こんにちは!Insight EdgeのData Scientistの石倉です。私は以前、地球物理学を専攻していて偏微分方程式を扱っていたのですが、最近NeurIPSやその他学会などで見られるPhysics-informed neural networks(以下、PINNs)の"Physics"に思わずアンテナが反応してしまい、色々と文献を調査してみました。そこで今回は、簡単に解析解の分かる微分方程式を用いてPINNsをTensorflowで実装してみたのでご紹介したいと思います!
- Physics-informed neural networks とは
- 減衰振動 微分方程式
- Finite difference method
- Data-driven neural networks
- Physics-informed neural networks
- まとめ
- 感想
- 参考文献
- 参考:実装コード
Physics-informed neural networks とは
科学や工学における多くの現象は偏微分方程式(以下、PDE)で記述され、複雑な現象を再現するために数値計算法を用いて様々な分野でシミュレーションが行われています。解析解を直接得られる一部の微分方程式を除いて、多くの方程式は有限差分法や有限要素法などの数値計算法を用いて近似的に解く必要があり、連続関数を離散化してグリッドに分割し膨大な数の繰り返し計算が必要となります。近年ディープラーニング技術を用いて、PDEを解く有効な手段としてPINNsが注目されており、MLの有名どころの学会に留まらず物理学系の学会などでも論文が多数見受けられ研究が活発に行われています。
PINNsの目的は一言で表すと、観測対象のPDEの解を観測データと物理モデル両者を考慮して近似的に求めることです。PINNs内のNeural Network(以下、NN)の構造はMLPで構成されており、NNのもつUniversal Approximation Theoremでは、”有限個のユニットを持つ一層の隠れ層で構成されるfeed-forward networkは、任意の連続関数を近似することが出来る”ということが保証されています。また、Activation functionがSquashing functionの時はMLPにおいてもこの定理が保証されています。PINNsはこの定理の性質を用いてPDEの近似関数を求めていくことになります。
PINNsの火付け役となった論文はRaissi et al.(2019)で、流体力学で用いられるNavier–Stokes equationに対してPINNsを適用した論文となっています。本稿ではいきなりNavier-Stokesのような非線形偏微分方程式を扱うと難易度が高いので、解析解の分かる簡単なマス-バネ-ダンパー系の減衰振動の微分方程式を扱うことにします。また、数値計算法とPINNsを比較したいと思います。
減衰振動 微分方程式
下図のようにマスの質量を, バネ定数を
, ダンパーの減衰係数を
とするとマス-バネ-ダンパー系の運動方程式は式
のように記述できます。また初期条件については、時刻
の時に
, 速度
とした時の解析解は式
のようになります。
初期条件:
解析解:

Finite difference method
今回は、マス-バネ-ダンパー系の運動方程式、式を数値計算法の1つである有限差分法を用いてシミュレーションを作成しました。運動方程式には時刻
による微分項が含まれるので、テーラー展開の一次精度(オイラー法)を用いて離散化を行います。式
中の
は十分に小さいものとします。
ここで、簡単にを
と変化させて、シミュレーション結果と解析解と比較したものが下図になります。
が大きくなると誤差が増大して、
の時には発散している様子がわかります。これはテーラー展開を行なって1次精度で近似して2次以降の項を打ち切ったことによる誤差が
に応じて大きくなっているためです。連続関数を離散化している以上、数値計算による誤差は避けられませんが、誤差を無視できる程度まで
を十分に小さくしようとすると、トレードオフで計算量は増大します。

Data-driven neural networks
Raissi et al. (2019)の論文内でもData driven neural networks(以下、DDNNs)についての記載があったので、本稿でも簡単に記載します。Data drivenなので文字通り、データのみを用いて観測データと予測データの誤差を最小化するようにNNを学習していくものです。NNの構造はMLPです。下のGIF画像を見ての通り、当然ながらデータの存在しない区間では近似は不可能ですが、データの観測されている区間においては非常によく近似できていることがわかります。
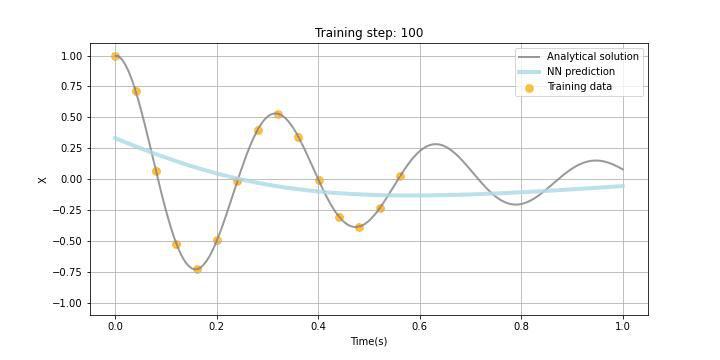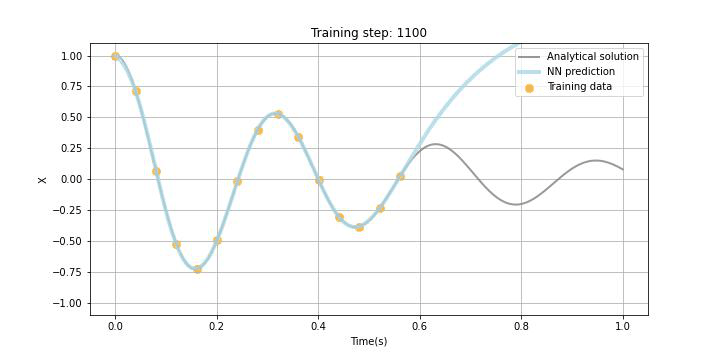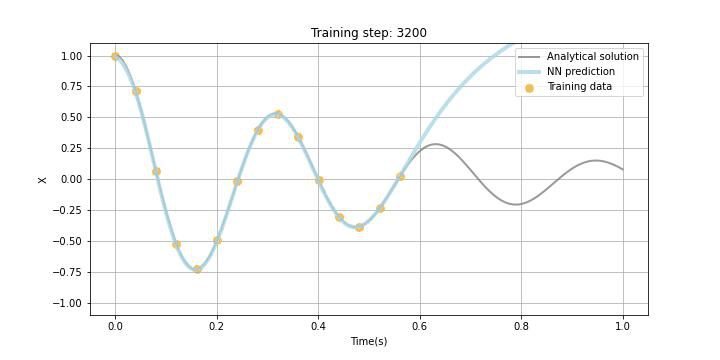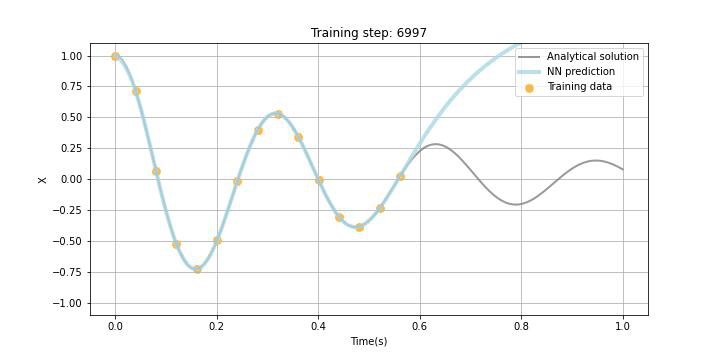
Physics-informed neural networks
本題のPINNsです。NNの構造はDDNNsと同じですがLossの構成が異なり、PINNsでは観測データと予測データの誤差、境界条件誤差、微分方程式誤差で構成されます(今回は境界条件誤差はありません。)。この微分方程式誤差がPhysics-informedと呼ばれる所以ですが、NNを学習する際に用いられるバックプロパゲーションを用いて勾配を計算することが可能(自動微分)なので、この機能を用いて方程式中の微分項を学習できます。以下に、Tensorflowの例を記していますが、シミュレーターを作成することと比較すると、実装が非常に簡単というのもPINNsの特徴かと思います。今回は時間微分項しかないので、シミュレーションも簡単ですが、空間微分を含む微分方程式を扱うとシミュレーターの実装は複雑になります。
def train_step(self, t_data, x_data, t_pinn, c, k): with tf.GradientTape() as tape_total: tape_total.watch(self._model.trainable_variables) x_pred = self._model(t_data) loss1 = self._loss_fn(x_pred, x_data) #観測データ誤差 loss1 = tf.cast(loss1, dtype=tf.float32) with tf.GradientTape() as tape2: tape2.watch(t_pinn) with tf.GradientTape() as tape1: tape1.watch(t_pinn) x_pred_pinn = self._model(t_pinn) dx_dt = tape1.gradient(x_pred_pinn, t_pinn) #1階微分 dx_dt2 = tape2.gradient(dx_dt, t_pinn) #2階微分 dx_dt = tf.cast(dx_dt, dtype=tf.float32) dx_dt2 = tf.cast(dx_dt2, dtype=tf.float32) x_pred_pinn = tf.cast(x_pred_pinn, dtype=tf.float32) loss_physics = dx_dt2 + c * dx_dt + k * x_pred_pinn loss2 = 5.0e-4 * self._loss_fn(loss_physics, tf.zeros_like(loss_physics)) loss2 = tf.cast(loss2, dtype=tf.float32) loss = loss1 + loss2 # Lossの合算 self._optimizer.minimize(loss, self._model.trainable_variables, tape=tape_total) self._loss_values.append(loss) return self
今回、あえて試験的に観測データをスパースに5点ランダムに選び、観測データLossに組み込みました。また、Physics lossの学習データポイントはxで示しており、今回は1.0sまでの区間において学習することとしました。勿論この学習区間は任意に設定可能ですが、学習区間を広く取りすぎると収束までにより多くの時間を要したり、扱う微分方程式によっては上手く学習できないこともあることが論文などでも報告されています。

下のGIF画像に学習の過程を記していますが、観測データがある区間だけでなく観測データの欠損区間及び観測されていない未来の区間でも微分方程式誤差の最小化に伴って、上手く学習できている様子が見て取れるかと思います。
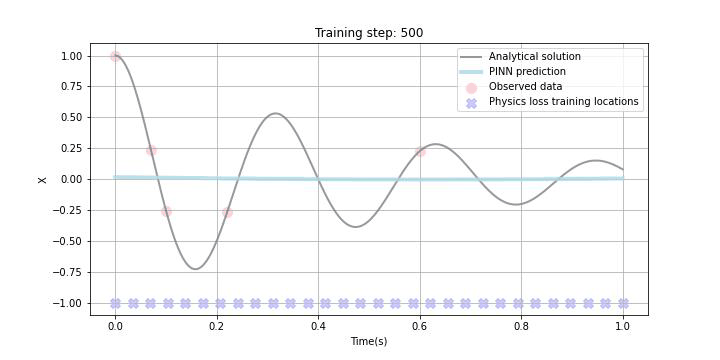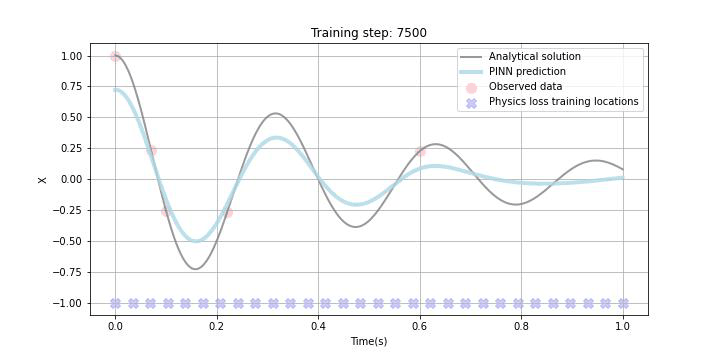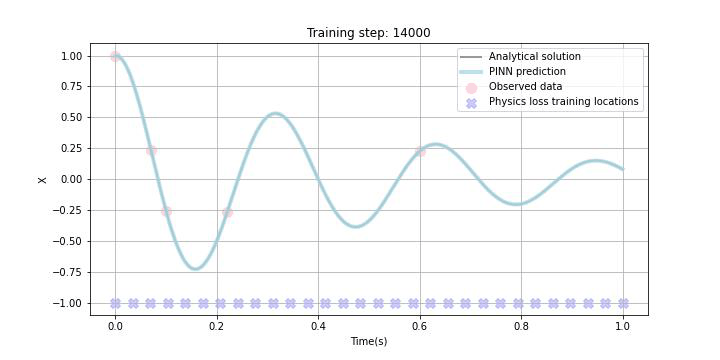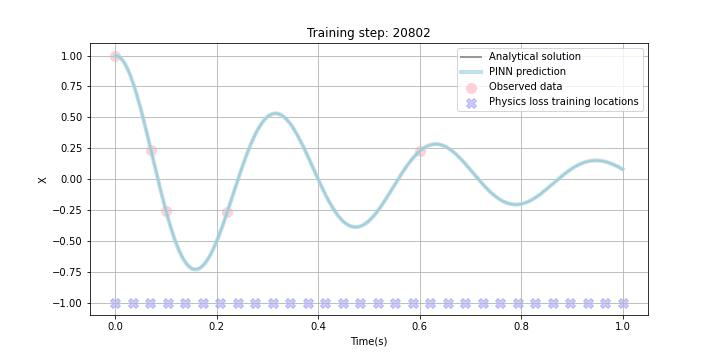
まとめ
減衰振動の微分方程式を用いてシミュレーション/DDNNs/PINNsを作ってみたので、それぞれの精度について検証してみたいと思います。精度検証については、解析解との平均絶対値誤差で評価しています。
| FD (dt=0.005) |
FD (dt=0.001) |
FD (dt=5.0e-5) |
DDNNs (データ区間に限る) |
PINNs |
|---|---|---|---|---|
| 0.130 | 0.0203 | 9.63e-4 | 3.32e-3 | 9.64e-4 |
FD vs. NeuralNetwork
上記表の結果からDDNNsやPINNsほどの精度をシミュレーションで追求しようとすると時間間隔をかなり小さく取る必要があり、その分計算回数をかなり多く要します。今回は簡単な例を用いたシミュレーションなので計算負荷についての議論は難しいです。しかし一般的に、今回の様な陽的数値解法でも大きなモデルをシミュレーションする場合、時間間隔を小さく設計するとかなりの計算負荷がかかることを予想されます。また、陰的数値解法では陽的解法に比べて数値計算的に安定しやすく、時間間隔を比較的粗く設計しても精度が落ちにくいという点がありますが、時間間隔毎に逆行列を計算する必要があるので同様に計算負荷が大きいという問題もあります。PINNsについては、複雑な微分方程式の近似関数や学習領域を広範囲に設計すると、その分レイヤー数やユニット数を増やす必要があり収束に時間を要すると予想されるので、一概にどちらの手法が計算コストを低くできるかというのは難しいと感じています。
PINNsのメリットとして、観測現象の微分方程式を離散化していないので、シミュレーションの様に空間グリッド間隔や時間間隔に縛られず、任意の空間及び時間の観測データを制約条件として利用できる点、上手く収束すれば学習領域内においては任意の空間及び時間の挙動を把握できる点が挙げられると考えています。
PINNsのデメリットとして、解析解の分からないような複雑な現象を学習する際の収束をどのように判断するかが非常に難しいと感じています。今回の例で試験的に観測データを極端に少なくして試行しましたが、学習が上手くいかなかった際は振幅誤差だけでなく、位相ズレも見られました。
DDNNs vs. PINNs
DDNNsは、物理学的な要素は何も含まれていないので、良い近似関数を求めるためには多分に観測データが必要になるという点が挙げられます。一方、PINNsではPhysics lossが組み込まれているので、DDNNsに比べて観測データ点が少なくとも学習が可能である点、観測データの無い未来の挙動も学習可能である点は興味深いと感じています。
論文紹介
様々な分野においてPINNsの適用が見られますが、現時点で扱う微分方程式によってそれぞれ適切なOptimizerやActivation function、Lossの設計(L1 or L2 norm)、学習手法が異なり、画一的に万能な手法はなさそうです。先述の火付け役となった論文Raissi et al.(2019)と同様にKrishnapriyan et al.(2021)では流体力学系の偏微分方程式に対して様々な検証を行なっています。例えば、移流方程式においては通常のやり方では時間方向の学習を上手くできないので、Curriculum learningという簡単な偏微分方程式から学習を始めて徐々に目的の偏微分方程式へと近づけていく手法を取ったり、時間方向の学習領域をある程度区切って学習を行なう手法を用いたりと様々な工夫を行なっています。また一般的にNNの学習でOptimizerはAdamを用いられることが多いですが、この論文ではAdamは機能せずL-BFGSを用いたようです。Activation functionはhyperbolic tangentを使っています。


Moseley et al.(2020)では、波動方程式に対して適用を行なっており、従来のシミュレーションでよく用いられるFDとDDNNs、PINNsの比較などを行なっています。この論文では、OptimizerにはAdamを、LossはL1 norm、Activation functionはsoftplus、学習方法としては、初期はDDNNsで学習を進めていき、途中からPhysics lossを組み込むといった手法を取っています。Activation functionについては連続関数を近似することが目的なので、PINNsではReluのような微分がステップ関数となるようなものはあまり用いられていない印象です。

Huang et al.(2022)はPINNsの調査論文で、参考文献が200本以上掲載されており、体系立ててまとめられているので、PINNsの基礎から最近のPINNsの動向まで幅広く知りたい方にはおすすめかと思います。
感想
今回実際に作ってみた感想として、純粋に実装のみの観点からお話しすると、TensorflowやPytorchのおかげでNNの構築、自動微分による勾配計算が非常に容易である点は大きく、空間微分と時間微分を含む微分方程式のシミュレーターを作成することに比べると作業量もかなり少ないと感じました。また、実際に試行してみてPINNsの面白さを実感できた点はよかったです。末尾に実装コードを掲載していますのでご参考まで。論文紹介でも述べたとおり、現状様々な学習手法が試されており、解析解や従来手法との比較の論文が多い印象ですが、今後さらに研究が進んでいくことを期待して引き続き動向を追っていきたいと思います!
参考文献
A. Krishnapriyan, A. Gholami, S. Zhe, R. Kirby and M. Mahoney, "Characterizing possible failure modes in physics-informed neural networks" 35th Conference on Neural Information Processing Systems (NeurIPS 2021).
B. Moseley, A. Markham and T. Nissen-Meyer, "Solving the wave equation with physics-informed deep learning"
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal of Computational Physics, vol. 378, pp. 686–707, 2019.
S. Huang, W. Feng, C. Tang, Z. He, C. Yu, and J. Lv, "Partial Differential Equations Meet Deep Neural Networks: A Survey"
参考:実装コード
動作確認済みですが、グラフ描画については省略しています。以下ご参考まで。
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt def FDM(init_x, init_v, init_t, gamma, omega ,dt, T): ''' init_x :マスの初期位置 init_v :マスの初期速度 init_t :マスの初期時刻 gamma :ダンパーの減衰係数 / (2.0 * マスの質量) -> マス質量は1.0と仮定 omega :周波数 ''' # parameter x = init_x v = init_v t = init_t g, w0 = gamma, omega num_iter = int(T/dt) alpha = np.arctan(-1*g/np.sqrt(w0**2 - g**2)) a = np.sqrt(w0**2 * x**2 / (w0**2 - g**2)) # data array t_array = [] x_array = [] v_array = [] x_analytical_array = [] diff_array = [] # time step loop for i in range(num_iter): fx = v fv = -1*w0**2 * x - 2*g * v x = x + dt * fx v = v + dt * fv t = t + dt x_a = a * np.exp(-1*g * t) * np.cos(np.sqrt(w0**2 - g**2) * t + alpha) diff = x_a - x t_array.append(t) x_array.append(x) x_analytical_array.append(x_a) v_array.append(v) diff_array.append(diff) return t_array, x_array, v_array, x_analytical_array, diff_array def analytical_solution(g, w0, t): ''' g :ダンパーの減衰係数 / (2.0 * マスの質量) -> マス質量は1.0と仮定 w0 :周波数 t :tf.linespace ''' assert g <= w0 w = np.sqrt(w0**2-g**2) phi = np.arctan(-g/w) A = 1/(2*np.cos(phi)) cos = tf.math.cos(phi+w*t) sin = tf.math.sin(phi+w*t) exp = tf.math.exp(-g*t) x = exp*2*A*cos return x def MLP(n_input, n_output, n_neuron, n_layer, act_fn='tanh'): tf.random.set_seed(1234) model = tf.keras.Sequential([ tf.keras.layers.Dense( units=n_neuron, activation=act_fn, kernel_initializer=tf.keras.initializers.GlorotNormal(), input_shape=(n_input,), name='H1') ]) for i in range(n_layer-1): model.add( tf.keras.layers.Dense( units=n_neuron, activation=act_fn, kernel_initializer=tf.keras.initializers.GlorotNormal(), name='H{}'.format(str(i+2)) )) model.add( tf.keras.layers.Dense( units=n_output, name='output' )) return model class EarlyStopping: def __init__(self, patience=10, verbose=0): ''' Parameters: patience(int): 監視するエポック数(デフォルトは10) verbose(int): 早期終了の出力フラグ 出力(1),出力しない(0) ''' self.epoch = 0 # 監視中のエポック数のカウンターを初期 self.pre_loss = float('inf') # 比較対象の損失を無限大'inf'で初期化 self.patience = patience # 監視対象のエポック数をパラメーターで初期化 self.verbose = verbose # 早期終了メッセージの出力フラグをパラメーターで初期化 def __call__(self, current_loss): ''' Parameters: current_loss(float): 1エポック終了後の検証データの損失 Return: True:監視回数の上限までに前エポックの損失を超えた場合 False:監視回数の上限までに前エポックの損失を超えない場合 ''' if self.pre_loss < current_loss: # 前エポックの損失より大きくなった場合 self.epoch += 1 # カウンターを1増やす if self.epoch > self.patience: # 監視回数の上限に達した場合 if self.verbose: # 早期終了のフラグが1の場合 print('early stopping') return True # 学習を終了するTrueを返す else: # 前エポックの損失以下の場合 self.epoch = 0 # カウンターを0に戻す self.pre_loss = current_loss # 損失の値を更新す return False class DataDrivenNNs(): def __init__(self, n_input, n_output, n_neuron, n_layer, epochs, act_fn='tanh'): ''' n_input : インプット数 n_output : アウトプット数 n_neuron : 隠れ層のユニット数 n_layer : 隠れ層の層数 act_fn : 活性化関数 epochs : エポック数 ''' self.n_input = n_input self.n_output = n_output self.n_neuron = n_neuron self.n_layer = n_layer self.epochs = epochs self.act_fn = act_fn def build(self, optimizer, loss_fn, early_stopping): self._model = MLP(self.n_input, self.n_output, self.n_neuron, self.n_layer, self.act_fn) self._optimizer = optimizer self._loss_fn = loss_fn self._early_stopping = early_stopping return self def train_step(self, t_data, x_data): with tf.GradientTape() as tape: x_pred = self._model(t_data) loss = self._loss_fn(x_pred,x_data) self._gradients = tape.gradient(loss,self._model.trainable_variables) self._optimizer.apply_gradients(zip(self._gradients, self._model.trainable_variables)) self._loss_values.append(loss) return self def train(self, t, x, t_data, x_data): self._loss_values = [] for i in range(self.epochs): self.train_step(t_data, x_data) if self._early_stopping(self._loss_values[-1]): break class PhysicsInformedNNs(): def __init__(self, n_input, n_output, n_neuron, n_layer, epochs, act_fn='tanh'): ''' n_input : インプット数 n_output : アウトプット数 n_neuron : 隠れ層のユニット数 n_layer : 隠れ層の層数 act_fn : 活性化関数 epochs : エポック数 ''' self.n_input = n_input self.n_output = n_output self.n_neuron = n_neuron self.n_layer = n_layer self.epochs = epochs self.act_fn = act_fn def build(self, optimizer, loss_fn, early_stopping): self._model = MLP(self.n_input, self.n_output, self.n_neuron, self.n_layer, self.act_fn) self._optimizer = optimizer self._loss_fn = loss_fn self._early_stopping = early_stopping return self def train_step(self, t_data, x_data, t_pinn, c, k): with tf.GradientTape() as tape_total: tape_total.watch(self._model.trainable_variables) x_pred = self._model(t_data) loss1 = self._loss_fn(x_pred, x_data) loss1 = tf.cast(loss1, dtype=tf.float32) with tf.GradientTape() as tape2: tape2.watch(t_pinn) with tf.GradientTape() as tape1: tape1.watch(t_pinn) x_pred_pinn = self._model(t_pinn) dx_dt = tape1.gradient(x_pred_pinn, t_pinn) dx_dt2 = tape2.gradient(dx_dt, t_pinn) dx_dt = tf.cast(dx_dt, dtype=tf.float32) dx_dt2 = tf.cast(dx_dt2, dtype=tf.float32) x_pred_pinn = tf.cast(x_pred_pinn, dtype=tf.float32) loss_physics = dx_dt2 + c * dx_dt + k * x_pred_pinn loss2 = 5.0e-4 * self._loss_fn(loss_physics, tf.zeros_like(loss_physics)) loss2 = tf.cast(loss2, dtype=tf.float32) loss = loss1 + loss2 self._optimizer.minimize(loss, self._model.trainable_variables, tape=tape_total) self._loss_values.append(loss) return self def train(self, t, x, t_data, x_data, t_pinn, c, k): self._loss_values = [] for i in range(self.epochs): self.train_step(t_data, x_data, t_pinn, c, k) if self._early_stopping(self._loss_values[-1]): break if __name__ == "__main__": ################## Finite difference method ################## _,_,_,_,diff_00005 = FDM(1.0, 0.0, 0.0, 2.0, 20.0, 0.00005, 1.0) gt_001,gx_001,_,gx_a,diff_001 = FDM(1.0, 0.0, 0.0, 2.0, 20.0, 0.001, 1.0) gt_005,gx_005,_,_,diff_005 = FDM(1.0, 0.0, 0.0, 2.0, 20.0, 0.005, 1.0) gt_01,gx_01,_,_,diff_015 = FDM(1.0, 0.0, 0.0, 2.0, 20.0, 0.015, 1.0) ################ Data-driven neural networks ################ g, w0 = 2, 20 c, k = 2*g, w0**2 t = tf.linspace(0,1,500) t = tf.reshape(t,[-1,1]) x = analytical_solution(g, w0, t) x = tf.reshape(x,[-1,1]) # Data points datapoint_list = [i for i in range(0,300,20)] t_data = tf.gather(t, datapoint_list) x_data = tf.gather(x, datapoint_list) DDNNs = DataDrivenNNs(1,1,32,4,5000) optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3) loss_fn = tf.keras.losses.MeanSquaredError() early_stopping = EarlyStopping(patience=200,verbose=1) DDNNs.build(optimizer, loss_fn, early_stopping) DDNNs.train(t,x,t_data,x_data) ############## Physics-informed neural networks ############## t_pinn = tf.linspace(0,1,30) t_pinn = tf.reshape(t_pinn,[-1,1]) # Random data points random_list = [0,35,50,110,300] t_data = tf.gather(t, random_list) x_data = tf.gather(x, random_list) PINNs = PhysicsInformedNNs(1,1,32,4,50000) optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3) loss_fn = tf.keras.losses.MeanSquaredError() early_stopping = EarlyStopping(patience=200,verbose=1) PINNs.build(optimizer, loss_fn, early_stopping) PINNs.train(t, x, t_data, x_data, t_pinn, c, k)