目次
1. はじめに
こんにちは。Insight Edge で Developer をしている熊田です。
普段システム開発を進める上で、システムの利用者数や頻繁に利用されている機能を調べたいと思うことはありませんか?
特にPoC検証やシステム運用フェーズにおいては、そのようなニーズが多くあるのではないでしょうか。
そのようなニーズに応えるためには、ログを収集する必要があります。また、上記のようなニーズはプロジェクト共通のものであることが多いかと思います。
これら要望に応えるために、GCP の複数プロジェクトにまたがるログ収集及び可視化をするためのロギング基盤を検証構築してみたので、その紹介をしたいと思います。
2. ログデータの収集
GCP インフラ構成の説明
まず、インフラ構成図は以下の通りです。
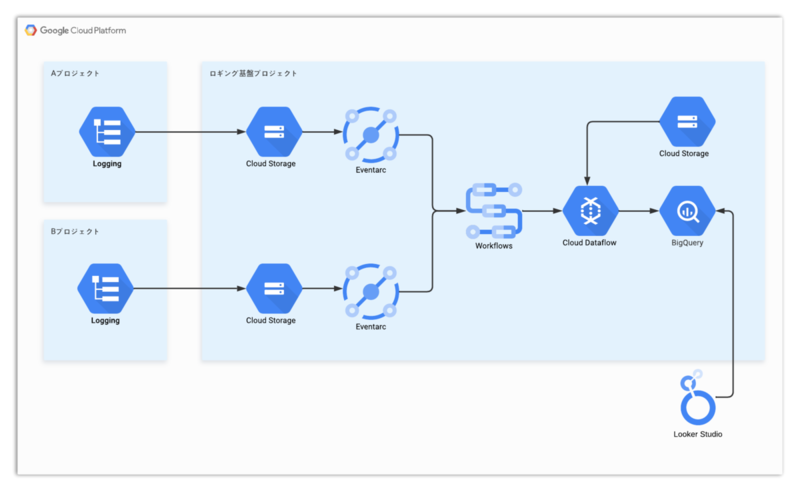
簡単に構成を説明します。
① 各プロジェクトにて Cloud Logging にログを出力することを前提としています。
② ログ Sync を作成しフィルタ機能を利用して必要なログのみ、ログ収集用プロ
ジェクトの Cloud Storage(以下GCS) にログを転送します(1時間毎)。
③ Eventarc を利用して、GCS にログが転送されたことをトリガーに Workflows を
起動します。
④ Workflows にて、定義済みの Dataflow を実行し、ログを BigQuery に格納します。
なお、Dataflow 実行時に必要なファイル群は GCS に格納しています。
⑤ BigQuery に格納されたログデータを Looker Studio で可視化します。
各サービスの設定
基本的には Terraform コードを利用し、一部は GCP コンソール作業やシェルスクリプト作業をしています。以下に実装詳細を記載します。
ディレクトリ構成
.
├── BQ
│ └── create_table.sql
├── logger_sync
│ ├── sample_service_A
│ │ └── create-sync.sh
│ └── sample_service_B
│ └── create-sync.sh
└── terraform
├── env
│ ├── dev
│ │ ├── common
│ │ │ ├── common.tfvars
│ │ │ ├── dataflow_config
│ │ │ │ ├── schema
│ │ │ │ │ └── usage_log.json
│ │ │ │ └── udf
│ │ │ │ └── transform.js
│ │ │ ├── main.tf
│ │ │ ├── variables.tf
│ │ │ └── workflow.yaml
│ │ ├── sample_service_A
│ │ │ ├── main.tf
│ │ │ ├── sample_service_A.tfvars
│ │ │ └── variables.tf
│ │ └── sample_service_B
│ │ ├── main.tf
│ │ ├── sample_service_B.tfvars
│ │ └── variables.tf
│ └── prd
└── modules
├── aws
├── azure
└── gcp
├── eventarc
│ ├── main.tf
│ └── variables.tf
└── gcs
├── main.tf
├── output.tf
└── variables.tf
共通リソースの作成
まずは、共通で利用するリソースを以下の通り作成していきます。
BigQuery
今回は BigQuery テーブルをコンソールから作成していきます。 データセットを作成し、その後クエリエディタに以下のステートメントを入力および実行してテーブルを作成します。
./BQ/create_table.sql
CREATE TABLE `[project].sample_dataset.usage_log` ( timestamp TIMESTAMP NOT NULL OPTIONS(description="ログ日時"), service_name STRING NOT NULL OPTIONS(description="サービス名"), user_id STRING NOT NULL OPTIONS(description="ユーザID"), activity_name STRING NOT NULL OPTIONS(description="アクティビティ名") ) PARTITION BY TIMESTAMP_TRUNC(timestamp, DAY)
各種 Terraform ファイル
./terraform/env/dev/common/common.tfvars
project_id = [ロギング基盤プロジェクトのプロジェクトID] default_region = "asia-northeast1" prefix = "logging-common" env = "dev"
./terraform/env/dev/common/variables.tf
variable "project_id" {} variable "default_region" {} variable "prefix" {} variable "env" {}
./terraform/env/dev/common/main.tf
## Provider ## provider "google" { project = var.project_id region = var.default_region } locals { dataflow_config_files = [ "schema/usage_log.json", "udf/transform.js" ] } ## GCS ## resource "google_storage_bucket" "bucket" { name = "dataflow-config-${var.env}-${var.prefix}" location = var.default_region project = var.project_id storage_class = "STANDARD" public_access_prevention = "enforced" uniform_bucket_level_access = true force_destroy = true } ## Uplaod dataflow config files to GCS ## resource "google_storage_bucket_object" "dataflow_config_files" { for_each = toset(local.dataflow_config_files) name = each.value bucket = google_storage_bucket.bucket.name source = "${path.module}/dataflow_config/${each.value}" } ## Workflows ## resource "google_workflows_workflow" "dataflow_workflow" { name = "dataflow-${var.env}-${var.prefix}" description = "Workflow for dataflow" project = var.project_id region = var.default_region source_contents = file("${path.module}/workflow.yaml") }
GCS
上記 main.py の通り、GCS を作成し Dataflow で利用する スキーマ定義ファイル、UDF スクリプト(ユーザ定義関数)を GCS にアップロードします。
./terraform/env/dev/common/dataflow_config/schema/usage_log.json
{ "BigQuery Schema": [ { "name": "timestamp", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "ログ日時" }, { "name": "service_name", "type": "STRING", "mode": "REQUIRED", "description": "サービス名" }, { "name": "user_id", "type": "STRING", "mode": "REQUIRED", "description": "ユーザID" }, { "name": "activity_name", "type": "STRING", "mode": "REQUIRED", "description": "アクティビティ名" } ] }
./terraform/env/dev/common/dataflow_config/udf/transform.js
function transform(data) { const record = JSON.parse(data); // timestampをBigQueryで扱える形式に変換 timestamp = record.jsonPayload.timestamp .replace("T", " ") .replace("+0900", "+09:00"); // 新しいJSONオブジェクトを作成 const transformedRecord = { project_id: record.jsonPayload.project_id, timestamp: timestamp, service_name: record.jsonPayload.service_name, user_id: record.jsonPayload.user_id, activity_name: record.jsonPayload.activity_name, }; // 変換後のJSONオブジェクトを文字列にして返す return JSON.stringify(transformedRecord); }
Workflows
上記 main.py の通り、Dataflow ジョブを作成するワークフローを定義します。 その際に、下記の Dataflow 定義 yaml ファイルを参照しています。
./terraform/env/dev/common/workflow.yaml
# Dataflowのジョブを作成するワークフロー main: params: [event] steps: - init: assign: - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - location: ${sys.get_env("LOCATION")} - input_bucket_name: ${event.data.bucket} - input_file: ${event.data.name} - service_name: ${sys.get_env("SERVICE_NAME")} - config_bucket_name: "dataflow-config-dev-common" // 設定ファイルを配置したバケット名 - bq_dataset: "sample_dataset" // BigQueryのデータセット名 - table_name: "usage_log" // BigQueryのテーブル名 - event_log: call: sys.log args: text: '${"input_bucket_name: " + input_bucket_name + ", input_file: " + input_file}' - create_dataflow: call: googleapis.dataflow.v1b3.projects.locations.templates.create args: projectId: ${project_id} location: ${location} body: jobName: dataflow parameters: javascriptTextTransformGcsPath: ${"gs://" + config_bucket_name + "/udf/transform.js"} JSONPath: ${"gs://" + config_bucket_name + "/bq_schema/" + table_name + ".json"} javascriptTextTransformFunctionName: transform outputTable: ${project_id + ":" + bq_dataset + "." + table_name} inputFilePattern: ${"gs://" + input_bucket_name + "/" + input_file} bigQueryLoadingTemporaryDirectory: ${"gs://" + config_bucket_name + "/temp"} gcsPath: gs://dataflow-templates-asia-northeast1/latest/GCS_Text_to_BigQuery result: output
個別プロジェクトリソースの作成
次に、各プロジェクト毎に必要なリソースを作成していきます。 Terrafom コードは以下の通りです。
./terraform/env/dev/sample_service_A/sample_service_A.tfvars
project_id = [ロギング基盤プロジェクトのプロジェクトID] default_region = "asia-northeast1" env = "dev" workflow_name = "dataflow-dev-logging-common" eventarc_service_account_email = [Eventarc のサービスアカウント] service_name = "sample-service-A" # サービスごとに変更
./terraform/env/dev/sample_service_A/variables.tf
variable "project_id" {} variable "default_region" {} variable "env" {} variable "workflow_name" {} variable "eventarc_service_account_email" {} variable "service_name" {}
./terraform/env/dev/sample_service_A/main.tf
## Provider ## provider "google" { project = var.project_id region = var.default_region } locals { prefix = "${var.env}-${var.service_name}" } ## GCS ## module "google_storage_bucket" { source = "../../../modules/gcp/gcs" project_id = var.project_id default_region = var.default_region prefix = local.prefix } ## Eventarc ## module "eventarc" { source = "../../../modules/gcp/eventarc" project_id = var.project_id default_region = var.default_region prefix = local.prefix service_account_email = var.eventarc_service_account_email gcs_bucket_name = module.google_storage_bucket.bucket_name workflow = "projects/${var.project_id}/locations/${var.default_region}/workflows/dataflow-dev-logging-common" }
GCS
他プロジェクトから転送されるログを格納する GCS を作成します。
./terraform/modules/gcp/gcs/main.tf
# GCS resource "google_storage_bucket" "bucket" { name = "log-bucket-${var.prefix}" location = var.default_region project = var.project_id force_destroy = true }
./terraform/modules/gcp/gcs/variables.tf
variable "project_id" {} variable "default_region" {} variable "prefix" {}
./terraform/modules/gcp/gcs/output.tf
output "bucket_name" { value = google_storage_bucket.bucket.name }
Eventarc
GCS にログが転送されたことをトリガーに Workflows を起動するための Eventarc を作成します。
./terraform/modules/gcp/eventarc/main.tf
# Create an Eventarc trigger, routing Cloud Storage events to Workflows resource "google_eventarc_trigger" "default" { name = "workflows-trigger-${var.prefix}" location = var.default_region # Capture objects created in the specified bucket matching_criteria { attribute = "type" value = "google.cloud.storage.object.v1.finalized" } matching_criteria { attribute = "bucket" value = var.gcs_bucket_name } # Send events to Workflows destination { workflow = var.workflow } service_account = var.service_account_email }
./terraform/modules/gcp/eventarc/variables.tf
variable "project_id" {} variable "default_region" {} variable "prefix" {} variable "gcs_bucket_name" {} variable "workflow" {} variable "service_account_email" {}
ログ Sync の設定
サービスが配置されるプロジェクト(構成図での A プロジェクト)にて、ログ Sync を作成します。
フィルタ機能を利用して必要なログのみ、ログ収集用プロジェクトの GCS にログを転送します(1時間毎)。
今回の例では、jsonPayload.usage_monitoring: true のログのみを転送するように設定しています。
スクリプト内容は以下の通りです。
./logger_sync/sample_service_A/create-sync.sh
SERVICE_NAME=sample-service-A # サービス名 DESTINATION_PROJECT_ID=[project_id] # ログ出力先のプロジェクトID DESTINATION_BUCKET_NAME=log-bucket-dev-sample-service-A # ログ出力先のバケット名 SINK_NAME=$SERVICE_NAME-sink-to-logging-project SINK_DESTINATION=logging.googleapis.com/projects/$DESTINATION_PROJECT_ID/locations/global/buckets/$DESTINATION_BUCKET_NAME \ gcloud logging sinks create $SINK_NAME $SINK_DESTINATION --log-filter 'jsonPayload.usage_monitoring: true'
ログの出力
別途 Cloud Function や Cloud Run 等を構築し、構造化ログを Cloud Logging に出力します。 今回は下記のようなログが JSON ペイロードで出力されることを前提としています。
{ jsonPayload: { "usage_monitoring": True, // ログ収集用のフラグ "timestamp": "2024-10-01T00:00:00", // ログ日時 "service_name": "service1", // サービス名 "user_id": "test@example.com", // ユーザID "activity_name": "act1_start" // アクティビティ名 } }
3. ログデータの可視化
収集したログデータを可視化するために、Looker Studio を利用しました。
選んだ理由は、お手軽にダッシュボードを作成できるからです。
というのも、Looker studio は 単純な集計であれば 直感的に UI 操作のみで可視化ができるため、専門的なスキルがなくても扱えます。
例えば、以下のようなアクティビティ及びユニークログイン数を集計したグラフを、ブラウザ操作のみで作成することができます。
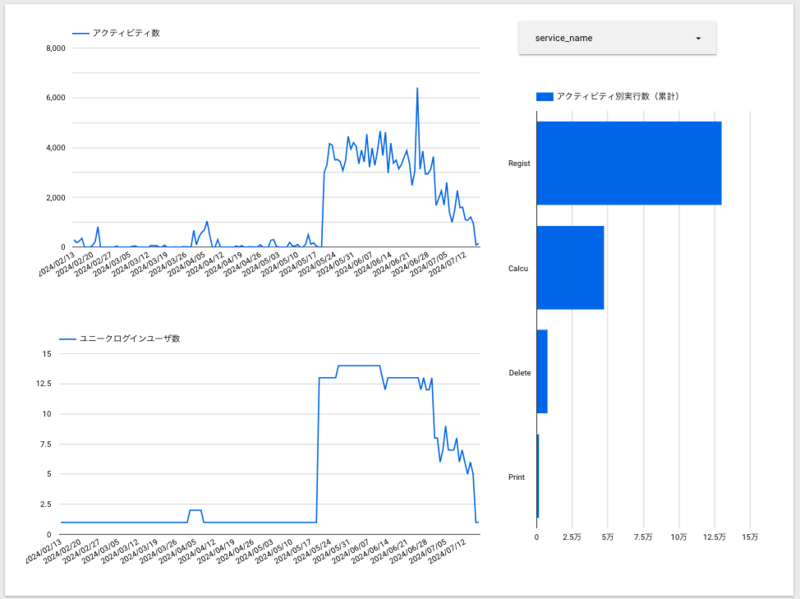
操作方法等については 公式ドキュメント をご参照ください。
4. まとめ
以上、ロギング基盤構築のご紹介でした。なお、構築はできたものの最低限の機能であり、まだまだ改善の余地があります。
今のところは共通プロパティのみの集計でしたが、実用性を考えると各プロジェクトで個別で集計したいプロパティもあると思うので、そちらも集計できるように改修したいと思っています。
また、今回は検証ということで GCP 環境のみを対象にしていましたが、当社では、AWS、Azure も使ってシステム開発を行っています。
今後は、マルチクラウドに対応したロギング基盤の構築にも取り組んでいきたいと考えています。また、ディレクトリ構成についても、より適切な構成を検討していきたいです。