はじめに
こんにちは!Insight Edgeでデータサイエンティストとして働いている五十嵐です!
最近花粉症が大変すぎて飲み薬に目薬に点鼻薬と毎日薬漬けです。鼻うがいも毎日してます!
今回は、AIの公平性について少し調べてみようかなと思い、調査内容を簡単にまとめます。本記事の内容は、基本的に、A Survey on Bias and Fairness in Machine Learning (Mehrabi et al.)を参考にしています。本論文は、初稿が2019年8月ですが、何度か改修され、last revised が2022年1月となっております。被引用件数が2,000件を超えているので、この分野のsurvey論文としてはかなり有力なものではないでしょうか。
本記事は、様々な人にも興味を持って頂けるよう、技術的内容にはあまり触れずに紹介しようと思います!紹介論文は、34ページなので、今回紹介できる部分は極一部であることをご理解頂ければと思います。また、私が未熟で不勉強な部分も多いため、もし間違った解釈があった場合は優しくご指摘頂けますとありがたいです!!
「公平」とは
そもそも、「公平」とはなんなのでしょうか。AIの公平性についての話をする前に、そもそも「公平」の定義とはどのようなものなのか説明します。
様々な分野や考え方によって「公平」の定義は異なる為、一意に決めることは非常に難しいですが、本論文では、次のように説明されています。
“ absense of any prejudice or favoritism toward an individual or group based on their inherent or acquired characteristics ”.
直訳すると、「個人・グループに対して、先天的、または後天的な特徴によっていかなる偏見や好意がないこと」でしょうか。納得性が高い定義のように思います。
※ 似たような意味で「公正」という言葉がありますが、「公平」と「公正」の正しい言葉の使い分けに自信があまりないので、本記事ではfairnessを公平、公平性と訳しております。
何故、AIの公平性が重要なのか
人間の判断に度々偏りが生じてしまうように、AIの判断も公平でなければ、我々人間と同じように差別的な判断をしてしまったり、偏った判断をしてしまう可能性があります。
近年は、AIシステムやアプリケーションが日常生活の中で広く使われるようになってきており、人生に大きく関わる分野でAI技術が使われるようになってきています。この為、以前より不公平なAIのもたらす影響が大きくなり得ると言えます。
例えば、不公平なAIシステムの例として頻出なものに、職業推薦システムがあります。同一条件であるにも拘らず、女性というだけで男性より低い評価になってしまう、つまり、性別の違いだけで推薦する職業やその収入が大きく違ってしまうという例は聞いたことがある人も多いのではないでしょうか。
不公平になる原因と不公平なAIが生む悪循環
不公平なAIシステムは一体どのような原因で生み出されてしまうのでしょうか。
それは、データやアルゴリズムに隠れた、あるいは無視されたバイアスです。(具体的なバイアス例については後述します。)
また、万が一、不公平なAIシステムが世の中で使われるとどうなるのでしょうか。
論文では、偏ったアルゴリズムの結果が、ユーザー体験に影響を与え、データ、アルゴリズム、ユーザーの間でフィードバックループが生じてしまい、既存の偏りを永続させ、さらに増幅させる可能性がある、と説明されています。
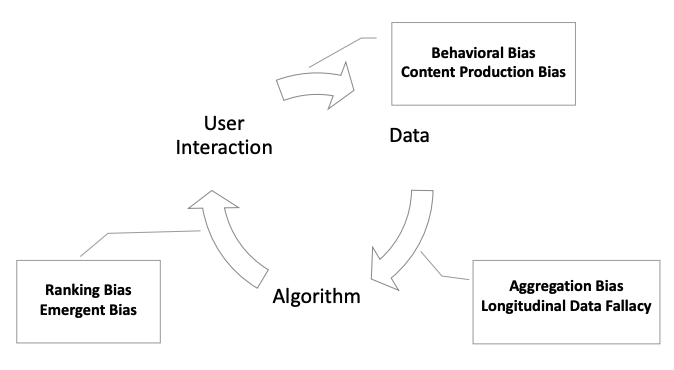
学習データにバイアスがある場合、それを学習したアルゴリズムはそのバイアスを反映して予測をしてしまいます。また、データにバイアスがなくても、アルゴリズム自体が特定の設計上の仮定によりバイアスを有した挙動を示すことがあります。このようなバイアスを持つアルゴリズムの結果は、実世界のシステムに投入され、ユーザーの意思決定に影響を与え、よりバイアスのあるデータを生み出してしまいます。
バイアスの例
ここまで、不公平なAIシステムの原因としてデータやアルゴリズムに存在するバイアスであることを説明しました。
それでは、どのようなバイアスがあるのでしょうか。
ここでは、論文で紹介されていたバイアスについて、データに関するバイアスの一部を紹介します。
計測バイアス(reporting bias)
特定の特徴をどのように選択、利用、計測するかによって発生するバイアスです。
代表バイアス(representation bias)
データ収集プロセスにおいて、母集団からどのようにデータをサンプリングするかに起因するバイアスです。
(例) 下図に示すように、ImageNetの地理的な多様性の欠如は、西洋文化に対するバイアスに繋がるとされています。

社会的バイアス(social bias)
他人の行動が我々の判断に影響を与える時に生じるバイアスです。
(例) 低い得点で何かを評価・レビューした場合に、他の人が高い評価をしていると、自分の評価が厳しすぎると考えて得点を変更してしまうことで生じるバイアスです。
歴史的バイアス(historical bias)
世の中に既に存在する偏りや社会技術的な問題であり、完璧なサンプリングと特徴選択を行えたとしても、データ生成プロセスから染み込んでくる可能性のあるバイアスです。
(例) 2018年においては、フォーチュン500のCEOのうち女性が5%しかいないことに起因し、CEOの画像検索結果が男性CEOに偏っていました。これは、現実を反映してものではありますが、検索アルゴリズムがこの現実を反映すべきかは検討が必要です。
他にも、様々なバイアスが紹介されていましたが、バイアスを全て紹介するのが本記事の目的ではないので、詳細を知りたい方は論文をご確認頂ければと思います。
どこからが問題なのか
これまで、AIシステムの原因となり得る様々なバイアスについて説明してきましたが、具体的にどこからが問題となるのでしょうか。バイアスではなく、正当な特徴であるかどうかの判断はどのようにすれば良いのか、この議題についても下記のような説明がされています。
差異が正当に説明可能かどうか
異なる集団間の待遇や結果の違いは、場合によってはある属性によって正当に説明されることがあります。このように、「差異が正当化され説明される状況では、それは問題にはならず、説明可能である」と記載されています。
この例として、平均して男性の方が女性より平均年収が高いという場合に、平均して女性の方が労働時間が短いという属性があれば、この男女差は説明可能であり、許容される、と説明されています。
個人的には、労働時間の男女差が何故生じているのかまで踏み込んで考えなければ扱いが難しい問題だとは思いますが、このようにある特徴量によって説明される場合は問題ないと見なされることが多いみたいです。
上記とは違い、どのような属性によっても正当に説明されない差異の場合は問題となります。
不公平なAIを作り出さないために、どうすれば良いのか
それでは、不公平なAIを作り出さないためにはどのようにすれば良いのでしょうか。
これまで紹介してきました、不公平なAIの原因となるバイアスは、大きくデータ由来のものと、アルゴリズム由来のものがあります。これらのバイアスを避けるために紹介されていた方法について、いくつか説明します。
データ由来のバイアス対策
データ由来のバイアスを避けるために、下記の内容が重要であると紹介されています。
- 「全てのデータセットは、データ管理者によってなされたいくつかの設計上の決定の結果である」ことを理解する.
- 扱っているデータの生成プロセスを正しく・詳細に理解する.
- 因果モデルや因果グラフの利用を検討する.
それぞれについて説明していきます。
1. 「全てのデータセットは、データ管理者によってなされたいくつかの設計上の決定の結果である」ことを理解する
解析に用いるデータには、データ管理者が存在します。その管理者には何か目的がありデータを作成・収集しています。また、その管理者にもコントロールすることが難しい因子がデータそのもの、または、データ収集環境に存在する可能性があります。このことを正しく理解することで、データに存在するバイアスの調査にも取り掛れますし、後に説明するデータ生成プロセスの理解に時間を掛けることにも繋がります。
本論文では、対策として、データセット作成、特性、動機、偏りを報告するデータシートの作成をルール化する、というようなデータ利用時の良い習慣を提唱するアプローチもいくつか紹介されています。
2. 扱っているデータの生成プロセスを正しく・詳細に理解する
データを扱う際、そのデータだけを見ていても取得できる情報は限られています。データ背景、データ生成プロセスなどを詳細に理解しなければ正しくデータを理解することは非常に難しいです。この対策として、例えば、データドメインを調査し、データ生成プロセスを詳細に理解することが挙げられます。データ生成プロセスを正しく理解することで、前処理によってバイアスを取り除くなどの対処ができる場合があります。また、学習過程においては、目的関数に変更を加えたり、制約を課すなどしてバイアスを取り除ける場合があります。
3. 因果モデルや因果グラフの利用を検討する
2.と同様で、データを扱う際、そのデータだけを見ていても取得できる情報は限られています。この対策として、因果モデルや因果グラフの利用が多数提案されています。因果グラフはデータだけではなく、その背景や生成プロセスなど、交絡因子に関する因果関係を表現することができます。
アルゴリズム由来のバイアス対策
アルゴリズムもバイアスを持つことがあります。その中の一つ、帰納バイアスについて紹介します。
帰納バイアスとは、簡単にいうと「そのアルゴリズムが前提としている仮定により発生するバイアス」です。具体例として、ViT(Vision Transformer)とCNN(Convolutional Neural Network)の学習データ量と精度の関係についての議論で知っている人も多いのではないでしょうか。CNNは「画像データは近傍の(局所的な)情報が重要である」という仮定を持つ、帰納バイアスのあるモデルです。これに対して、ViTは強い仮定をおいていないため、強い帰納バイアスを持ちません。CNNが比較的少ないデータ数の場合は、ViTより高い精度が出やすいのはこの帰納バイアスが上手く機能している為と考えられています。逆に、帰納バイアスの弱いViTは十分なデータセットを用いた場合にはCNNよりも高い精度を誇ります。このように、アルゴリズムの持つバイアスによって使い所が変わりますし、データ構造やその目的によって適切なアルゴリズムを選択することが理想的だと言えます。また、帰納バイアスなど、使用するアルゴリズムの性質を正しく理解していないとその使い所や解釈を間違えてしまうため、アルゴリズムの持つバイアスを理解することは非常に重要です。
他にアルゴリズムの持つ仮定として、データや残差の分布が正規分布を仮定するなど様々ありますが、正しく利用し正しく解釈するには、いずれもデータとアルゴリズムの理解が必要です。
最後に
論文の一部を簡単に紹介してきましたが、正直かなり難しい問題であることを再認識できました。論文を読んだだけでも、そのタイトルにある” Bias and Fairness in Machine Learning ”という議題がいかに難しいかが実感できます。また、バイアスについてもご紹介した以外に様々あり、世の中からあらゆるバイアスを完全に無くすことはかなり難しいことも実感します。しかし、本記事で説明したように、データの生成プロセスを意識したり、使用するアルゴリズムの性質を理解することで、AIシステムにバイアスが入り込む可能性を低くする取り組みができます。 また、対策についても、本記事でご紹介できた以外にも様々なアイデアや取り組みが数多くあるということはご理解頂ければと思います。
今回紹介できた部分は極一部ですが、この記事が誰かがAIの公平性について考える一助になってくれれば幸いです。