はじめに
Insight EdgeのLLM Engineerの藤村です。
昨今、企業のDX推進に伴い、社内に蓄積された大量の画像データや文書の効率的な活用が求められています。弊社では、実務でLLMを活用する際、画像や表形式、複雑な図を含むドキュメントの理解が大きな課題となっています。この課題は多くの企業でも同様に直面していると考えられ、その解決は業務効率化において重要な意味を持ちます。
例えば:
- PowerPointの表やグラフの内容理解
- 手書きのホワイトボード写真からの情報抽出
- 複雑な組織図の階層関係の把握
- スキャンした文書の図表部分の解釈
これらの課題に対して、以下の2点を検証しました:
- 最新のマルチモーダルLLMでどこまで対応できるのか
- GPT-4oのファインチューニングによってどの程度改善できるのか
目次
マルチモーダル大規模言語モデルとは
近年、テキストだけでなく動画像も扱うことができる、対話型LMM (大規模マルチモーダル言語モデル)の開発が盛り上がりを見せている中で、ビジネスシーンにおける利用に焦点が当てられています。
例えば、LMMを組み込んだRAG (Retrieval-Augmented Generation)を用いることで、表や図、パワポスライド、文字ドキュメントなどの大量にある社内画像データから、ピンポイントに知識を手早く得ることができます。LMMには以下の図のような能力が備えられていることが期待されています。

- 画像認識能力
- 写真・図表・ドキュメントなど様々な形式の画像に対する汎用性と配置への理解力
- 外部知識
- 一般知識 (固有名詞、普通名詞などへの知識)、オントロジー的意味理解、数学、言語等
- 言語認識能力
- 多数言語に対する汎用能力、プログラミング言語も
- 指示対応力
- 質問で要求された通りの回答が出せるか
1. 主要マルチモーダルLLMの性能検証
検証方法
本検証では、実務での活用を想定し、以下の3つの観点から総合的な評価を行いました
画像認識精度
- 文字認識の正確性
- 図表要素の識別能力
- 空間的な配置の理解
文脈理解力
- 業界用語の適切な解釈
- 図表間の関連性把握
- 暗黙知の理解
応答品質
- 回答の正確性
- 説明の論理性
- 出力形式の一貫性
今回、Insight Edgeでも利用頻度が高い以下の3つのモデルで比較検証を実施します。
- Google: Gemini 1.5 Pro
- OpenAI: GPT-4o
- Anthropic: Claude 3.5 Sonnet
検証データ
実際のビジネス利用シーンを想定して、様々なユースケースにおける質問を用意しました。
- 業務用文書画像8枚
- 質問23問(画像の内容理解、関係性の把握など)
| 画像名 | 質問 | 質問種別 |
|---|---|---|
| ガートナー曲線図 | 特定フェーズに位置する要素を時系列順に抽出 | データ抽出 |
| ガートナー曲線図 | 所要期間が特定条件を満たす要素を抽出 | データ抽出 |
| 顧客アンケート1 | 情報公開の同意状況の確認 | 選択読取 |
| 顧客アンケート1 | 回答者の基本的な個人属性情報の確認 | 属性理解 |
| 顧客アンケート1 | 自由記述から感情や評価傾向を分析 | 内容分析 |
| 顧客アンケート1 | フォームの設問と回答の完全な書き起こし | 全文読解 |
| 顧客アンケート2 | 情報公開の同意状況の確認 | 選択読取 |
| 顧客アンケート2 | フォームの設問と回答の完全な書き起こし | 全文読解 |
| アイデア板書 | 企画・催事の正式名称を特定 | データ抽出 |
| アイデア板書 | 必要物品や参加者の数量・規模の確認 | 数値理解 |
| アイデア板書 | 企画の主要テーマとコンセプトの把握 | 内容分析 |
| 診療報告書 | 服薬・治療に関する指示事項の確認 | 内容分析 |
| 診療報告書 | ケアの実施スケジュールと頻度の確認 | 数値理解 |
| 診療報告書 | 医療サービスの提供方法の確認 | 属性理解 |
| 組織図 | 特定部門の構成員一覧の確認 | 構造把握 |
| 組織図 | 特定ユニットの下位組織一覧を抽出 | 構造把握 |
| 組織図 | 組織間の階層・指揮命令系統の確認 | 構造把握 |
| 都道府県別分布図 | 特定条件での上位地域を順に抽出 | データ抽出 |
| 都道府県別分布図 | 特定地域の順位グループ分類を確認 | 数値理解 |
| 都道府県別分布図 | 特定地域の順位グループ分類を確認 | 数値理解 |
| スキルマトリクス | メンバーの各スキル習熟度を確認 | 属性理解 |
| スキルマトリクス | 今後の育成方針の重点項目を特定 | 内容分析 |
| スキルマトリクス | 評価未記入の項目を特定 | データ抽出 |
サンプル例
以下は検証で使用した画像データの例です。
Gartnerのコクテッド・インダストリ・テクノロジのハイプ・サイクル図
- 幻滅期のテクノロジーを時間が早い順に全て列挙してください
- 採用するまでの年数が10年以上かかる技術を全て列挙してください

画像選定意図:密集した丸を識別し時系列に並べられるのか、凡例を理解した上で画像認識できるのか
都道府県防災会議における委員に占める女性の割合
- 15%以上〜20%未満に属する都道府県を全て答えよ
- 埼玉県は何%の帯域に属するか

画像選定意図:都道府県の位置関係の知識を有しているか、ヒートマップの色の違いを認識できるのか
評価方法
評価手法には大きく、コード評価(CE) モデル評価(ME) 人手評価(HE)があります。
今回はモデル評価(ME)を採用しました。LLM as a judgeともよばれる手法です。
理由としては、規模に強く指示文で採点カスタマイズ可能だからです。

モデル評価 LLM as a judge
採点用のモデルはGPT-4oを使用しました。 モデル評価にあたり使用したプロンプトは以下の通りです。
# 指示 あなたはテストの採点者です。採点ルールに従って、回答文と正解文の類似度のスコアとその理由を思考過程も合わせて日本語で出力してください。 # 入力情報 入力情報: 「画像説明」、「質問」、「回答文」、「正解文」 # 採点ルール 評価基準: 「画像説明」と「質問」を参考に、「回答文」が「正解文」にどれだけ類似しているかを評価する。回答文がで減点しない。順番も問われている問題は、順番を間違えていると、0.25減点。 スコア配分: 部分点に応じて0.25点刻みで採点。 理由部分の採点: 回答文が理由部分で画像から文字を引用している場合、その引用部分が間違えていると0点。 # 文字起こし 句読点や記号のミスやスペース・改行のズレがあっても減点しない。それ以外では、文字が完全に一致していない場合は0点。誤記がある場合は0点。 # 単体単語回答: 正解文が1単語の時、回答文の中に同じ単語があれば1点。正解文にない単語を回答文が答えているとき0点。さらに、理由部分が画像説明や質問に正しく沿っていないと0点。 数字問題では正解文の内訳が回答文になくても減点しない。 # 複数単語回答: 正解文が複数単語の時、回答文の中で、全ての単語を答えられていたら1点。回答文が正解文の単語を一部答えられていて、正解文にない単語も答えていない場合は、合っていた割合に近い点数を部分点として与える。 さらに、1つでも正解文に存在しない単語を回答すると0点。ただし、「・」はついていてもいなくても減点対象としない。 さらに、回答が正しく、理由が画像説明や質問に正しく沿っていると1点。理由が画像説明や質問に正しく沿っていないと0点。 # 文章回答: 回答文が画像説明に沿った回答をし正解文と意味が等しい時、1点。回答文の意味が画像説明や正解文と全く異なると、0点。 # 図表推論問題: 画像説明や正解文にある通り、回答文が正しく情報が読み取れていたら1点。根拠が正しくないときは0点。
今回は実際のビジネス利用を想定して、ハルシネーション(嘘の回答)が含まれていたら強めに減点するようにかなり厳しめに採点ルールを設けています。このプロンプトによって採点の基準をカスタマイズできるのがLLM as a judgeの利点ですね。
また、LLMの仕様上、毎回同じ点数を安定して出力できないので、3回以上実行して平均点を算出することで、安定した評価を行うように工夫しています。
検証結果
検証結果は以下の通りでした。
| モデル | スコア |
|---|---|
| GPT-4o | 6.58 |
| Gemini 1.5-Pro | 8.31 |
| Claude 3.5 Sonnet | 6.61 |
*23点満点
Gemini 1.5 Proが最も高いスコアとなりました。
問題によっては完全回答ができず、部分点のみの回答となったり、回答理由部分が間違っていると0点となることもありました。
満点が23点なので、問題設定の難易度が高いこともありますが、どのモデルもあまりいい結果とは言えないですね。
各モデルの特徴は以下の通りです。
Claude 3.5 Sonnet
- 組織図の階層関係理解が優れている
- 日本語テキストの認識精度が高い
- 文脈を考慮した自然な回答
GPT-4o
- 表形式データの解析が得意
- 一般的な画像認識で安定した性能
- 複雑な図表での誤認識が時々発生
Gemini 1.5 Pro
- 複雑な図表の理解力が高い
- 処理速度が比較的速い
- 手書き文字の認識にやや課題
答えられなかった問題
質問:幻滅期のテクノロジーを時間が早い順に全て列挙してください
正解:図のオレンジで囲われたテクノロジーを左から順に答える

誤答内容:
- スマート・ロボット, 2. AR, 3. LPWA, 4. 次世代リアル店舗
原因考察:
- 幻滅期の中でも群が2つあり、片方しか認識できていない。
- 丸が幻滅期に属していても文字の位置が別のグループに跨っていて正しく認識できていない。
現状の課題
検証で明らかになった主な課題:
認識の不安定さ
- 画像品質による性能のばらつき
- 複雑な表構造の誤認識
- 手書き文字の認識精度の変動
文脈理解の限界
- 業界特有の用語や略語の誤解
- 図表間の関連性の把握ミス
- 暗黙知的な情報の見落とし
2. GPT-4oのファインチューニングによる改善検証
ファインチューニングとは?
ファインチューニングとは、事前学習済みのLLM(大規模言語モデル)に対して、特定のタスクや領域に関する追加データで学習を行い、モデルの性能を改善する手法です。これは転移学習の一種で、モデルの基本的な能力を保持しながら、特定の用途に特化させることができます。
ファインチューニングのメリット
- マルチモーダルLLMの業務文書認識における課題を解決できる
- ビジネスユースケースに即した適切な学習データを用意することで、さらなる性能向上が期待できる
ファインチューニングを行うことで、検証で使用したモデルの課題を解決できることを期待します。
ファインチューニング手順
Azure OpenAIが提供するGPT-4oのファインチューニング機能を使用します。この機能は、既存のモデルを特定のタスクや領域に特化させることができ、今回のようなマルチモーダルタスクにも適用可能です。
fine-tuningの実施手順についてはAzure公式の以下のドキュメントを参考にしました。
1. ファインチューニング用の学習データを用意
今回のファインチューニングでは上記の検証で使用したデータは評価データとして使用するので、学習用に別途、類似のデータを用意しました。 (画像は省略します)
- 学習データ:
- 業務文書画像10枚
- 質問と回答のペア27セット
- 様々なタイプの図表や手書き文書を含む
学習データは以下のようなJSON形式で用意する必要があります。 今回画像を含んだデータを使用するので、画像のURLを指定しています。
{ "messages": [ { "role": "system", "content": "あなたは画像認識のスペシャリストで、どんな図表やグラフでも詳細に分析できるAIアシスタントです。" }, { "role": "user", "content": "この組織図における部門の数と階層構造を教えてください。" }, { "role": "user", "content": [ { "type": "image_url", "image_url": { "url": "https://blob.example.com/images/sample1.jpg" } } ] }, { "role": "assistant", "content": "営業、開発、マーケティングの3つの主要部門があり、それぞれ2-3の下位部門を持つ3層構造になっています" } ] }
上記のJSONを複数用意し、以下のようにJSONL形式で保存します。
{"messages": [{"role": "system", "content": "あなたは画像認識のスペシャリストで、どんな図表やグラフでも詳細に分析できるAIアシスタントです。"}, {"role": "user", "content": "この組織図における部門の数と階層構造を教えてください。"}, {"role": "user", "content": [{"type": "image_url", "image_url": {"url": "https://blob.example.com/images/sample1.jpg"}}]}, {"role": "assistant", "content": "営業、開発、マーケティングの3つの主要部門があり、それぞれ2-3の下位部門を持つ3層構造になっています"}]} ...(省略)... {"messages": [{"role": "system", "content": "あなたは画像認識のスペシャリストで、どんな図表やグラフでも詳細に分析できるAIアシスタントです。"}, {"role": "user", "content": "各部門の人員規模と報告ラインの特徴を分析してください。"}, {"role": "user", "content": [{"type": "image_url", "image_url": {"url": "https://blob.example.com/images/sample1.jpg"}}]}, {"role": "assistant", "content": "営業部門が最大で150名、開発部門が120名、マーケティング部門が80名の構成です。各部門長は直接CEOに報告し、部門内は最大でも3段階の報告ラインとなっています"}]}
2. Azure OpenAI上でファインチューニングを実行
AzureのAzure AI Foundry上でファインチューニングを実行します。 公式の手順に従ってプロジェクトを作成します。
左パネルの「微調整」を選択します。
モデル選択画面からGPT-4oを選択します。
そのあとは画面の手順に従って、学習データをアップロードして、ファインチューニングを実行します。
実行時間は今回のデータ量だと50分ほど要しました。
トレーニングが完了したら、「デプロイ」を選択して、ファインチューニング後のモデルをデプロイします。
3. ファインチューニング後のモデルを使用して、テストデータを評価
Azure OpenAI上でもPlaygroundを使用して、ファインチューニング後のモデルを使用してテストデータを評価できます。
今回はLangChainを使用して、ファインチューニング後のモデルを使用してテストデータを評価しました。
# ファインチューニング実装例 from langchain_openai import AzureChatOpenAI import os # モデルの初期化 # temperature: 値が低いほどランダム性の低い出力になります(0.0-1.0) temperature = 0 fine_tuned_llm = AzureChatOpenAI( openai_api_key=os.getenv("AZURE_OPENAI_API_KEY"), # fine-tuning後に発行されたAPIキー model="gpt-4o", azure_deployment="gpt-4o-finetune", #azureで設定したモデル名 api_version="2024-02-15-preview", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT_FINETUNE"), # fine-tuning後に発行されたエンドポイント temperature=temperature, ) # モデルの呼び出し # 画像を含むメッセージの作成 messages = [ {"role": "user", "content": "この組織図における部門の数と階層構造を教えてください。"}, {"role": "user", "content": [{"type": "image_url", "image_url": {"url": "https://blob.example.com/images/sample1.jpg"}}]} ] # 推論の実行 response = fine_tuned_llm.invoke({"messages": messages})
改善結果
| モデル | スコア |
|---|---|
| GPT-4o | 6.58 |
| GPT-4o-finetune | 10.75 |
未学習のGPT-4oと比較して、正解スコアが約 65% 向上しました。この改善は特に以下の3つの観点で顕著でした
文脈理解の向上
- 業界特有の用語や略語の正確な解釈
- 図表間の関連性の把握精向上
空間認識能力の改善
- 複雑な図表での位置関係の理解
- 色彩や形状の正確な識別
回答精度の向上
- より具体的で正確な数値の抽出
- 多段階の推論を要する質問への対応
質問種別ごとのスコア
また、質問種別によるスコアの変化は以下の通りです。
| 質問種別 | GPT-4o | GPT-4o-finetune |
|---|---|---|
| データ抽出:特定条件での情報抽出 | 0.5 | 0 .75 |
| 選択読取:選択肢の判別 | 2.0 | 2.0 |
| 属性理解:基本属性の把握 | 0.75 | 1.0 |
| 内容理解:文脈や意図の理解 | 0.0 | 2.0 |
| 全文読解:文書全体の把握 | 0.0 | 0.75 |
| 数値理解:数値情報の解釈 | 1.0 | 2.0 |
| 構造把握:関係性の理解 | 2.25 | 2.25 |
正解できるようになった問題
例えば、以下の画像の問題では、未学習のGPT-4oは不正解でしたが、ファインチューニング後は正解となりました。
都道府県防災会議における委員に占める女性の割合
- 埼玉県は何%の帯域に属するか
- GPT-4o: 15%以上〜20%未満 (不正解)
- GPT-4o-finetune: 20%以上〜40%未満 (正解)
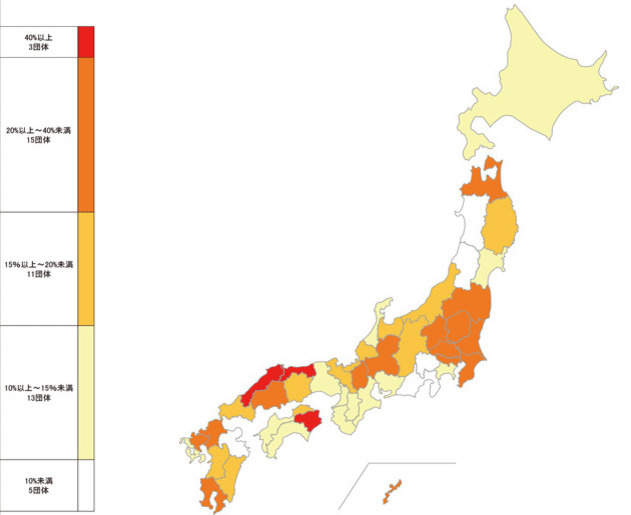
色の違いや県の位置関係を理解しているかを問う問題です。
学習データには日本地図の画像は含んでおりませんでしたが、ファインチューニングにより、画像の空間把握能力が向上したと考えられます。
まとめと今後の展望
ファインチューニングによって、マルチモーダルLLMの業務文書認識における課題をある程度解決できることが確認できました。特に注目すべき点として
画像認識精度の向上
- 複雑な図表の理解力が65%向上
- 空間的な関係性の把握能力の改善
業務特化型の処理
- 特定業務領域での高い精度
- カスタマイズ可能な応答形式
今回は合計27セットの学習データを使用しましたが、実際のユースケースを想定して、適切な豊富な学習データを用意することで、さらなる性能向上が期待できます。
今後の展開
- より多様な業務文書での検証
- 学習データの質と量の最適化
- 他のマルチモーダルLLMとの組み合わせ検討
実務でのマルチモーダルLLM活用において、ファインチューニングは有効な手段となることが分かりました。各組織の特性に合わせた適切な学習データを用意することで、より実用的なソリューションを構築できると考えています。
また、今回LLM-as-a-judgeを用いて、採点の自動化を行いました。人手による採点プロセスを大幅に効率化できたのはメリットだと感じました。一方で、採点基準の定義を言語化してプロンプトに反映させたり、LLM特有の出力のブレをいかに抑えるかなど、採点精度の向上における課題は改善の余地があるように感じました。
おわりに
「1. 主要マルチモーダルLLMの性能検証」では、インターン生の田中知可良さん(東京科学大学大学院(旧東工大))にもご協力いただきました。ありがとうございました!
当社では、新卒採用について26年度採用もオープンしているため、興味のある方はぜひともエントリー頂けると幸いです!
参考文献・引用元
ガートナー、「日本におけるコネクテッド・インダストリ・テクノロジのハイプ・サイクル:2023年」、2023年10月 https://www.gartner.co.jp/ja/newsroom/press-releases/pr-20231003
内閣府、「令和5年版 防災白書」、図表1-10-1 都道府県防災会議における委員に占める女性の割合 https://www.bousai.go.jp/kaigirep/hakusho/r05/zuhyo/zuhyo1-01_10_01.html
Yang Liu et al., "Datasets for Large Language Models: A Comprehensive Survey", arXiv:2402.18041, 2024年2月 https://arxiv.org/pdf/2402.18041