こんにちは!アジャイル開発チームの筒井です!
最近の生成AIツールの進化は目覚ましいものがあります。Microsoft CopilotやGemini for Workspaceなど、業務向けの生成AIサービスも企業の業務基盤に組み込まれつつあり、もはやAIを業務で活用するのは特別なことではなくなっています。
その中でも「社内ドキュメントやFAQをAIチャットで(横断)検索したい」というニーズは生成AIが話題となり出した数年前から根強く存在しており、弊社でも当時から「社内ドキュメントを生成AI型チャットボットで検索できるシステム」を開発し、さまざまなプロジェクトの中で提供してきました。
しかし、CopilotやGeminiなどSaaS型AIサービスが急速に進化する中で、「独自開発システムでは最新のAI体験や新機能をすぐに取り込めない」「他社サービスと同じ機能をゼロから作るのはエンジニアとしてもモチベーションが上がりにくい」といった課題も見えてきました。
弊社としても、検索チャットボットのような一般的なユースケースについてはSaaS型AIサービスの導入を検討することを推奨・支援していますが、さまざまな理由からこれらの導入が難しい現場も少なくありません。
そこで本記事では、ChatGPTクローンOSSであるLibreChatとMCP(Model Context Protocol)を利用して、一般的なチャットボットとしての機能追加はOSS側に任せつつ、簡易的に社内ドキュメントの検索機能をアドオンできるか確認してみました。
- システム構成
- Amazon Bedrock Knowledge Basesの準備
- Amazon Bedrock Knowledge Base Retrieval MCP Serverの準備
- LibreChatの準備
- LibreChatでの動作確認
- まとめ
システム構成
システム構成は下図のようになります。

MCPサーバーとデータソースの部分は何でも良いのですが、今回は公式のMCPサーバーが提供されており、手軽に構築ができそうなAmazon Bedrock Knowledge Basesを使ってみることにしました。
Amazon Bedrock Knowledge Basesの準備
まずはデータソースの準備をします。Webで「大学 就業規則」と検索し、上位2件にヒットした東京大学と鳴門教育大学の就業規則を社内ドキュメントの代わりとして利用することにしました。
これらのPDFファイルをダウンロードして、S3にアップロードしてナレッジベースとして登録しました。おおむね下記のような設定で取り込んでいます。
- 解析戦略: パーサーとしての基盤モデル
- チャンキング戦略: 階層型チャンキング
- 親トークンの最大サイズ: 1500トークン(デフォルト値)
- 子トークンの最大サイズ: 300トークン(デフォルト値)
- チャンク間トークンオーバーラップ: 60トークン(デフォルト値)
ちなみに解析戦略には「パーサーとしてのAmazon Bedrockデータオートメーション(Amazon Bedrock Data Automation as parser)」という選択肢もあります。そちらはドキュメント中の図表をテキスト検索可能にした上で検索結果はイメージのまま返し、マルチモーダルモデルで入力に応じた解釈をできるようにするという良い感じのモードなのですが、現時点のBedrock Knowledge Bases公式MCPサーバーではIMAGEタイプの結果を取得できないとのことで、「パーサーとしての基盤モデル(Foundation models as a parser)」を選んでいます。こちらは図表を事前にマルチモーダルモデルでテキスト化しておくモードです。
(参考: https://awslabs.github.io/mcp/servers/bedrock-kb-retrieval-mcp-server/)
Results with IMAGE content type are not included in the KB query response.
Amazon Bedrock Knowledge Base Retrieval MCP Serverの準備
MCPサーバーの機能や使い方はこちらで確認することができます。
上記ドキュメントやその元となっているREADME.md等には指定方法が明記されていないのですが、 QueryKnowledgeBases ツールのパラメーターを確認すると、下記のように検索実行時に reranking_model_name と data_source_ids を指定できるようになっています。
今回は大学ごとに別々のナレッジベースを作りましたが、1つのナレッジベースに大学ごとのドキュメントを別々のデータソースとして追加しても柔軟に対応できそうです。
Parameters: • query (required): string - A natural language query to search the knowledge base with • knowledge_base_id (required): string - The knowledge base ID to query. It must be a valid ID from the resource://knowledgebases MCP resource • number_of_results: integer - The number of results to return. Use smaller values for focused results and larger values for broader coverage. • reranking: boolean - Whether to rerank the results. Useful for improving relevance and sorting. Can be globally configured with BEDROCK_KB_RERANKING_ENABLED environment variable. • reranking_model_name: string - The name of the reranking model to use. Options: 'COHERE', 'AMAZON' • data_source_ids: unknown - The data source IDs to filter the knowledge base by. It must be a list of valid data source IDs from the resource://knowledgebases MCP resource
参考:Claude Codeでお試し
一旦MCPサーバーとしてどんな感じで動いてくれるのか、Claude Codeでお試ししてみました。以下のように動作し、良い感じに検索から回答の出力までできています。
1. MCP Resource resource://knowledgebases にアクセスして、AWSアカウント内に存在するナレッジベースの一覧を取得する
⏺ listMcpResources(List MCP resources from server "bedrock-kb")
⎿ [
{
"uri": "resource://knowledgebases",
"name": "KnowledgeBases",
"description": "(略)
⏺ readMcpResource(Read resource "resource://knowledgebases" from server "bedrock-kb")
⎿ {
"contents": [
{
"uri": "resource://knowledgebases",
"mimeType": "application/json",
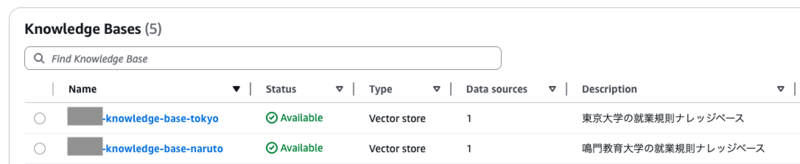
"text": "{"RTPF4*****": {"name": "******-knowledge-base-tokyo", "data_sources": [{"id": "(略)"}]},
"AGTRP*****": {"name": "*******-knowledge-base-naruto", "data_sources": [{"id": "(略)
(※ 一部整形しています)
2. 入力に応じて QueryKnowledgeBases を呼び出し、検索結果を取得する
⏺ bedrock-kb:QueryKnowledgeBases (MCP)(query: "副業 兼業 営利企業 許可申請 東京大学教職員", knowledge_base_id: "RTPF4*****", number_of_results: 5)
⎿ {
"content": {
"text": "(略)"
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://******/東京大学教職員兼業規程.pdf"
(略)
3. 回答を生成する
⏺ 東京大学の教職員は、原則として副業(兼業)をするために事前の許可が必要です。以下が重要なポイントです: 兼業許可の基本ルール: - 職務の遂行に支障がなく、特別な利害関係がない場合に許可される - 営利企業の役員等は原則禁止(技術移転事業者や研究成果活用企業等は例外あり) (略)
LibreChatの準備
最後にLibreChatの構築をします。今回は動作確認をしたいだけなので、GitHubリポジトリからクローンしてきて、ほぼデフォルト設定のまま docker compose でローカル実行するようにします。バージョンはv0.7.8を利用しました。
librechat.yaml に、MCPサーバーの設定をします。
mcpServers: bedrock-kb: command: uvx args: - "awslabs.bedrock-kb-retrieval-mcp-server@latest" env: AWS_REGION: us-west-2 AWS_ACCESS_KEY_ID: <AWS_ACCESS_KEY_ID> AWS_SECRET_ACCESS_KEY: <AWS_SECRET_ACCESS_KEY> serverInstructions: true
LibreChatでの動作確認
エージェントの作成
利用者がMCPサーバー経由での社内ドキュメント検索機能を使えるようにするため、エージェントビルダーを使ってLibreChatのエージェントを作っていきます。
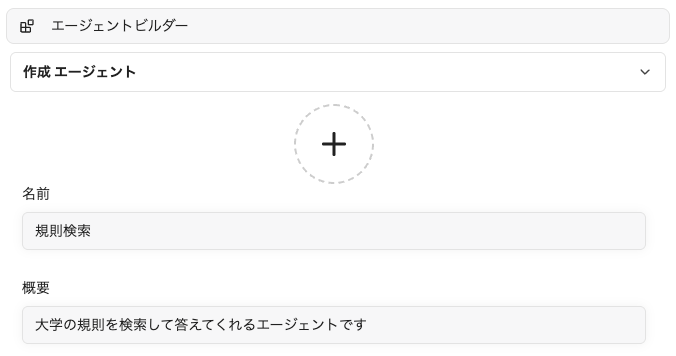
上記の librechat.yaml への設定をしておくと、エージェント作成画面のツール選択欄に、 QueryKnowledgeBases というツールが表示されるので、これを「追加」します。

エージェントに与えるシステムプロンプトは以下のようにしました。
# 回答ルール - 必ず検索の結果に含まれる内容のみを用いて回答してください。質問に対する回答が検索の結果に含まれない場合は、わからない旨を回答してください - 検索の結果に回答するための情報が見つからない場合や不足している場合は必ず追加で情報を収集してください # QueryKnowledgeBases の利用に関する指示 - `knowledge_base_id` は以下を利用してください - 東京大学の規則: `RTPF4*****` - 鳴門教育大学の規則: `AGTRP*****` - 東京大学と鳴門教育大学の規則を検索可能です - 一度の検索結果は5件取得してください。 - リランキングにはCohereモデルを使用してください - レスポンスに含まれる uri のファイル名部分(例: 規則.pdf)から拡張子を除いたもの(例: 規則)が規則名です。
上記Claude Codeでの動作確認の通り、MCP Resource resource://knowledgebases にアクセスすることで各種IDの情報を取得することができ、事前に取得するようMCPサーバーのDescriptionにも記載されているのですが、LibreChatでは執筆時点でまだMCP Resourceのサポートがされていないとのことで、IDに関する情報をシステムプロンプトで与えています。これが無いと存在しないデータソースIDを検索して、「見つからなかった」と回答してきます。
(参考: https://github.com/danny-avila/LibreChat/discussions/7429)
仮にMCP Resourceがサポートされていたとしても、今回利用している公式MCPサーバーでは、ナレッジベースやデータソースに対する説明を記述する箇所が無いため、LLMがどのナレッジベースやデータソースを利用するかの指針はシステムプロンプトに書く必要があります。 いずれにせよこれらはエージェントへの指示としてエージェント提供側が作成時に書けば良いだけなので、特に違和感は無いと思います。
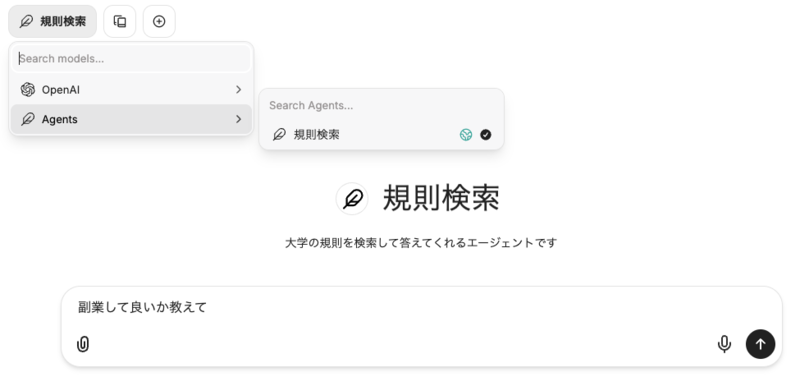
基本動作
実際にエージェントを使うときには、モデル選択と同じ場所で使いたいエージェントを選びます。聞きたい内容に合わせてエージェントを切り替えることができ、利用者にとってもわかりやすいUIになっています。
この状態で質問をしてみると、下記のような回答が返ってきます。ユーザーからの入力に基づき、システムプロンプトで指定した各大学のナレッジベースIDを指定して複数のMCPサーバー呼び出しを実行し、ドキュメント群を検索して回答を生成してくれています。画像中の1つ目の「Ran QueryKnowledgeBases」が東京大学のナレッジベース、2つ目が鳴門教育大学のナレッジベースに対する検索です。

[質問] 副業して良いか教えて
[回答] 東京大学と鳴門教育大学の副業(兼業)に関する規則を要約し、解説します。 ### 【東京大学の場合】 - 東京大学の教職員が副業(兼業)を行う場合、 原則として事前に「許可」を得ることが必要です(「教職員兼業規程」第5条、第7条等)。 - 副業ができるかどうかの判断基準としては、主に以下が挙げられます(「教職員兼業規程」第2条、第3条等): - 副業先との間に特別な利益相反関係がないこと - 本務(東京大学での職務)の遂行に支障がないこと - 教職員としての信用や大学の名誉を損なわないこと (略) ### 【鳴門教育大学の場合】 - 鳴門教育大学でも、教職員の副業(兼業)は、 原則学長の「許可」が必要です(「教職員兼業規程」第2条、第15条 等)。 - 営利企業の役員等の兼業は原則不可ですが、一定の基準・条件のもとで許可されることもある(技術移転や研究成果活用企業などの場合)。 - 申請には副業先との関係、業務内容、年間収益等を記載した書類を提出し、学長等の審査を経て許可を得る必要があります。 - 無報酬の兼業の場合にも、許可が不要となる例外がありますが、この点は一部の役職・内容に限られます。 (略)
入力に応じたMCPサーバーの使い分けとマルチターン会話
質問で大学を指定した場合はその大学の情報のみを検索してくれます。また、マルチターン会話から適切な検索フレーズを生成し、回答に必要な情報を収集できています。
[質問] 東京大学では休職は取れる?
[回答] 東京大学では「休職」を取ることができます。ただし、いくつかの規則や条件があります。 主に教職員を対象とする「休職」は、東京大学教職員休職規程で定められています。理由としては病気による休職、出向による休職、役員兼業による休職などがあります。病気による場合は、原則として医師の診断結果に基づいて期間を決定し、復職にも医師の診断が必要です。 (略)
[質問] 鳴門教育大学の場合は?
[回答] 鳴門教育大学でも「休職」を取ることができます。主な内容は以下の通りです。 (略)
エージェントのユーザーとの共有
作成したエージェントは他のユーザーと共有することができます。ただし、全ユーザーへの共有しか方法が無く、特定のユーザーやグループとの共有をすることができません。このため、基本的なユースケースとしては管理者がエージェントを作成して全ユーザーに展開し、一般のユーザーは詳細の閲覧・編集は不可としてエージェントを使うのみ、というシンプルな運用になると思います。

MCPサーバーの複数回呼び出し(Agentic RAG)
いわゆるAgentic RAG的に、検索の結果に応じて自律的に追加のアクション(ここではMCPサーバー呼び出し)をすることもできます。 例えば質問時に「検索結果で他の規則を示している場合は、そちらの規則も必ず追加で検索してください。」のような指示を追加すると、複数回MCPサーバーを呼び出すことで情報を収集してくれます。
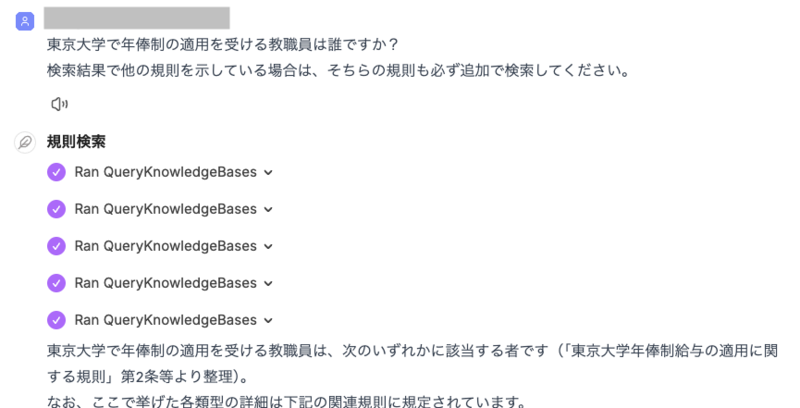
[質問] 東京大学で年俸制の適用を受ける教職員は誰ですか? 検索結果で他の規則を示している場合は、そちらの規則も必ず追加で検索してください。
[順に実行された検索のクエリ列] "年俸制の適用を受ける教職員は誰か" "東京大学年俸制の適用対象者を規定する条項に言及されている他の規則の年俸制適用範囲を確認したい。『東京大学教職員給与規則』・『特定有期雇用教職員就業規程』・『高度学術専門員及び高度学術専門職員に関する規則』・『職域限定職員就業規程』の年俸制適用対象者について調べたい。" "特定有期雇用教職員就業規程 第2条" "職域限定職員就業規程 第2条" "高度学術専門員及び高度学術専門職員に関する規則 年俸制 対象"
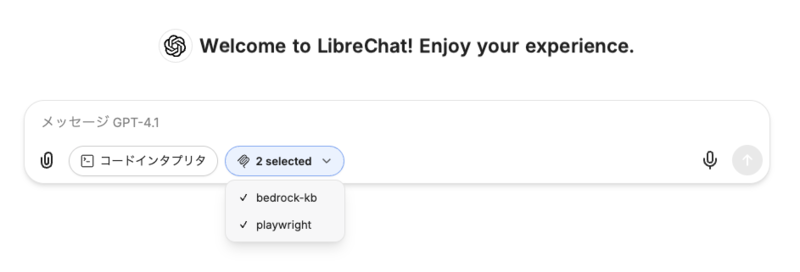
参考:チャット内での利用
LibreChatでは、通常のチャット画面から利用者がMCPサーバーを指定して利用することも可能です。例えば下の画像では、入力に応じて2つのMCPサーバーを呼び出し可能にしています。 こちらは上述したMCP Resourceのサポートができていない課題があり、かつ利用者がナレッジベースIDやデータソースIDを指定すると言うのは現実的でないため、動作確認対象外としました。
まとめ
本記事ではLibreChatにMCPサーバーを組み合わせることで、社内ドキュメント検索機能を付与することを試してみました。
LibreChatはユーザーのファイルアップロードによるRAG、画像のアップロードによるマルチモーダル処理、音声入出力、アーティファクト出力(プログラム生成とUI上での実行)、Web検索、画像生成モデルによる画像生成など、多彩な機能を持っており、ユーザーからよくある「あんな機能も使ってみたい」への対応として多くをカバーしてくれているように思います。
その上で、今回実施したように、データソースとMCPサーバーを用意してしまえばあとはLibreChat側の機能で良い感じにデータを扱ってくれるので、簡易的な社内ドキュメント検索チャットボットとしても有用に感じました。また、データソース部分とMCPサーバー部分はユースケースに応じたチューニングが効かせられる部分であり、それらが汎化かつブラックボックス化されがちなSaaS型AIサービスとの比較しても有効なケースがありそうです。
各種生成AIサービスの進化が非常に速いペースで進む中ではありますが、本記事で扱ったような内容も、現場に寄り添った提供方法の一案として検討していければと思います。