Introduction
こんにちは、データサイエンティストの善之です。
Insight Edgeでは社内のコミュニケーション活性化を目的として定期的にシャッフルランチを開催しています。
企画の全体像については以前ntさんに投稿いただいた 社員同士の距離を縮める!シャッフルランチ会開催レポート をご覧ください。
今回は、ntさんの記事で詳しく触れていなかった「グループ分けを最適化するアルゴリズム」の詳細をご紹介したいと思います。
目次
実現したいことと課題
ランチ会の目的は以前の記事にも記載の通り、コミュニケーション活性化のために社員同士の接点を増加させることでした。
したがって、普段あまり接点がない人どうしをランチ会でできる限り巡り合わせることが最大のミッションでした。
さらに、企画の要件から次の制約条件もありました。
- 各社員が3回参加(月に1回、3ヶ月間)
- 1グループあたり4-5名
- 参加者は31名
これらの制約を満たしながら、普段あまり接点がない人どうしの接点を最大化させる必要があったのですが、全て手作業で決めるのは至難の業です。
手作業でもある程度良い組み合わせは見つけられるかもしれませんが、労力がかかるうえに最適解よりも接点がない人どうしの組み合わせ数が少なかったり、
制約を一部満たせなかったりするかもしれません。
そこで、今回はPythonで遺伝的アルゴリズムを使って最適解を探索し、組み合わせを自動で決定するアルゴリズムを開発しました。
要件の整理
あらためて、今回の要件を整理したいと思います。
最大化する目的関数
- 普段あまり接点のない人どうしが同じグループになる回数
(ただし、重複も1回とカウント。たとえば普段あまり接点のない同一ペアが3回とも同じグループになっても1回とカウント)
制約条件
- 企画段階から決まっていた要件
- 各社員が3回参加(月に1回、3ヶ月間)
- 1グループあたり4-5名
- 参加者は31名
- アルゴリズムを作成する過程で加えた方が良いと判断した制約
- マネージャーどうしは同じグループにはならない(普段から接点が非常に多いので)
- メンバーの中身がほとんど同じチームは2回以上できない(今回はチームのうち3人以上が他の回と同じ組み合わせになるチームを除外)
- 3回とも同じ人と同じチームにはならない
今回はこれらの条件を満たすアルゴリズムを開発しました。
アルゴリズムの概要
基本的なアイデア
まずは基本的なアイデアを紹介します。
今回は1-3月に毎月1回ずつランチ会を開催しましたので、はじめに全メンバー(31名)のリストを計3回分作ります(3×31の2次元配列になります)。
そして、月ごとにメンバー31名の順番をランダムに並べ替えておきます(①)
次にこのリストを左から順に5人→5人→5人→4人→4人→4人→4人に区切って分割します(②)
これで月ごとに全31名を5人グループ×3と4人グループ×4に分割できました。

あとは、ランダムな並べ替えパターン全通りの中から制約条件を満たすパターンだけに絞り込み、
その中で普段あまり接点のない人どうしが同じグループになる回数が最大のものを抽出すれば完了になります。
ですが、今回はこのパターン数が膨大なので、計算に時間がかかり過ぎてしまいます。
実際に月ごとにメンバーの順番をランダムに並べ替えるとすると、全パターンが
31!×31!×31!=5.56e+101通りあり、とても計算できないです。
もう少しスマートに、ランダムな並べ替えではなくメンバーの組み合わせパターンのみを考えることで試行数は減らせますが
それでも計算量は膨大です(1ヶ月分の組み合わせだけでも9.96e+19通りあります)
そこで、今回は遺伝的アルゴリズムを使って効率的に解を探索することにしました。
遺伝的アルゴリズム
遺伝的アルゴリズムとは、自然進化の原理をもとにした最適化技術であり、選択・交差・突然変異といったステップを通じて解の質を逐次的に向上させるアルゴリズムです。
(解の効率的な探索手法であって、必ずしも最適解が求まるとは限らないことに注意が必要です)
アルゴリズムの概要を図にまとめました。

このアルゴリズムの手順は
① 初期個体をランダムにN個生成
② N個の個体から、目的関数のスコアが良い個体Best2を選択
③ ②で選定した2つの個体から、交叉と変異を用いて新しい個体をN個生成
④ ③で生成されたN個の個体を新たに②のインプトットとして、②-③の手順をM回繰り返す(このMは世代数と呼ばれる)
となります。
ただし、今回は最適化したい配列が1次元ではなく、3ヶ月分の3次元の配列ですので、このアルゴリズムをそのまま適用できません。
そこで今回は、遺伝的アルゴリズムをカスタマイズして実装しました。
実装した方法を図に示します。
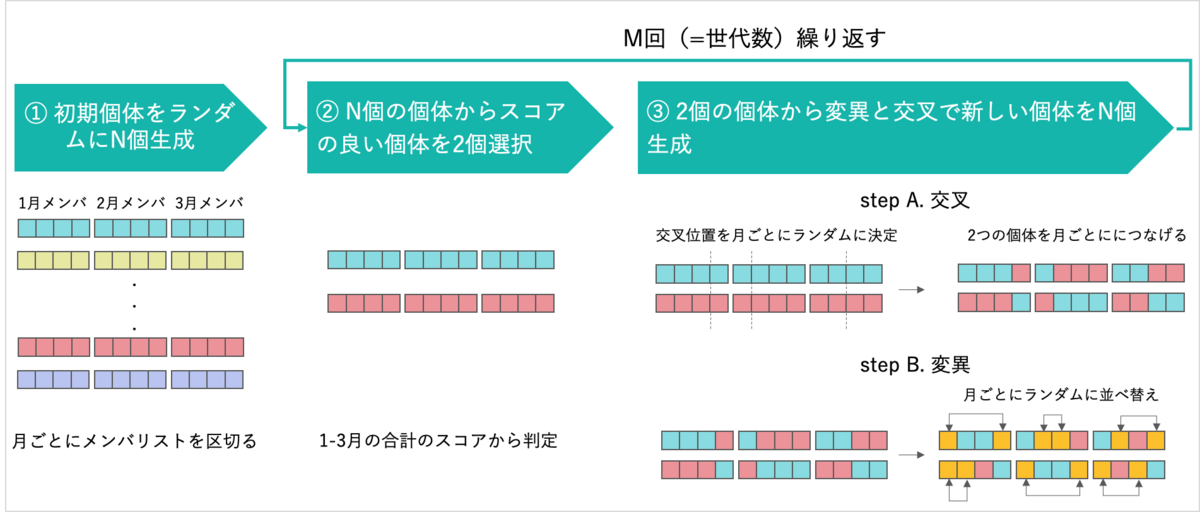
基本的なアイデアは先ほどと同じですが、交叉と変異は月ごとのメンバー全員の配列ごとに行いました。
なお、②の個体の選択では、1-3月の合計スコアから最良の個体を判定しています。
以上が今回実装した遺伝的アルゴリズムになります。
制約条件の反映
さて、ここまでのアイデアを実装すれば - 各社員が3回参加(月に1回、3ヶ月間) - 1グループあたり4-5名 - 参加者は31名
これらの制約を満たしつつ、普段あまり接点のない人どうしが同じグループになる回数をできる限り最大化できそうです。
一方で、以下の制約については別途考える必要があります。
- マネージャーどうしは同じグループにはならない(普段から接点が非常に多いので)
- メンバーの中身がほとんど同じチームは2回以上できない(今回はチームのうち3人以上が他の回と同じ組み合わせになるチームを除外)
- 3回とも同じ人と同じチームにはならない
これらの条件については、満たさないケースでは目的関数の値を大きく減らすことで、
極力これらの制約を満たさないものは選ばれないように工夫しました。
具体的には、制約を満たさないケースがある個体(たとえば、マネージャーどうしが同じグループになるケースがある個体)は、
条件を満たさなかったケースごとに目的関数のスコアを-100するようにしました。
Pythonで実装
では、ここまで説明してきたアルゴリズムをPythonで実装していきます。
1. 事前準備
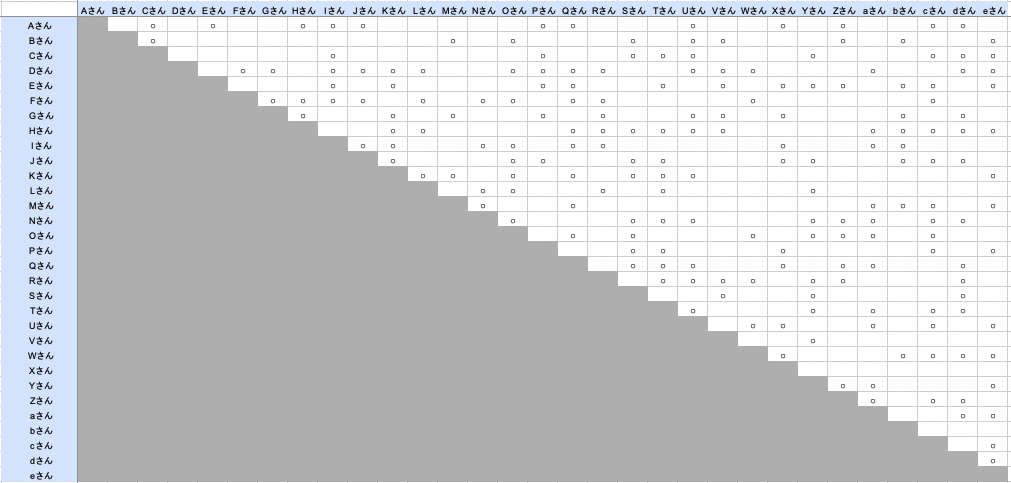
まず事前準備として、組み合わせをExcelにしてまとめておきます。
図のような表形式で、普段あまり接点がなさそうな人どうしの組み合わせに◯をつけていきました
(○はマネージャー陣につけてもらいました)。
なお、画像は本記事のために作成したダミーデータです。○は乱数をもとにつけています。
2. 必要なモジュールのimport
ではPythonでの実装に入ります。まず必要なモジュールをimportしておきます。
今回は遺伝的アルゴリズムも自前で実装するため、pandas以外に外部ライブラリは用いません。
import itertools import random import sys from collections import Counter import pandas as pd
3. チーム分け用関数の作成
はじめに、メンバーの配列を5人チームと4人チームに分割する関数を作成します。
基本的なアイデア における「② 各月で左から順に5人グループと4人グループに分割」の部分です。
たとえば、 people = ["A", "B", "C", "D", "E", "F", "G", "H", "I"] の場合は [["A", "B", "C", "D", "E"], ["F", "G", "H", "I"]] のように、引数 people を4人と5人のグループに分割した配列が返却されます。
def divide_teams(people): n = len(people) result = [] # 4人チームの最大数 max_fours = n // 4 # 5人チームと4人チームの組み合わせを検討する valid_division = False for i in range(max_fours + 1): if (n - i * 4) % 5 == 0: four_person_teams = i five_person_teams = (n - i * 4) // 5 valid_division = True break if not valid_division: raise ValueError(f"この人数({n}人)は4人チームと5人チームに分割できません") # 5人チームの分割 for _ in range(five_person_teams): team = people[:5] result.append(team) people = people[5:] # 4人チームの分割 for _ in range(four_person_teams): team = people[:4] result.append(team) people = people[4:] return result
4. 普段あまり接点がない人どうしをカウントする関数の作成
ここでは、生成されたグループのうち、普段あまり接点がない人どうしの組み合わせが何回発生しているかを計算します。
この値を最大化するのが、今回の目的になります。引数 groups は、 divide_teams 関数で生成された配列です。
また、count_good_combinations の引数 good_pairs は1.事前準備で作成したExcelにおいて○がついていたメンバーの組み合わせを格納したタプルとなっています。
def make_unique_pairs_from_groups(groups): # 全グループでのメンバー同士のユニークな全組み合わせを作成 pairs = [] for group in groups: pairs += list(itertools.combinations(group, 2)) # タプルの順番を問わずに重複ペアを削除 unique_pairs = list(set(tuple(sorted(pair)) for pair in pairs)) return unique_pairs def count_good_combinations(groups, good_pairs): # 新しい組み合わせ数を計算する関数 # 全体のペアをユニークに取得 unique_pairs = make_unique_pairs_from_groups(groups) # まだ話したことがない組み合わせの数を計算 count = 0 for pair in unique_pairs: if pair in good_pairs: count += 1 return count
5. 制約条件の追加
次に制約条件を追加していきます。
各制約条件を満たさないケースをカウントする関数になります。
まずは、マネージャーどうしが同じグループになっている件数をカウントする関数です。
引数 to_divide_members には、マネージャーの名前が入っている想定です。
def count_to_divide_combinations(groups, to_divide_members): # グループごとにペアを作成 pairs = [] for group in groups: pairs += list(itertools.combinations(group, 2)) # タプルの中身をsort sorted_pairs = list(tuple(sorted(pair)) for pair in pairs) # 分割したい人たちのペアを作成 to_divide_pairs = [ tuple(sorted(pair)) for pair in itertools.combinations(to_divide_members, 2) ] # countする count = 0 for sorted_pair in sorted_pairs: if sorted_pair in to_divide_pairs: count += 1 return count
次に、メンバーの中身がほとんど同じチームの件数をカウントする関数です。
def count_overlap_groups_over_threshold(groups, threshold): # メンバーの重複がthreshold以上のグループをカウントする # たとえば、thresholdが3の場合、3人以上が被っているグループがいくつあるかをカウント count = 0 for i in range(len(groups)): for j in range(i + 1, len(groups)): # 重複要素を見つける overlap_set = set(groups[i]) & set(groups[j]) # threshold以上の重複がある場合、カウントを増やす if len(overlap_set) >= threshold: count += 1 return count
最後に、3回とも同じ人と同じチームになった件数をカウントする関数です。
def count_multi_pairs_over_threshold(groups, threshold): # グループごとにペアを作成 pairs = [] for group in groups: pairs += list(itertools.combinations(group, 2)) # タプルの中身をsort sorted_pairs = list(tuple(sorted(pair)) for pair in pairs) # 重複をカウント # threshold以上同じグループになったペアをカウント counter = Counter(sorted_pairs) return sum(1 for count in counter.values() if count >= threshold)
以上の関数をもとに、これらのケースができる限り起こらないような目的関数を作成していきます。
6. 制約を加えた目的関数の設定
それでは、制約を加えた最終的な目的関数を定義します。遺伝的アルゴリズムでは、このスコアが最大になるように解を探索していきます。
制約条件を満たさない場合は、 penalty_score を乗算して1件につきスコアを-100する設計にしています。
これによって、これらの制約条件をできる限り満たしながら、普段あまり接点がない人どうしの組み合わせを最大化できます。
なお、後ほど引数で渡しますが、今回 multi_pair_threshold は3(3回とも同じ人と同じになることは避ける)、 overlap_threshold も3(3人以上同一メンバーが含まれるチームの生成は避ける)にしています。
def calculate_score( groups, good_pairs, to_divide_members, multi_pair_threshold, overlap_threshold, penalty_score=100, ): # 普段あまり接点がない人どうしの組み合わせをカウント good_count = count_good_combinations(groups, good_pairs) # 分割したい人たち(マネージャー陣)のペアをカウント to_divide_count = count_to_divide_combinations(groups, to_divide_members) # 一定回数以上同じペアをカウント(例: ランチ会3回中3回とも同じ人と同じ) multi_pair_count = count_multi_pairs_over_threshold( groups, multi_pair_threshold ) # ほとんど同じグループをカウント(例: メンバー4人中3人が、前回と同じ人たち) overlap_groups_count = count_overlap_groups_over_threshold( groups, overlap_threshold ) return ( good_count - to_divide_count * penalty_score - multi_pair_count * penalty_score - overlap_groups_count * penalty_score )
7. 遺伝的アルゴリズムの実装
これで準備が整いましたので、遺伝的アルゴリズムを実装していきます。
まず、遺伝的アルゴリズムの計算に必要な要素となる関数を定義します。
def initialize_population(size, employee_list, lunch_session_times): # 初期の個体群をランダムに生成。「① 初期個体をランダムにN個生成」に相当。 return [ [ random.sample(employee_list, len(employee_list)) for i in range(lunch_session_times) ] for _ in range(size) ] def evaluate_solution( solution, good_pairs, to_divide_members, multi_pair_threshold, overlap_threshold, ): # 個体のスコアを評価する groups = [] for solution_per_session in solution: groups += divide_teams(solution_per_session) return calculate_score( groups, good_pairs, to_divide_members, multi_pair_threshold, overlap_threshold, ) def select_parents(population, scores): # ベストスコアの2個体を選別 # 「② N個の個体からスコアの良い個体を2個選択」に相当 parents = sorted(zip(population, scores), key=lambda x: x[1], reverse=True) return [parents[i][0] for i in range(2)] def crossover(parent1, parent2): # 実施月ごとに交差を実施 child1 = [] child2 = [] for session_time in range(len(parent1)): # 一点で交叉 idx = random.randint(0, len(parent1[session_time]) - 1) child1.append( parent1[session_time][:idx] + [ x for x in parent2[session_time] if x not in parent1[session_time][:idx] ] ) child2.append( parent2[session_time][:idx] + [ x for x in parent1[session_time] if x not in parent2[session_time][:idx] ] ) return child1, child2 def mutate(child, mutation_rate): # 一定の確率で2点間の位置をスワップ for session_time in range(len(child)): for i in range(len(child[session_time])): if random.random() < mutation_rate: swap_idx = random.randint(0, len(child[session_time]) - 1) child[session_time][i], child[session_time][swap_idx] = ( child[session_time][swap_idx], child[session_time][i], ) return child
では、いよいよこれらの関数を用いて遺伝的アルゴリズムを実行しましょう。
# 設定値 population_size = 100 # 世代ごとに生成する個体数。 generations = 1000 # 変異と交叉を繰り返す回数 mutation_rate = 0.01 # 変異が発生する確率 lunch_session_times = 3 # ランチセッションの開催回数 overlap_threshold = 3 # N人以上重複するグループを避ける際のN # 実行 population = initialize_population( population_size, employee_list, lunch_session_times ) best_solution = None best_score = -sys.maxsize for generation in range(generations): scores = [ evaluate_solution( solution, good_pairs, to_divide_members, lunch_session_times, overlap_threshold, ) for solution in population ] if max(scores) > best_score: best_score = max(scores) best_solution = population[scores.index(best_score)] parents = select_parents(population, scores) new_population = [] for i in range(population_size // 2): child1, child2 = crossover(parents[0], parents[1]) new_population.append(mutate(child1, mutation_rate)) new_population.append(mutate(child2, mutation_rate)) population = new_population
この計算によって、制約条件をできる限り満たしながら、普段あまり接点がない人どうしの組み合わせをできる限り最大化した結果が得られました。
それでは、次のセクションで実行結果をご紹介します。
実行結果
ここでは、本記事用のダミーデータでの実行結果を記載します。
マネージャーはAさん~Gさんの7名と想定しています。
実際に分割されたメンバーリスト
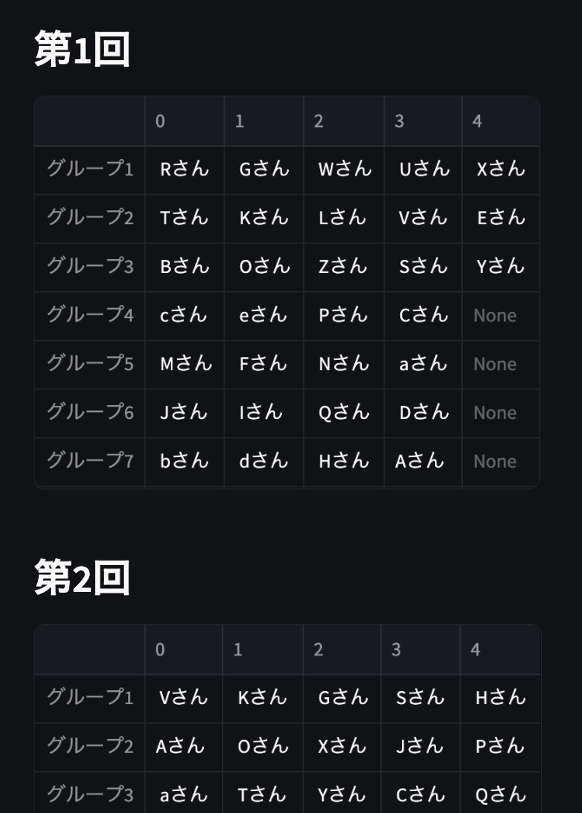
まずは、遺伝的アルゴリズムで得られたグループを見てみましょう。
マネージャーは太字にしています
第1回(1月)
| グループ | メンバー1 | メンバー2 | メンバー3 | メンバー4 | メンバー5 |
|---|---|---|---|---|---|
| グループ1 | Rさん | Gさん | Wさん | Uさん | Xさん |
| グループ2 | Tさん | Kさん | Lさん | Vさん | Eさん |
| グループ3 | Bさん | Oさん | Zさん | Sさん | Yさん |
| グループ4 | cさん | eさん | Pさん | Cさん | |
| グループ5 | Mさん | Fさん | Nさん | aさん | |
| グループ6 | Jさん | Iさん | Qさん | Dさん | |
| グループ7 | bさん | dさん | Hさん | Aさん |
第2回(2月)
| グループ | メンバー1 | メンバー2 | メンバー3 | メンバー4 | メンバー5 |
|---|---|---|---|---|---|
| グループ1 | Vさん | Kさん | Gさん | Sさん | Hさん |
| グループ2 | Aさん | Oさん | Xさん | Jさん | Pさん |
| グループ3 | aさん | Tさん | Yさん | Cさん | Qさん |
| グループ4 | eさん | bさん | Bさん | Mさん | |
| グループ5 | Lさん | Rさん | Iさん | Fさん | |
| グループ6 | dさん | Wさん | Uさん | Dさん | |
| グループ7 | Nさん | Zさん | cさん | Eさん |
第3回(3月)
| グループ | メンバー1 | メンバー2 | メンバー3 | メンバー4 | メンバー5 |
|---|---|---|---|---|---|
| グループ1 | Nさん | Sさん | Pさん | Gさん | Jさん |
| グループ2 | Aさん | Kさん | Zさん | Mさん | Qさん |
| グループ3 | Yさん | Dさん | Lさん | Vさん | Rさん |
| グループ4 | Uさん | Tさん | Bさん | Hさん | |
| グループ5 | aさん | dさん | Cさん | eさん | |
| グループ6 | Xさん | Eさん | Iさん | bさん | |
| グループ7 | Oさん | Fさん | cさん | Wさん |
マネージャーが毎回7チームに分散しており、同じようなチームもなく、うまくチーム分けがなされているように見えます。
検算したところ、実際にこのチーム分けは、制約条件を全て満たしていました。
更に全194件の普段あまり接点がない人どうしの組み合わせのうち、118件の組み合わせを実現できています!
最適化の時間推移
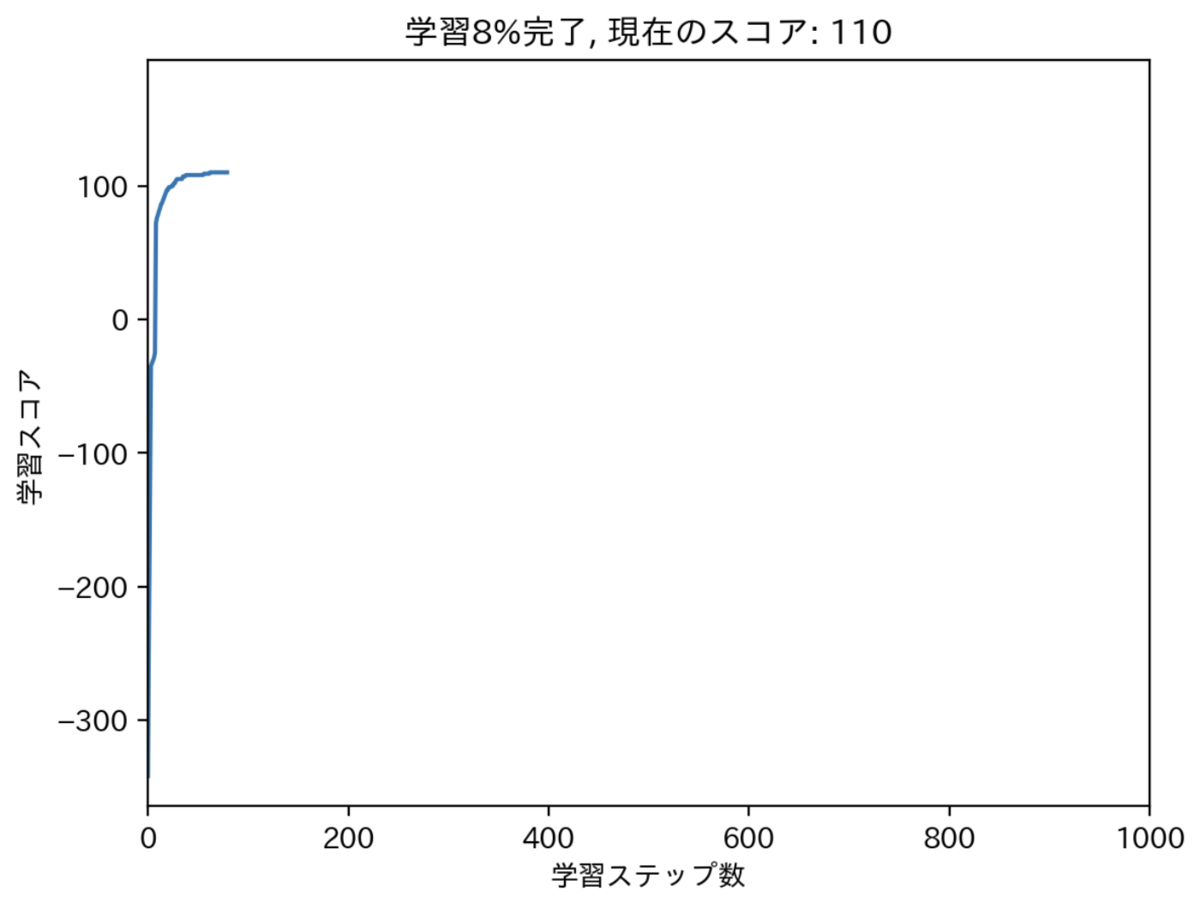
では、最適化によってスコアがどのように推移したかを見てみましょう。

横軸は学習ステップ数(世代数)、縦軸は学習スコア(各世代のbest_score)を表しています。
序盤に大きくスコアが改善し(制約条件を満たさないケースが淘汰されています)、200ステップ以降はほとんどスコアに変動がありません。
今回のケースでは、200世代程度でも十分に良い解が導けていたということになります。
ランダム探索との比較
では、今回の学習で遺伝的アルゴリズムを利用せず、ランダムに探索した場合は結果がどうなるかを検証して結果の考察を終えたいと思います。
ここではランダムにメンバーをシャッフルした個体を評価し、最もスコアの高い個体を選択します。
今回は各世代の個体が100で、世代が1,000だったため、100×1,000=100,000通りをランダムに探索してみました。
その結果、遺伝的アルゴリズムが実現できた普段あまり接点のない人どうしの組み合わせは118件だったのに対し、ランダムに探索した場合は77件となりました
(制約条件は全て満たせていました)。
遺伝的アルゴリズムの方が35%も実現できた組み合わせ数が多く、解の効率的な探索に有効であったことがわかります。
引き継ぎのためにStreamlitでUIを作成
今回は私が実際にPythonコードを動作させて組み合わせを決めましたが、今後もランチ会を実施する際に非エンジニアでもこのアルゴリズムを動かせるように、StreamlitでUIを実装しました。
コードの詳細は省略しますが、簡単にUIをご紹介したいと思います。
まず、普段接点がなさそうな人の組み合わせに◯をつけたExcelファイルをアップロードします。

次に、マネージャーを選択します。選択肢はアップロードしたExcelファイルに含まれる人名が表示されます。

最後にランチ会の開催回数を入力して、計算実行ボタンを押すと最適化計算が開始されます。
計算中は学習が進む様子をビジュアルで確認できるようにしました。
計算が終わると、アルゴリズムが導き出した最適なグループのリストが表形式で表示されます。
(以降のグループは省略)
このように簡易なUIにすることで、非エンジニアの方でも気軽にグループ分けを実施できるようになりました。
まとめ
かなりボリュームのある記事になりましたが、最後までお読みいただきありがとうございます。
もし同じような課題を抱えている方がいれば、本記事を参考にしていただけると嬉しいです。
また、Insight Edgeはランチ会のグループ分けでも技術的なチャレンジが自由にできる、データサイエンティストの技術を存分に発揮できる環境です。
Insight Edgeに興味を持たれた方は、ぜひ 公式サイト の採用ページからカジュアル面談をお申し込みください!