こんにちは、Insight EdgeのLead Engineerの日下です。 今回は、DEAPライブラリを利用した遺伝的アルゴリズムをAWS Lambdaで分散並列実行した話を紹介しようと思います。
目次
前提
クラウド基盤: AWS
言語: Python
ライブラリ: DEAP
背景と課題
ある案件で、遺伝的アルゴリズム (以下、GA)を用いた最適化処理により業務改善の実証実験をしていたところ、性能に課題があるということでデータサイエンティストチームから相談を受けました。 当該処理は、EC2 (r7g.4xlarge: 16CPU 128GiBメモリ) で10.8時間を要しており、以下の問題点がありました。
- 検証が当日中に完了せず、試行錯誤のサイクルに時間がかかっていた。
- 運用開始後のエンドユーザの利便性や利用価値の低下も懸念された。
性能改善のアプローチは、大きく分けてアプリ観点とインフラ観点の2つが考えられます。
- アプリ観点: アルゴリズムの見直しや、使用言語の変更
- インフラ観点: ハードウェアのスケールアップや、並列化によるスケールアウト
アプリ観点の改善はデータサイエンティスト側で継続検討することとし、私はインフラ観点で即効性のある改善を目指しました。 また、PoC段階ではEC2を利用していたものの、運用リリースを見据えてLambdaやFargateなどのサーバーレス技術の利用を想定し、ハードウェアの性能向上ではなく分散処理による並列化を目指す方針としました。
並列化の方法の検討
どこを並列化するか?
GAには、「1世代内でN個の個体に対する評価関数ループ」と、それを「世代数G回分繰り返すループ」の2重のループがあります。 このうち、後者のG回分の「世代ループ」は前世代の結果に依存して次世代の処理をするため、容易に並列化できません。 一方で、前者の「世代内の個体評価ループ」は各個体の評価は相互依存せず実行できるため、並列化が可能です。 よって、並列化の対象は「世代内の個体評価ループ」としました。
どのように並列化するか?
個体評価ループは1世代あたりの実行時間が短く、[分散処理]→[結果を集約して比較]→[分散処理]→[結果を集約して比較]のループを世代数分繰り返す必要があるため、できるだけオーバーヘッドの少ない方法で並列化する必要があります。 以下の検討ポイントから、AWS Lambdaを分散処理に利用することとしました。
- コスト効率: 処理の実行頻度が高くないため、インフラ維持費の高い常時稼働型サービスは不適
- 軽量処理への適性: 並列化対象の「個体評価」処理は軽量なため、呼び出しのオーバーヘッドが少ないLambda (FaaS)を採用
実装の方針
Lambdaを利用した分散処理の実装にあたっては、以下の方針で進めました。
呼び出し側コード
- 最適化タスク全体の入力パラメタをpickle化し、タスクID(ULIDで一意採番)をキーにしてS3に保存
- 呼び出し先のLambda関数やS3保存先情報を含んだmap関数を動的に作成し、DEAPに渡す
- map関数内でLambdaを並列実行し、結果を配列にして返す
Lambda側コード
- evaluate関数をLambdaに対応させる形で実装
- Lambda実行時のevent引数で、タスクID、タスク入力値のS3保存先、評価対象の個体リストを指定
- タスク入力条件をS3から取得する処理をキャッシュすることで、ウォームスタート時はS3非経由で実行
その他
- S3のライフサイクルルールを利用して、アップロードしたpickleは一定期間後に自動削除
実装イメージを図示すると以下のようになります。
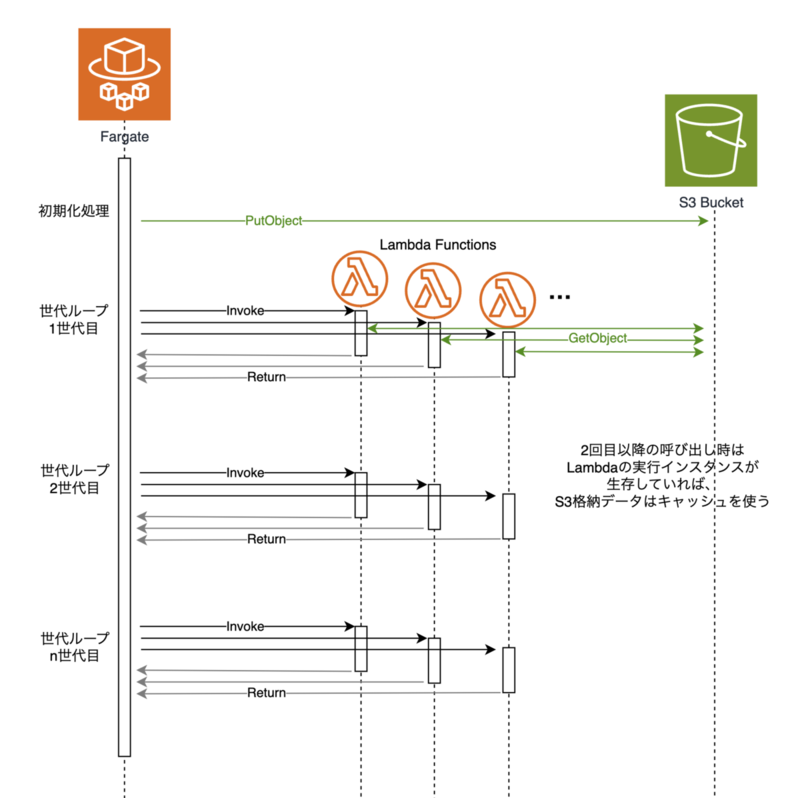
Lambdaを呼び出すためのDEAPへのmap実装
呼び出し側コード
lambda_map.py
import json from concurrent.futures import ThreadPoolExecutor import pickle import boto3 from ulid import ULID from botocore.config import Config boto3_config = Config(max_pool_connections=100) lambda_client = boto3.client("lambda", config=boto3_config) s3_client = boto3.client("s3") def prepare_task_params(*, bucket_name: str, prefix: str, input_data: dict): """ タスクの入力値をS3にアップロードし、Lambda関数に渡すためのパラメータを返す。 """ task_id = f"T{str(ULID())}" # input_dataをpickle化してS3にアップロード input_data_key = f"{prefix}/{task_id}_input.pkl" input_data_bucket = bucket_name s3_client.put_object( Body=pickle.dumps(input_data), Bucket=input_data_bucket, Key=input_data_key, Tagging="AutoDelete=true" ) task_params = { "task_id": task_id, "bucket": input_data_bucket, "key": input_data_key, } return task_params def call_lambda_for_chunk(lambda_function_name: str, chunk: list, task_params: dict): """ 1チャンク分の個体配列とタスクパラメータをevent引数にしてLambdaを実行。 """ event_payload = { "individuals": chunk, "task_params": task_params, } payload = json.dumps(event_payload) response = lambda_client.invoke( FunctionName=lambda_function_name, InvocationType="RequestResponse", Payload=payload, ) result_payload = response["Payload"].read() response = json.loads(result_payload) fitness_list = [tuple(fitness) for fitness in response["body"]["results"]] return fitness_list def create_lambda_map_func(lambda_function_name: str, *, chunk_size=20, task_params: dict): """ チャンクサイズを指定して、AWS Lambda で個体リストを評価するmap関数を作成する。 ・個体リストをチャンクに分割し、AWS Lambda で評価するためのラッパー関数を返す。 ・この関数を DEAP の toolbox に登録して、map 関数として利用する。 """ # 独自のmap関数を定義。ただし、写像処理はLambda側で処理されるため、func引数は受け取るだけで実際には使用しない。 def lambda_map(func, iterable): items = list(iterable) # チャンクに分割(例: 1800 個体を 18 個ずつ → 100 チャンク) chunks = [items[i : i + chunk_size] for i in range(0, len(items), chunk_size)] # チャンク数分の結果リストを初期化 chunk_results = [None] * len(chunks) # 各チャンクを非同期でLambda関数に送信し、結果を取得する with ThreadPoolExecutor(max_workers=100) as executor: futures = [ (executor.submit(call_lambda_for_chunk, lambda_function_name, chunk, task_params), idx) for idx, chunk in enumerate(chunks) ] # 分散処理の結果を待ち合わせ、チャンク別の結果を配列に格納 for future, idx in futures: chunk_results[idx] = future.result() # チャンク別の結果をflatなリストに戻す results = [] for chunk_result in chunk_results: results.extend(chunk_result) return results return lambda_map
DEAPのmap関数を置き換えるコード
from lambda_map import prepare_task_params, create_lambda_map_func def execute_task(task_input: dict): task_params = prepare_task_params( input_data=task_input, bucket_name="<your-bucket-name>", prefix="intermediate/dev", ) map_func = create_lambda_map_func("ga-evaluate-function-name", chunk_size=10, task_params=task_params) # DEAPのToolboxにmap関数を登録 toolbox = base.Toolbox() toolbox.register("map", map_func) # ...後略 その他のDEAP設定や遺伝的アルゴリズムの実装は省略
Lambda側コード
lambda_evaluate.py
import pickle from functools import lru_cache import boto3 s3 = boto3.client("s3") @lru_cache(maxsize=15) def load_task_input(bucket, key): """ S3からタスク入力データをロードする。 キャッシュを利用して、同じタスク入力データの再取得を高速化する。 """ s3_res = s3.get_object(Bucket=bucket, Key=key) task_input = pickle.loads(s3_res["Body"].read()) return task_input def evaluate_func(individual, task_input_data): """ 個体の評価関数。個体とタスク入力データを受け取り、適応度を計算して返す。 """ # ここに個体の評価ロジックを実装 # 例: 適応度を計算して返す fitness = sum(individual) # 仮の評価ロジック return (fitness,) def handler(event, context): """ Lambda関数のエントリポイント。 event引数には、個体リストとタスクパラメータが含まれる。 """ individuals = event["individuals"] task_params = event["task_params"] # タスク入力データをS3からロード task_input_data = load_task_input(task_params["bucket"], task_params["key"]) # 各個体に対して評価関数を適用 results = [evaluate_func(ind, task_input_data) for ind in individuals] # 結果を返す return {"statusCode": 200, "body": {"results": results}}
今回の実装の工夫ポイント
- 必要な処理を分析ロジックから切り離してブラックボックス化することで、既存コードへの影響を最小化。 map関数に落とし込んでいるので、配列から配列に写像(map)する処理を容易に置き換え可能。
- フルマネージド&利用従量課金サービスのみに依存することで、手軽に導入可能&運用コスト抑制。 いつでも使える状態を維持しつつ、使わなければほぼ無料でインフラを維持可能。
改善の評価
実際にこの実装を適用して実行時間を測定したところ、以下のような性能改善が得られました。
実行時間の比較: * 従来のEC2のみ: 10.8時間 * EC2 + Lambda: 2.5時間
この時間短縮により、以下の改善効果が期待できます。 * テスト・検証サイクル高速化:これまで1日1回しかできなかった精度検証が、業務時間内で複数回実行することが可能になり、評価関数やハイパーパラメータの探索効率が向上。 * 業務効率向上:アルゴリズムを実用化したときに結果が早く得られるため、エンドユーザの利便性や利用価値が向上。
コストはEC2のみ約11USDからFargate+Lambdaで約16USDへ増加しましたが、時間短縮のメリットと、EC2で発生していたアイドル時の無駄なコストがない点を考慮し、許容範囲内と判断しました。
注意点
Lambdaへの大量なアクセスがあるため、ネットワーク速度の影響を受けやすいことに注意してください。 今回の性能検証でも、同一リージョンのEC2からは1世代あたり約0.6秒だったのに対し、 ローカルPCからインターネット経由で呼び出した場合は1世代あたり約3秒かかり、速度改善効果が得られませんでした。
まとめ
遺伝的アルゴリズムの個体評価処理をAWS Lambdaで分散並列化し、以下の改善効果がありました。
- GA計算時間を10.8時間から2.5時間へ短縮 。
- DEAPのmap関数置き換えで既存コード影響を最小化 。
- サーバーレス採用でインフラ維持コスト抑制とスケーラビリティ確保 。
今後のプロダクト化にあたっては、アプリ面での最適化も検討し、さらなる性能向上を目指します。