はじめに
こんにちは。
今年の7月からInsight Edgeに参画したDeveloperのニャットと申します。参画後すぐにも新規PoC案件のバックエンド/フロントエンドの設計から開発までを任せてもらえました。初めは慣れないアーキテクチャ選定や新しい技術の習得に少し頭を抱えていましたが、最近やっと形になって、毎日とても楽しく過ごせています。
近年のAPI開発では、データの型安全性とドキュメンテーションの容易さが重要視されています。弊社もフロントエンド開発ではTypescriptを積極的に採用しており、バックエンド開発におけるPythonプロジェクトでもモダンなPythonフレームワークを採用し、型を記述しながら開発を進めることを奨励しています。その中でFastAPIフレームワークは注目されているものの1つです。
本記事では、直近私がプロジェクトで実際使用しているFastAPIフレームワークでのAPI開発において、DynamoDBデータベースおよびデータ検証Pydanticライブラリの組み合わせ方および型安全なAPIの構築方法について皆さんに紹介したいと思います。説明のために「社内ランチ共有アプリ」を例として紹介します。
社内ランチ共有アプリ
概要
「社内ランチ共有アプリ」とは、実在しないアプリであり、今回のTechBlogに架空のアプリのテーマとしてChatGPTが提案してくれたものです。
当社で実施している シャッフルランチ というイベントに利用できそうで、このブログのきっかけで将来的にこのアプリが採用されることを期待しています。(笑) ChatGPTによると、アプリの機能は以下となります。
- 社内の全ての投稿を確認する
- 社員がランチに関する感想や場所を投稿する
- 社員が投稿に対してリアクション(いいね)を送る
API仕様
上記のアプリのために、今回は以下のAPIを作成するとします。
- ランチ投稿API
- GET /posts: すべてのランチ投稿を取得します。
- POST /posts: ユーザーが新しいランチ投稿を作成します。
- リアクション(いいね)API
- POST /posts/{post_id}/likes: 特定のランチ投稿にいいねを押します。
OpenAPIを使用して以下のように設計しました。
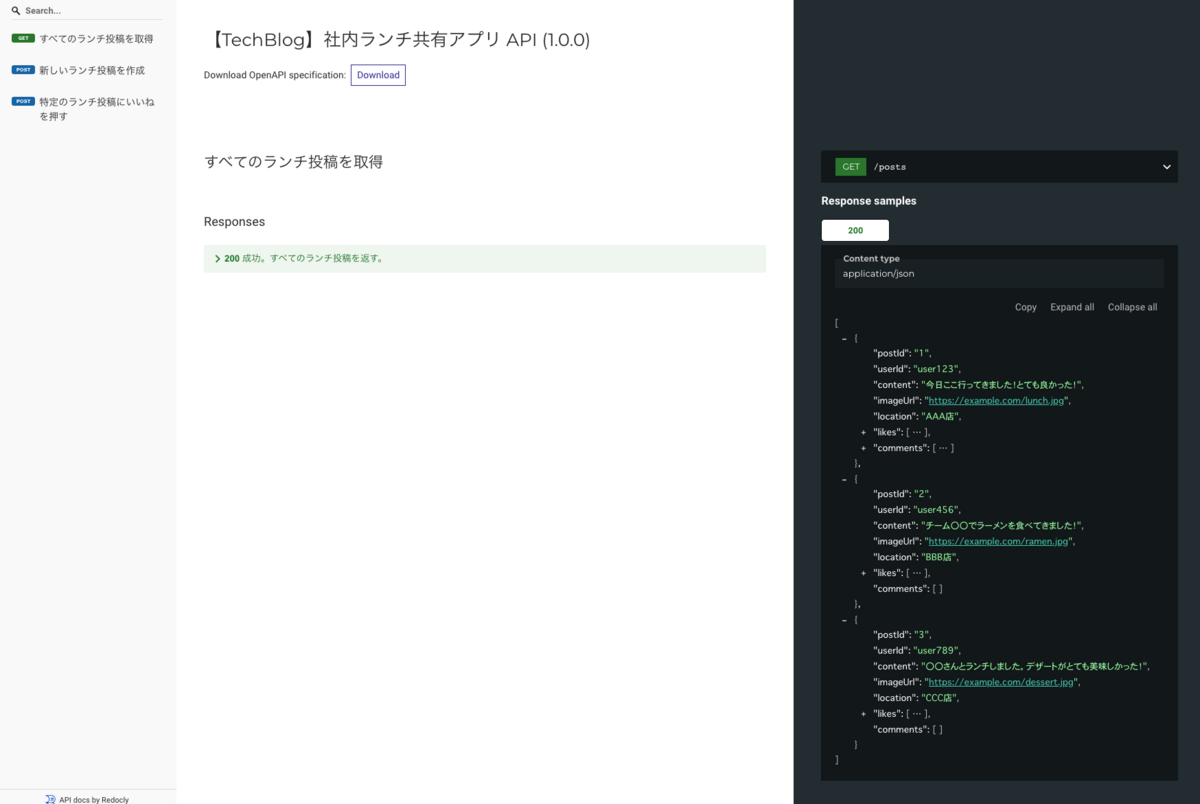
APIの仕様詳細は こちら をご覧ください。
テーブル定義
今回はこのようなDynamoDBテーブルとします。
| PK (Partition Key) | SK (Sort Key) | UserId | Timestamp | Content | ImageKey | Restaurant | Likes |
|---|---|---|---|---|---|---|---|
| Posts | Post#2f1fa759-72c2-a68e-364f-54fb3f1e4ed1 | user123 | 1702355804 | 今日ここ行ってきました!とても良かった! | lunch.jpg | AAA店 | [user456, user789] |
| Posts | Post#429d4ee2-44f1-d25b-9912-41c604eabef0 | user456 | 1702442204 | チーム〇〇でラーメンを食べてきました! | ramen.jpg | BBB店 | ["user123"] |
| Posts | Post#f3c512e1-faad-b4cc-1bee-955db716bdca | user789 | 1702528604 | 〇〇さんとランチしました。デザートがとても美味しかった! | dessert.jpg | CCC店 | ["user123", "user456", "user789"] |
ソースコード
開発したソースコードは以下をご参照ください。この記事で紹介しているソースコードは以下のリポジトリに含まれているものになります。
本記事では以下の内容を記事のスコープ外とします。
- 環境構築手順に関する説明
- FastAPIアプリケーションの公開手順に関する説明
実際に手を動かしてみたい方はサンプルコードをご利用ください。
FastAPI,Pydantic,AWS DynamoDBの組み合わせた型安全なAPIの構築
Pydanticの基本的な使い方
Pydanticを使用する場合、通常は事前にモデルを作成し、データのスキーマや型などを定義する必要があります。Pydanticのデータモデルは、BaseModel というクラスを継承した新しいクラスで構成されます。各フィールドで定義される型は、データの型ヒントとして機能します。
from pydantic import BaseModel from typing import List class LunchBlog(BaseModel): id: str user_id: str timestamp: int content: str image_key: str restaurant: str likes: List[str] = []
Pydanticはたくさんの機能を持っていますが、一般的に以下のために利用されることが多いかと思います。
- 入力データのバリデーション(検証)および型変換
- データのシリアライズ(シリアル化)
入力データのバリデーションおよび型変換
以下のようにモデルクラスのインスタンスを作成すると、バリデーションチェックが自動的に行われます。
成功例
input_dict = {
"id": "2f1fa759-72c2-a68e-364f-54fb3f1e4ed1",
"user_id": "user123",
"timestamp": "1702355804",
"content": "今日ここ行ってきました!とても良かった!",
"image_key": "lunch.jpg",
"restaurant": "AAA店",
"likes": []
}
lunch_blog = LunchBlog(**input_dict)
print(lunch_blog)
# 出力: id='2f1fa759-72c2-a68e-364f-54fb3f1e4ed1' user_id='user123' timestamp=1702355804 content='今日ここ行ってきました!とても良かった!' image_key='lunch.jpg' restaurant='AAA店' likes=[]
上記の例では input_dict が LunchBlog モデルスキーマに従っているため、lunch_blog インスタンスが作成されました。
気づいている方もいるかもしれませんが、timestamp の型を int としていたにもかかわらず、入力となっている input_dict の timestamp は文字列になっています。ここで、生成された lunch_blog インスタンスの timestamp は数字に変換されています。これはPydanticのデータ変換機能が働いているからです。一部のデータ型では入力されたデータの型が間違っていても正しい型に変換されるため、安心で便利だと思います。ただし、一部のクリティカルな機能ではデータの損失などが発生しないように気をつけるべきところでもありますね。
失敗例
モデルインスタンス時、もし以下のようにバリデーション違反のフィールドがあると、エラーが発生します。
# idフィールドを含まないinput_dict input_dict = { "user_id": "user123", "timestamp": "1702355804", "content": "今日ここ行ってきました!とても良かった!", "image_key": "lunch.jpg", "restaurant": "AAA店", "likes": [] } lunch_blog = LunchBlog(**input_dict) # <-失敗処理 print(lunch_blog) # エラー: # pydantic_core._pydantic_core.ValidationError: 1 validation error for LunchBlog # id # Field required [type=missing, input_value={'user_id': 'user123', 't...: 'AAA店', 'likes': []}, input_type=dict] # For further information visit https://errors.pydantic.dev/2.5/v/missing
以上のように、pydanticのデータモデルを使用することでバリデーションチェックやデータの変換が可能になります。
データのシリアライズ(シリアル化)
Pydanticモデルインスタンスから model_dump というPydanticのメソッドを使って簡単に辞書型に変換することもできます。
lunch_blog_dict = lunch_blog.model_dump() print(lunch_blog_dict) # 出力: {'id': '2f1fa759-72c2-a68e-364f-54fb3f1e4ed1', 'user_id': 'user123', 'timestamp': 1702355804, 'content': '今日ここ行ってきました!とても良かった!', 'image_key': 'lunch.jpg', 'restaurant': 'AAA店', 'likes': []}
API開発においては、データシリアライズが常に求められますので、この機能があると便利ですね。
FastAPIとPydanticの組み合わせ
上記でPydanticの基本方を紹介しました。普段の開発でもたくさんの場面で活用できるPydanticですが、実はFastAPIと組み合わせて利用すると、FastAPI開発がとても便利になります。この理由はFastAPIはPydanticのベースでできており、Pydanticのための機能をたくさん用意しているからです。
サンプルコードにあった POST /posts APIのための以下のルーター関数を例として説明させていただきます。
以下のコードでは以下の機能を簡単に実装できています。
- POST APIのリクエストボディのバリデーションチェック
- APIレスポンスのバリデーションチェックおよびJSON Schemaへ自動変換
# api/api/routers/post.py @router.post("/posts", status_code=status.HTTP_201_CREATED, response_model=PostCreatedResponse) def create_posts(request: Request, post: PostCreateRequest): """新しいランチ投稿を作成""" try: # リクエストしたユーザーのユーザー情報を取得 user_info = get_user_info_from_request(request) # DynamoDBに格納するための新規投稿レコード情報を準備 new_post_item = PostCreateToDB( **post.dict(), user_id=user_info.username, ) # DynamoDBに新規投稿レコードを格納 lunch_blog_table.create_post(new_post_item) except ClientError as err: raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR) else: # 処理が成功した場合、作成した投稿情報を返却 return new_post_item
リクエストボディのバリデーションチェック
FastAPIでは、リクエストボディの型チェックはPythonのほとんどのデータ型を指定しても検証できるようですが、最終的に全てPydanticで処理されるそうです。そのため、全てのパワーや利便性を発揮させるために、FastAPIはリクエストボディの型指定にはPydanticモデルの使用を推奨しています。
上記の create_posts ルーター関数のパラメター post はリクエストボディになります。post の型として PostCreateRequest を指定しています。
def create_posts(request: Request, post: PostCreateRequest):
class PostCreateRequest(BaseModel): """新しいランチ投稿を作成するためのリクエストモデル""" content: str = Field(validation_alias="content") image_key: str = Field(validation_alias="imageKey") restaurant: str = Field(validation_alias="restaurant")
上記によって、リクエストされたリクエストボディオブジェクト post が PostCreateRequest モデルに従わない場合、バリデーションチェックが失敗します。例えば、リクエストボディに content が含まれていない場合、バリデーションエラーを示す 400 Bad Request を返します。
レスポンスデータのバリデーションおよびJSON Schemaへ自動変換
リクエストボディのバリデーションと共に、FastAPIではレスポンスのバリデーションも簡単にできます。
これは@routerデコレーター内に response_model を指定することで実現できます。
※@app デコレーターを利用している場合、@app デコレーターのパラメーターとしてご指定ください。
@router.post( "/posts", status_code=status.HTTP_201_CREATED,response_model=PostCreatedResponse )
class PostCreatedResponse(BaseModel): """新しいランチ投稿のレスポンスモデル""" id: str = Field(serialization_alias="id") pk: str = Field(exclude=True) sk: str = Field(exclude=True) user_id: str = Field(serialization_alias="userId") timestamp: str = Field(serialization_alias="timestamp") content: str = Field(serialization_alias="content") image_key: str = Field(serialization_alias="imageKey") restaurant: str = Field(serialization_alias="restaurant") likes: list = Field(serialization_alias="likes")
これによって、ルーター関数が値を return した際、自動的に
response_model で指定したモデルに従って、リクエストボディのバリデーションチェック同様、レスポンスのバリデーションが行われます。
指定したモデルと一致しないデータが返された場合、FastAPIはエラーを発生させ、型安全性を保つことができます。
一般的に、APIのレスポンスとしてJSON Schemaを生成してからreturnするケースがありますが、FastAPIでは response_model パラメータを使用することで、この手間を省くこともできます。ルーター関数の戻り値(他のPydanticモデルインスタンス、普通のPython辞書型オブジェクト等)から自動的にJSONを生成してクライアントに返します。 PostCreatedResponse レスポンスモデルを見てみますと、exclude=True や serialization_alias="userId" などのオプションを使用しています。これはレスポンスシリアライズ時に適用されるオプションになります。
exclude=True: ルーター関数の戻り値から指定したキーを除外します。ここではpk, skのキーを除外しています。serialization_alias="userId": モデルインスタンスにおけるフィールド名をそのままシリアライズに使用するのではなく、他の形に変換するためにシリアライズエイリアスを指定します。フロントエンドアプリケーションのためのAPIである場合、キャメルケースに変換したいという使用用途もたくさんあるでしょう。
上記の仕組みにより、開発者はデータの構造や型について心配せずに、簡潔なコードで型安全なAPIを構築できます。FastAPIの便利な機能を駆使して、より効率的で信頼性の高いAPI開発が可能です。
DynamoDBとPydanticの組み合わせ
上記でPydanticとFastAPIの組み合わせについて説明しました。ではPydanticとDynamoDBの組み合わせはどうでしょうか。
DynamoDBデータ格納時のPydanticモデル活用
先ほどの POST /postsAPIのコードをもう一度見てみますと、データベースに関連するコードは以下のみで成り立っていると思います。
# DynamoDBに格納するための新規投稿レコード情報を準備 new_post_item = PostCreateToDB( **post.dict(), user_id=user_info.username, ) # DynamoDBに新規投稿レコードを格納 lunch_blog_table.create_post(new_post_item)
実はDynamoDBにデータを格納する前に、PostCreateToDB モデルを活用してデータの準備を行っています。
class PostCreateToDB(BaseModel): """新しいランチ投稿のデータベース登録用モデル""" id: str = Field(exclude=True) # model_dump()で除外されるように設定 pk: str = Field(default="Posts", serialization_alias="PK") sk: str = Field(serialization_alias="SK") user_id: str = Field(serialization_alias="UserId") timestamp: str = Field(default_factory=generate_current_timestamp, serialization_alias="Timestamp") content: str = Field(serialization_alias="Content") image_key: str = Field(serialization_alias="ImageKey") restaurant: str = Field(serialization_alias="Restaurant") likes: List[str] = Field(default=[], serialization_alias="Likes") @model_validator(mode="before") @classmethod def generate_values(cls, values: dict[str, Any]) -> dict[str, Any]: """id, skを生成するメソッド""" id = generate_uuid() values["id"] = id values["sk"] = f"Post#{id}" return values
一見複雑に見えますが、このモデルでは以下のことを実現しています。
- DynamoDBに格納するための「ランチ投稿」Itemの必要なスキーマを定義しています。
POST /postsAPIのリクエスト情報から得られなかったが、データベース内のデータ管理に必要なフィールドの値を生成します。- PKに"Posts"という文字列をデフォルト値と設定
- 投稿の識別番号として、PostIdのUUIDを生成(DynamoDBでは次のSKの形で管理)
- SKに「Post#{自動的に生成されたUUIDのPostId}」文字列を格納
- Timestampに格納するためのUNIX Timestampを生成
- Likesに空のリストをデフォルト値として設定
- DynamoDBに格納する際、各フィールドのキー名をPython実装用のスネークケースからDynamoDBのスキーマ用のパスカルケースに変更設定(DynamoDBでは特にAttributeの命名規則が決まっていませんが、可読性を上げるためパスカルケースを使用することが多いでしょう)
上記によって、new_post_item を PostCreateToDB のモデルインスタンスで作成すると、DynamoDBにデータを格納する際、以下の簡単な記述ができます。
# api/api/databases/tables/lunch_blog.py class LunchBlogTable(DynamodbTable): """LunchBlogテーブルを操作するためのクラス""" def __init__(self): # (省略) def create_post(self, post: PostCreateToDB): """新しいランチ投稿を作成""" try: self.table.put_item( Item=post.model_dump(by_alias=True), ) except ClientError as err: logger.exception(err) raise
上記で by_alias=True を指定した理由は PostCreateToDB インスタンスを辞書型に変換する際、キー名を serialization_alias で指定したものを使用するようにするためです。
データモデリングを全てPydanticで一元管理することによって、DynamoDBの処理コードでは、特に複雑なコードを追加せずに、型の管理も不要になります。
DynamoDBからデータを取得した後のPydanticモデル活用
先ほど POST /posts APIを例としてみていましたが、GET /posts APIはどうでしょうか。
ルーターの関数は以下になっています。
# api/api/routers/post.py # (省略) @router.get("/posts", status_code=status.HTTP_200_OK, response_model=PostInfoListResponse) def get_posts(): """全てのランチ投稿を取得""" try: posts = lunch_blog_table.get_posts() except ClientError as err: logger.exception(err) raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR) else: return posts
lunch_blog_table.get_posts() 関数でデータベースからデータを取得し、そのまま return しています。get_posts() の中身はどうなっているのでしょうか。
# api/api/databases/tables/lunch_blog.py def get_posts(self): """全てのランチ投稿を取得""" try: response = self.table.query( KeyConditionExpression=Key("PK").eq("Posts") & Key("SK").begins_with("Post#"), ) except ClientError as err: logger.exception(err) raise else: return response["Items"]
これも至ってシンプルの実装で response["Items"] を返却しています。詳細はboto3の仕様をご確認いただけますと幸いですが、これはboto3の query() 関数の戻り値で、ItemsAttributesを切り取ったものになっていますね。response["Items"] にはDynamoDBの各カラムがキーになっているDynamoDBのItemオブジェクトの配列になっており、以下のようなものを想定しています。
[
{
"PK": "Posts",
"SK": "Post#ddba3f07-9079-4328-a779-e9708576f6fd",
"UserId": "bde2a27e-1611-4f00-ae5b-df597500409a",
"Timestamp": 1702853246,
"Content": "今日ここ行ってきました!とても良かった!",
"ImageKey": "lunch.jpg",
"Restaurant": "AAA店",
"Likes": []
}
]
ルーター関数では上記の配列をreturnしていますが、実際のAPI仕様では、PK, SKの情報は不要としており、その代わりに id 情報が必要のように、設計していました。また、POST API同様、フロントエンドのためのAPIであるため、各キーはパスカルケースではなく、キャメルケースで返したいと思います。
ここで、レスポンスをAPI仕様通りに実装するために、@router デコレーターのパラメータとして response_model=PostInfoListResponse を指定しています。これを指定することによって、レスポンスを返却する前に以下の動作が行われます。
- データベースから取得したデータが
PostInfoListResponseモデルのスキーマに従っているかのバリデーションチェック - データを
PostInfoListResponseモデルのシリアル設定(excludeオプション、serialization_aliasオプションの設定等)に従ってデータのシリアライズを行って、クライアントに返却する。
PostInfoListResponse は以下のように定義しています。
class PostInfoInDB(BaseModel): """DynamoDBに格納されているランチ投稿情報のモデル""" pk: str = Field(validation_alias="PK") sk: str = Field(validation_alias="SK") user_id: str = Field(validation_alias="UserId") timestamp: str = Field(validation_alias="Timestamp") content: str = Field(validation_alias="Content") image_key: str = Field(validation_alias="ImageKey") restaurant: str = Field(validation_alias="Restaurant") likes: List[str] = Field(validation_alias="Likes") class PostInfoReponse(PostInfoInDB): """ランチ投稿情報のレスポンスモデル""" id: str pk: str = Field(validation_alias="PK", exclude=True) sk: str = Field(validation_alias="SK", exclude=True) user_id: str = Field(validation_alias="UserId", serialization_alias="userId") timestamp: str = Field(validation_alias="Timestamp", serialization_alias="timestamp") content: str = Field(validation_alias="Content", serialization_alias="content") image_key: str = Field(validation_alias="ImageKey", serialization_alias="imageKey") restaurant: str = Field(validation_alias="Restaurant", serialization_alias="restaurant") likes: list = Field(validation_alias="Likes", serialization_alias="likes") @model_validator(mode="before") @classmethod def generate_values(cls, values: dict[str, Any]) -> dict[str, Any]: """idを生成するメソッド""" id = values["SK"].split("#")[1] values["id"] = id return values PostInfoListResponse = RootModel[List[PostInfoReponse]]
先ほど、GET /posts APIのレスポンスは PostInfoListResponse モデルに従わないといけないことを説明しました。ただし、上記の定義を見ると PostInfoListResponse は
PostInfoListResponse = RootModel[List[PostInfoReponse]]
と定義されています。これは GET /posts APIのレスポンスは PostInfoReponse モデルに従っている要素のリストである必要があると意味しています。
PostInfoReponse では、以下のように
user_id: str = Field(validation_alias="UserId", serialization_alias="userId")
validation_alias オプションと serialization_alias を使用しているところがたくさんありますが、なぜ?と疑問に思っている方がいるかもしれません。これについて説明します。
先ほどDynamoDBから取得したデータをそのまま返却し、PostInfoListResponse によってバリデーションチェックを行っていると説明しました。ここの過程では以下の動作が行われています。
- データベースからデータを取得した後、
PostInfoListResponseのインスタンスを作成し、同時にバリデーションチェックを行っています。インスタンス作成のための入力データはDynamoDBから取得したものになりますので、各キーはパスカルケースになっています。そのためバリデーションチェックが失敗しないよう、validation_aliasオプションを使用して、DynamoDBのパスカルケースのキーを指定します。 - インスタンスを作成後、インスタンスからシリアルデータを生成し、クライアントに返却します。ここではAPI利用者の利便性のために、キャメルケースに変換するために
serialization_aliasオプションを使用します。
上記のように、Pydanticモデルを使用することで、様々な命名規約に柔軟に対応できると思います。
また、記事の先頭あたりで説明があったように、pydanticのモデルは通常 BaseModel というクラスを継承して作成すると話しましたが、PostInfoReponse モデルは PostInfoInDB モデルを継承しています。実はこの書き方すると、PostInfoReponse も BaseModel を継承していることに変わりはないですが、PostInfoInDB クラスを別途で作成した理由はこのクラスで単純にDynamoDBの構成を定義したいんです。上のコードから分かるように GET /postsAPIのレスポンスのために PostInfoReponse では色々カスタマイズを入れており、GET /postsAPIのレスポンスモデル専用になっています。ただし、実際の開発では様々なケースでDynamoDBの構成から別のカスタマイズをしたいというケースもあると思います。PostInfoInDB を定義することで、別の使用ケースでもこのクラスを継承してカスタマイズできます。ここを意識すると実装も簡単に進めることがでいるでしょう。
DynamoDBのデータ型とPydanticのデータ型の対応表
DynamoDBの主な型定義をPydanticで定義する場合の対応表をまとめました。
| DynamoDB データ型 | Pydantic モデルのフィールド例 |
|---|---|
| String | field_name: str |
| Number (Integer) | field_name: int |
| Number (Float) | field_name: float |
| Boolean | field_name: bool |
| List (一種要素リスト) | field_name: List[element_type] |
| List (混在要素リスト) | field_name: List[Union[element_type_1, element_type_2]] |
| Map (Nested Object) | field_name: Dict[str, element_type] |
| Binary | field_name: bytes |
| Set | field_name: Set[element_type] |
| Null | field_name: Optional[None] = None |
バリデーションエラーのハンドリング
記事の内容で、所々「バリデーションエラーが発生してしまいます」という書き方をしていたかと思います。
FastAPIの仕様により、バリデーション検証において、以下のエラーが発生します。
- RequestValidationError: リクエストのバリデーションチェックエラー時に発生
- ResponseValidationError: レスポンスのバリデーションチェックエラー時に発生
上記を使用して、アプリケーション全体を共通して、以下のエラーハンドリングの設定すると便利です。
- RequestValidationError発生時: リクエストに不正なデータが含まれているため、
HTTP 400 Bad Requestエラーを返却します。 - ResponseValidationError発生時: 予想したレスポンスと異なるデータを返却している処理が行われているため、
HTTP 500 Internal Server Errorエラーを返却します。
# api/api/main.py # (省略) from fastapi.exceptions import HTTPException, RequestValidationError, ResponseValidationError # (省略) # リクエスト不正エラーハンドリング @app.exception_handler(RequestValidationError) async def request_validation_exception_handler(request, exc): """リクエストのバリデーションエラーをハンドリングする RequestValidationErrorが発生する時、400 Bad Requestを返す """ logger.error(f"RequestValidationError: {exc}") return JSONResponse(status_code=400, content={"message": "Bad Request."}) # レスポンス不正エラーハンドリング @app.exception_handler(ResponseValidationError) async def response_validation_exception_handler(request, exc): """レスポンスのバリデーションエラーをハンドリングする ResponseValidationErrorが発生する時、500 Internal Server Errorを返す """ logger.error(f"ResponseValidationError: {exc}") return JSONResponse(status_code=500, content={"message": "Internal Server Error."})
実装上の注意点
- この記事ではPydantic(v2)を使用しています。今年リリースされたばかりのバージョンであり、インターネット上ではv1の書き方をたくさん紹介されていると思います。実装時は必ずPydantic(v2)の仕様を確認してから実装してください。
- Pydanticモデルの型定義をAPI仕様、DynamoDB仕様に合わせるため、型の記述に注意してください。int, strなど簡単な型は問題がないと思われますが、他の型にするためには多少工夫を加える必要があると思います。APIの型確認は実装しながら自動生成されたOpenAPIドキュメントを開きながら、元のOpenAPI設計書と比較したほうが確実でしょう。
- Pydanticを採用することで、データモデリングの一元管理が実現され、コードの可読性が向上する一方で、モデルを適切に設計せずに複雑なモデルを作成すると、逆にモデルの内容を理解しにくくし、可読性を低下させる可能性があります。モデルの作成は慎重に行う必要があり、特にチーム内で共有された設計ガイドラインに基づいて作成されるべきでしょう。
まとめ
サーバーレス構成で、FastAPI、DynamoDBを利用しながら、Pydanticで型安全の実装方法をご紹介しました。Pydanticを使用すると型安全性が保たれるだけでなく、バリデーション、レスポンスのシリアライズなども簡単に実装できて、安全性を保ちながら実装速度を上げることができるかと思います。