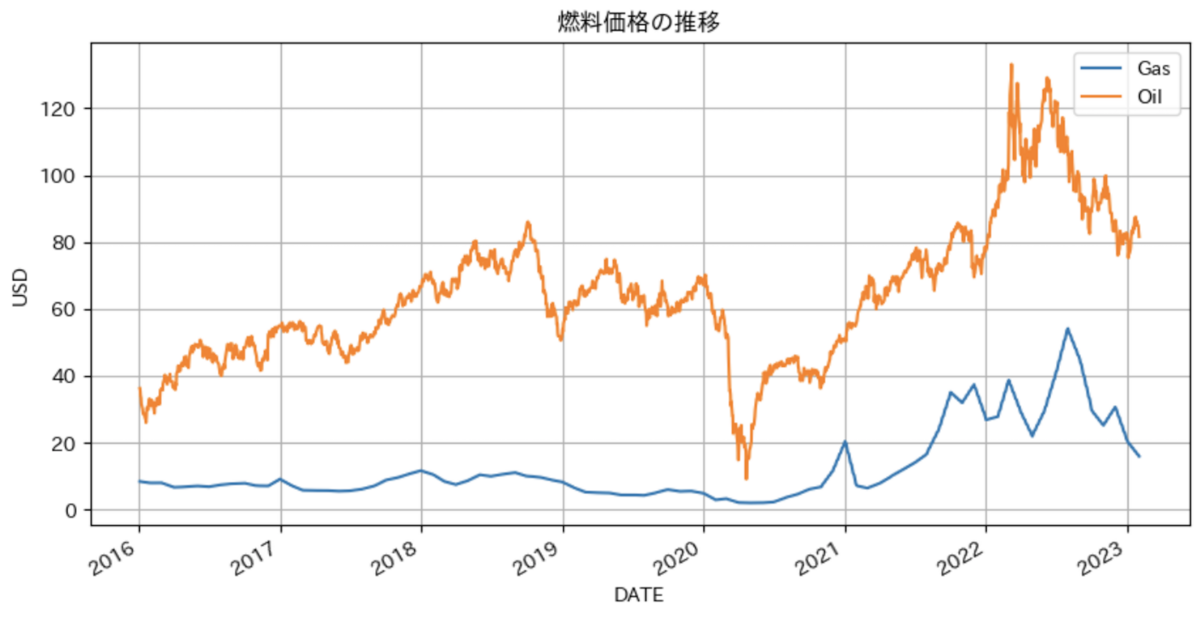
可視化してみると、2020年前半の石油価格の落ち込みや2021年からのガスと石油の価格高騰が目立ちます。2020年の落ち込みはコロナショック、2021年からの高騰はウクライナ危機によるものと想像されます。
現在は2019年の1月だとします。過去のデータを参照期間として、ドリフトの検出器を作成します。
検出器の内部では、並べかえ検定によりドリフト検出の閾値が作成されます。
今回のケースでは、並べかえ検定による閾値は小さすぎて実用的でありません。
実際に使う場合は、参照期間のデータの時系列クロスバリデーションなどにより、自分で閾値を作り込む対処が考えられます。
from alibi_detect.cd import MMDDriftOnline # データを参照期間とテスト期間に分割する. now = pd.to_datetime("2019/1/1") ref_df = data_df[data_df.index <= now] test_df = data_df[now < data_df.index] X_ref = ref_df.values.copy() X_test = test_df.values.copy() # ドリフト検出器を作成する. detector = MMDDriftOnline( X_ref, ert=500, window_size=30, backend="pytorch", verbose=True )
未来のデータをテスト期間とし、検出器を走らせてMMDを算出します。
素朴な参考値として、参照期間で走らせたMMDも算出してみます。
# 参照期間とテスト期間のMMDを算出する. test_df["squared_mmd"] = [detector.score(x) for x in X_test] ref_df["squared_mmd"] = [detector.score(x) for x in X_ref]
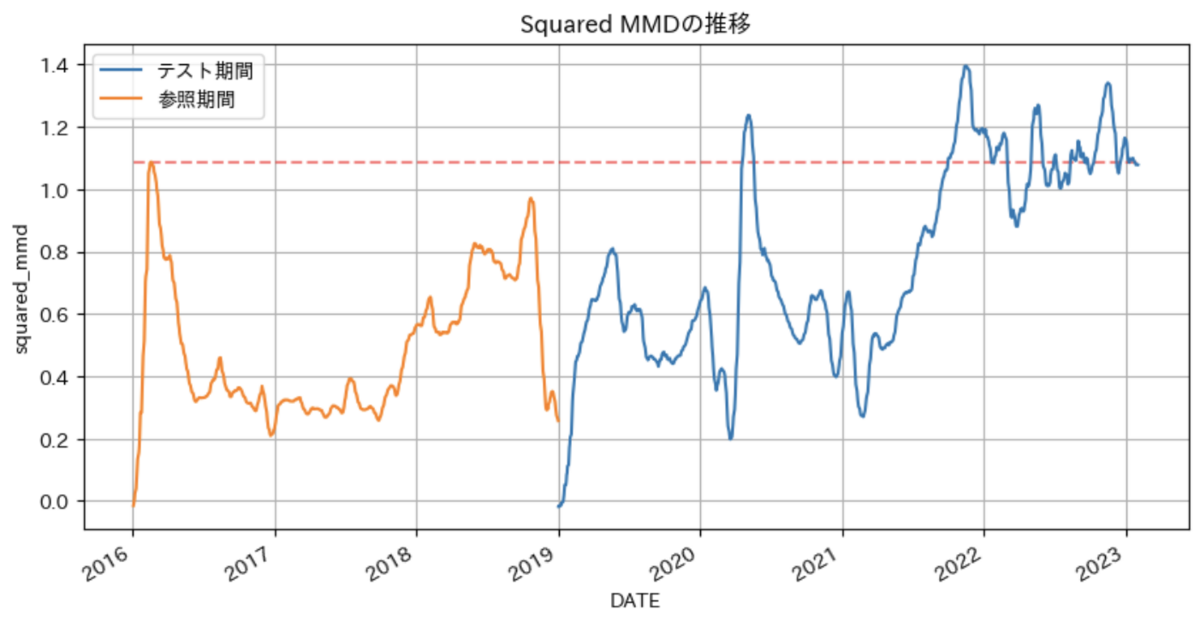
テスト期間のMMDは、2020年の4月や2021年の10月に参照期間におけるMMDの最大値を超えています。
これは、コロナショックやウクライナ危機による燃料価格の急変を検出していると想像されます。
まとめ
この記事では、データドリフトの検出ツールのライトな調査を実施し、燃料価格のデータでMMDによるドリフト検出のデモを行いました。 かなり尻切れとんぼな内容になってしまいましたが、何らかの参考になりましたら幸いです。 学習時と運用時の間でデータの分布が変わってしまう問題周辺は、継続的に調査していきたいと思っています。