こんにちは、k-kzkです。私はInsight Edgeに参画して早2年が経ちました。 今回の記事では、私が初めて取り組んだETL開発プロジェクトと、そこで選択したツールであるDataformについてお話しします。
目次
1. はじめに
プロジェクトに参画するまで、データをメインに扱う開発経験がほとんどなかった私にとって、「ETL」という言葉も聞き馴染みが無いものでした。 正直、最初は「ETLって何?」という状態でしたが、データの抽出、変換、格納といった一連のプロセスを効率的に行うためのツール選びから始めることになりました。 この記事ではDataformを用いた開発プロセスを、私の経験を元に順に説明していきます。
1.1 ETL 開発とは
まず、ETLとは何か。ETLとは、データを抽出 (Extract)、変換 (Transform)、格納 (Load) する一連のプロセスのことです。 大量のデータを扱い、それを適切に加工して最終的な形にするための作業と言えます。 ETLの処理はSQLさえ書ければ基本的にどのプログラミング言語でも対応できますが、プロセスをより簡単に、そして管理しやすくするためには適切なツールが必要です。 そこで私たちのチームが注目したのはDataformでした。
1.2 Dataform の選定理由
Dataformを選定した最大の理由は、BigQueryとの親和性です。 BigQueryは私たちのプロジェクトの基盤となるデータベースであり、同じくGoogle CloudのサービスであるDataformはBigQueryに直接アクセスし、SQLを使ってスムーズにデータを操作できます。 また、グラフによる可視化機能もあるため、データの依存関係を直感的に理解しやすく、レビューやデバッグもしやすいです。
Dataformについては、公式のガイド を試すことによって理解を深めることができました。
他のETLツールであるdbtも検討に上がりましたが、今回はBigQueryとの親和性を重視し、特に比較検証を行わずDataformの利用に決定しました。
2. Dataform を利用した ETL 開発のライフサイクル
2.1 リポジトリ作成
まず始めに、Dataformのリポジトリを作成します。作成方法に特に制限はなく、コンソールから手動で作成する方法やTerraformでの自動化など、さまざまな方法が考えられます。Dataformを扱う場合は、GitHubなどのGitリポジトリと接続するケースが一般的です。 このGitリポジトリの接続については、手順書 も公式に公開されていますが、以下の点に注意が必要です。
注意ポイント:
Dataform側のSSH認証の設定作業にて、手順の中でホストのSSH公開鍵のKey-Valueを設定する必要があります。
このホストのSSH公開鍵については、GitHub の SSH 公開鍵情報のページ から取得すればよく、例えば ssh-ed25519 を扱う場合は以下を設定すればよいのですが...
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOMqqnkVzrm0SdG6UOoqKLsabgH5C9okWi0dh2l9GKJl
GitHub の SSH 公開鍵情報のページ のページには、以下のようにホスト名が入っておりこのままではGitHubとの接続に失敗してしまいます。
github.com ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOMqqnkVzrm0SdG6UOoqKLsabgH5C9okWi0dh2l9GKJl
このように、そのままコピペすると上手くいかないなど罠があるので、ガイドはしっかり隅から隅まで読みましょう。
2.2 ワークスペースの使い方について
Dataformでは、1つのリポジトリ内で複数のワークスペースを作成できます。 開発者はGitHubのブランチのようにワークスペースを作成して作業を進めます。 このとき、データセット(スキーマ)の接尾辞を設定することで、ワークスペースごとに独立した環境が作成され、開発環境の競合を防ぐことができます。

設定することで、ワークスペースごとにデータセットが生成されるため開発環境の競合が発生しません。
注意ポイント: ワークスペースを削除してもデータセットやテーブルは削除されません。 BigQuery上に不要なテーブルが増えないよう、管理に工夫が必要です。
2.3 ディレクトリについて
ワークスペースの準備が整ったら、Dataform用のSQLXソースコードをどのように管理するか考えます。 Dataformを開発する上で必要なディレクトリとファイルは以下の通りです。
| ディレクトリ/ファイル | 目的 |
|---|---|
| /definitions | sqlx ファイルを格納するディレクトリ |
| /includes | 再利用可能な JavaScript の スクリプトを格納するディレクトリ |
| workflow_setting.yaml | Dataform の設定ファイル |
これら以外のディレクトリやファイルはDataformに影響を与えません。 TerraformやCloud Workflowsの設定ファイルなど、他のソースコードと同じリポジトリで管理可能です。
2.4 テーブル構成
プロジェクトでは以下の目的でテーブルを定義しました。 ETLの各処理を目的ごとに定義することで、ロジックを明確に分割し、管理を容易にしています。 今回は、Dataformで管理するテーブル以外を外部データと定義します。
| テーブル一覧 | 目的 |
|---|---|
| マスタテーブルの DDL | マスタテーブルを定義する |
| Extract ビュー | 外部データを取得する |
| Transform ビュー | マスタテーブルと外部データを結合する |
| Incremental テーブル | データの蓄積を目的とする |
| I/F ビュー | Load に必要なデータのみを格納する |
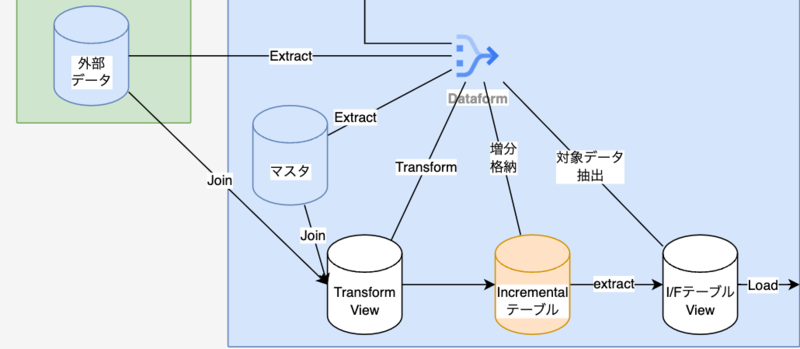
Dataformでは、各コードがテーブルとして生成されます。 このように分割することでデータの読み書き回数が増えるため、コストの考慮が必要です。しかし、管理しやすくするために分割するのが良いでしょう。 特にTransform処理は複雑なロジックになることが多いので、分割するべきです。
2.5 Dataform のテストについて
Dataformで作成したテーブルのテストは アサーション 機能を利用して実施します。 アサーションの記載は簡単で、以下のようにconfigを定義するだけでテストが実行されます。
config {
type: "view",
name: "dataform_name",
tags: ["daily"],
assertions: {
uniqueKey: "key",
nonNull: ["key", "column1", "column2"]
}
}
注意ポイント: 全体スキャンを毎回実行するとアサーションによるBigQueryの処理が過剰に発生し、課金の発生に繋がる ため、注意が必要です。適量なアサーションを心がけましょう。
2.6 リリース方法について
プロジェクトでは、Google Cloudのプロジェクトを開発・検証用と本番用に分けています。 開発・検証用には、開発環境(開発者ごとに構築される環境)、PR環境(PR起票時に構築される環境)、検証環境があり、本番用には本番環境の計4種類を構築しています。
今回のリリース対象はマスタとそれ以外に分かれます。 マスタのリリースは手動とし、それ以外のデーブルはGoogle Workflowsによって構築としました。
手動構築の場合には リリース構成 を作成しておくのが望ましいです。 リリース構成を定義し、Gitブランチやコンパイル変数などを設定しておくことで環境の再構築や複製を簡単に準備できます。
Google Workflowsによるリリースの場合は、 APIを通じてコンパイルを実行します。 APIガイドは こちら です。 リリース構成と同じように、引数などを設定可能です。
- createCompilationResult:
try:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + dataform_repository + "/compilationResults"}
auth:
type: OAuth2
body:
gitCommitish: main
codeCompilationConfig:
schemaSuffix: ${schema_suffix}
vars: { "TARGET_DATE": "${target_date}" }
result: compilationResult
Dataformの実行は こちら を用います。
ここでタグを指定して実行が必要なDataformコードを指定しています。
- createWorkflowInvocation:
try:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + dataform_repository + "/workflowInvocations"}
auth:
type: OAuth2
body:
compilationResult: ${compilationResult.body.name}
invocationConfig:
includedTags:
- ${tag}
result: workflowInvocation
3. その他開発における Tips
3.環境ごとの分岐処理を作成する場合
DataformではJavaScriptを利用することで環境による分岐処理を実装できます。 以下は、特定の環境でのみ実行したい処理を記述する例です。 今回のプロジェクトでは、開発環境のマスタテーブルのデータについては検証環境からコピーするといった処理を追加しました。
例えば、以下のJavaScriptコードはSTG環境以外の環境はSTG環境のテーブルをコピーするような処理となります。 このように環境ごとに異なる処理を定義する場合はJavaScriptで定義できます。
function insertIfNotExists(table_name, schema_name) {
const STG_SCHEMA_NAME = dataform.projectConfig.vars.STG_SCHEMA_NAME;
const STG_DATASET_NAME = dataform.projectConfig.vars.STG_DATASET_NAME;
if (schema_name != STG_SCHEMA_NAME) {
return `
DECLARE record_exists BOOL DEFAULT FALSE;
SET record_exists = (
SELECT EXISTS (
SELECT 1
FROM \`${schema_name}.${table_name}\`
LIMIT 1
)
);
IF NOT record_exists THEN
BEGIN
INSERT INTO
\`${schema_name}.${table_name}\`
SELECT
*
FROM
\`${STG_DATASET_NAME}.${STG_SCHEMA_NAME}.${table_name}\`;
EXCEPTION WHEN ERROR THEN
END;
END IF;
`
}
}
module.exports = {
insertIfNotExists
};
3.2 データセット作成時のエラーについて
Dataformでは、テーブル生成時に対象となるデータセットが存在しない場合、自動的に生成されます。 ただし、複数のETL処理を並行して実行する場合、一方の処理でデータセット生成が行われている間に、他の処理でデータセットが未作成のままテーブル生成を試みる可能性があり、その際エラーが発生します。
私もベストプラクティスを持っていないのですが、暫定的な回避策としては以下のようにconfigのdependenciesを設定することで、処理の順序を制御できます。
config {
type: "operations",
name: "sampleB",
hasOutput: true,
tags: ["master"],
dependencies: ["sampleA"]
}
データセットが存在しない場合のみなので運用時には影響がないものですが、この回避策は開発中に有効であり、環境の整合性を保ちながら進行できます。
4. まとめ
今回は初めてDataformに触れ、どのように準備し開発を進めているかについてお話ししました。 ETLツールを用いるのは初めてでしたが、基本的な操作は非常に簡単で、個別の機能についても十分にガイドや記事が出回っているため進めやすかったです。 Dataformを用いた開発の進め方やベストプラクティスについてはまだ模索中ですが、この記事が他の開発者の参考になれば幸いです。