この記事はInsight Edge Advent Calendar 2025の2日目の記事です!🦌🦌🦌🦌🛷🎅1日目のニャットさんの記事で紹介された、テックブログレビューエージェントのサポートのもと、なんとか間に合いました。会社でのアドベントカレンダーは初の試みですが、お祭り感があって楽しいですね。
はじめに
はじめまして。Insight Edgeデータサイエンティストのnakanoです。
LLMアプリケーションの開発において、「とりあえず動くもの」を作ることは比較的容易です。しかし、実用的なレベルにまで仕上げることは難しい課題です。その理由は、LLMアプリの良し悪しを測る評価軸が曖昧なままだと、改善の方向性が定まらず開発が迷走してしまうからです。そこで今回は、この課題を解決するアプローチとして、評価駆動開発による進め方をご紹介します。
本記事では、「書き込みや線引きがある紙面画像から、情報を抽出するアプリ」を題材に、評価駆動によるLLMアプリケーションの開発プロセスを解説します。
目次
プロジェクトの説明
今回開発するLLMアプリケーションは、書き込みや線引きがある紙面画像から、情報を抽出するためのツールです。
背景・課題
私は最近、GoogleのAIツール「NotebookLM」の音声解説機能にハマっています。NotebookLMはドキュメントをアップロードすると、AIが要約や音声解説を生成してくれるサービスです。昔読んだ論文や備忘メモをアップロードするだけで、音声解説を作れるため内容を楽しく振り返ることができます。しかし紙の本は、デジタル化する必要があります。また、私は本を読む際に、気になる箇所に線を引いたり、余白にメモを書き込んだりする癖があります。これらの個人的な情報も一緒にNotebookLMに取り込みたいと考えているため、標準的なOCRツールでは対応できません。
作るもの

そこで次の要望を満たす、紙面情報抽出アプリを作成します。
- 本文の抽出 : 撮影した紙面の画像から、本文テキストを抽出できること。
- 本文以外の情報の抽出 : 紙面の図や表の内容を音声解説に活用できるレベルでテキスト化できること。
- 書き込みや線引き情報の抽出(重要) : 読書時に本に書き込んだメモ書きや線引き情報を抽出し、読者がその時気になったポイントをテキスト化できること。
これらの要望を満たすアプリを作ることで、過去に読んだ紙の情報をポッドキャスト化し、楽しく振り返ることができるようになります。
評価駆動開発でLLMアプリケーションを育てる
評価駆動開発とは
評価駆動開発とは、最初に評価基準を設計し、その基準に基づいてアプリケーションを反復的に改善していく手法です。 ただし、プロジェクトの序盤では評価基準自体がわからなかったり、データを見ていくたびに新しい評価基準が見つかったりします。 そのため本記事では、評価精度の改善以外に、評価基準の修正も含めて反復的に開発を進めていきます。
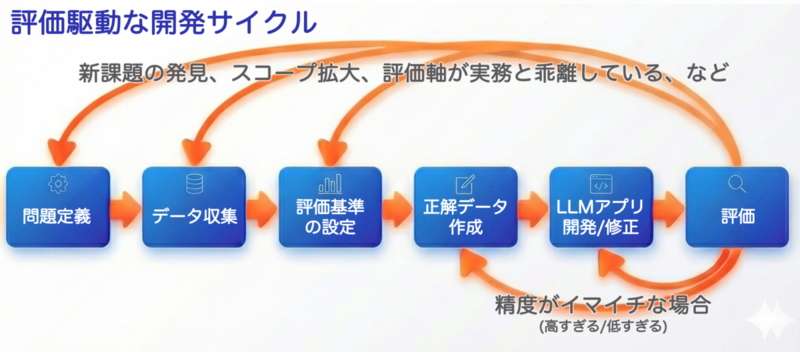
このフローは、Eval Driven System Design - From Prototype to Productionの記事を参考に、自分のプロジェクトに合わせてアレンジしたものです。過去にこちら(データサイエンティストが評価駆動手法を使ってみた〜家計簿分類プロジェクトの実践記〜 - Insight Edge Tech Blog)のテックブログで触れているため、よければご参照ください。
バージョン1の開発
評価まで含めた最初のサイクルを素早く回すために、バージョン1では本文テキストとページ番号を抽出する程度のシンプルなLLMアプリケーションを作成します。
1-1. 評価基準の設計
最初に評価基準を設計します。抽出した情報(ページ番号,本文テキスト)の正確性を評価するための指標です。
- ページ番号(page_number)は、完全一致で評価します。
- 理由はページ番号は1文字でも間違うと意味が変わってしまうためです。
- 本文テキスト(context)は、レーベンシュタイン距離を正規化したものを採用します。
- 理由は、シンプルなため解釈性が高く、部分的な誤りを評価できるためです。
Pythonでの実装例は以下の通りです。
# 抽出アプリの出力フォーマット class ExtractedPageContentV1(BaseModel): context:str = Field(..., description="書面の画像から抽出された本文") page_number:str = Field(..., description="ページ番号") # 正解データのフォーマット(たまたま、出力フォーマットと同じ) class GroundTruthV1(BaseModel): context:str = Field(..., description="書面の画像から抽出された本文") page_number:str = Field(..., description="ページ番号") # 本文テキストの正確性を評価する関数 import Levenshtein def calculate_normalized_distance(pred_context: str, true_context: str) -> float: distance = Levenshtein.distance(pred_context, true_context) normalized_distance = 1 - distance / max(len(pred_context), len(true_context)) return normalized_distance
1-2. 正解データの準備
次に正解データを作ります。最初は5~20件程度で良いと考えます。理由は、プロジェクトを進めていく中で要件やスコープが変わることも多く、最初から大量の正解データを作成するのは非効率だからです。そのためまずは全体を代表するような5件のデータをしっかり作成します。

実際にPythonで表現すると以下のようになります。
# 正解データ(手作業で作る) ground_truth_dataset_v1 = [ { "input_path": "./data/中国農村の現在/中国農村の現在 - 70.jpg", "ground_truth": { "page_number": "56", "context": "とぎ汁などを混ぜてグツグツ煮て作るので、そのコストはゼロである。\n" " 養豚は自家消費のためでもある。\n" # 中略(実際には全12行のテキストを記載) "えあるという。そのように生産性の低い農地経営の中で、養豚こそが彼の主な収益源とな\n" "っているのである。トウモロコシは養豚の飼料となり、もし余れば販売することも可能。そ", } }, # ... (他の4件も同様に作成) ]
1-3. LLMアプリの開発
次に処理を実装します。 最初のサイクルなので、シンプルですぐに実装できるアプリケーションを作成します。 プロンプトも特に工夫はせず簡単に記述します。
def extract_page_content_v1(image_path: str) -> ExtractedPageContentV1: with open(image_path, "rb") as f: image_bytes = f.read() response = client.models.generate_content( model="gemini-2.5-flash", config={ "response_mime_type": "application/json", "response_json_schema": ExtractedPageContentV1.model_json_schema(), }, contents=[ types.Part.from_bytes( data=image_bytes, mime_type="image/jpeg", ), "あなたは、書面の画像から記述内容を抽出する専門家です。" "page_numberには、このページのページ番号を整数で入れてください。" "もし、ページ番号がわからない場合は空欄にしてください。" "contextには、記載されている日本語をすべて抽出してください。" "ただし抽出するテキストは本文だけで、ヘッダーやフッター、ページ番号などは含めないでください。" "改行がある位置には改行コードを入れてください。" "段落の最初の空欄には全角スペースを入れてください。" ], ) response_json = response.parsed result = ExtractedPageContentV1.model_validate(response_json) return result
実際に抽出された情報は以下のような感じです。 パッと見は期待通り文字情報を抽出できています。
ExtractedPageContentV1(
page_number='1',
context='まえがき\n今世紀に入って、中国は世界最大 <略> りの農民国家で、正式な統計は'
)
1-4. 評価
実際に正解データを利用して評価を行います。結果は以下のとおりです。
| No. | ページ番号一致 | 本文スコア(正規化レーベンシュタイン距離) |
|---|---|---|
| 1 | True | 89.9% |
| 2 | True | 81.4% |
| 3 | True | 35.5% |
| 4 | True | 96.9% |
| 5 | True | 95.1% |
ページ番号は全件正解、本文テキストも平均80%近くの精度が出ています。 一方で、3件目のファイルの精度が極端に低いことがわかります。 各データを確認したところ以下のような課題が見つかりました。
- 課題1 : 図表を誤って本文として抽出してしまっている
- 3件目のファイルの精度が35%と極端に低い要因は、図に記載されたテキストを本文として抽出していたためでした。
- バージョン1では、本文テキストだけを対象としているため、図表の情報は含めないことが期待する動作でした。
- バージョン2での対応として、プロンプトに「図表の情報に含まれるテキストは含めないでください。」を追加することにします。
- 課題2 : 改行コードの入れ忘れ
- 全ファイル共通して、改行コード
\nの入れ忘れのために精度が落ちていることもわかりました。 - 改行コードは、1ページの中に10数個あるため、全体的な精度への影響は無視できません。
- 改善施策としては、プロンプトを修正して改行コードの入れ忘れを防止することも考えられます。
- しかし、改行コードの有無は最終的な用途への悪影響はありません。
- これは評価指標と実務の嬉しさが乖離しているため、次のステップでの対応としては、評価時に改行コードの有無を無視するように評価基準を調整します。
- 全ファイル共通して、改行コード
- 課題3 : 最初/最後の行は、撮影時に影が映り込みやすく誤認識が多い。
- 紙面を撮影している都合上、最初と最後の行は、撮影時に影が映り込みやすく、誤認識が多いことがわかりました。
- 逆に最初と最後の行が正確に認識できている場合、中間の行も比較的正確に認識できていると考えられます。
- その他の課題 : その他の細かい誤認識もいくつか見つかった
- 「て」を「で」と変換するなど、単純なOCRミス。
- 「もし余れば販売することも可能。」を「もし余れば市場に出すことも可能。」と、意味を変えるような誤認識。
- 段落の開始を示す、全角スペースの入れ忘れ。
- 性能以外課題 : 性能以外の課題として以下のようなものもある。
- 正解データの作成に時間がかかりすぎる。
- グラフや地図の情報を抽出できない。
- 書き込みや、線引き情報を抽出できない。
バージョン2の開発
バージョン1の課題を踏まえて、バージョン2では以下のように改善を行います。
- 評価時に、改行コードの有無は無視する。改行コードを正確に抽出できるかどうかは、最終的な用途にとって重要ではないため。
- 本文テキストの精度は、最初と最後の行だけで評価する。撮影の都合上、最初と最後の行は陰になりやすくOCRの難易度が高いため。
- 図表の有無も判定する。図表の要約も行わせるが、評価はしない。理由は、工数が増えるため。
- 線引きや書き込み情報の抽出精度を評価する。読者が気になったポイントを抽出することが本アプリケーションの重要な目的であるため。
- その他の細かい発生したミスを改善するようにプロンプトを修正する。例えば、OCRミスや段落開始の全角スペース入れ忘れなど。
2-1. 評価基準の修正
評価基準は以下のように修正します。 正解データ作成の工数を削減しつつ、実務の嬉しさと一致するように微調整しています。
- 本文テキスト(context)
- 最初の行と最後の行についてそれぞれのレーベンシュタイン距離を正規化したものを採用します。
- 正解データから最初の行と最後の行の文字数を抽出し、その部分だけを評価対象とします。
- 評価時に改行コードの有無は無視します。
- 図表の有無(has_figures)
- 真偽値での完全一致評価を行います。
- 線引きテキスト(highlighted_texts)
- 抽出したテキストの
と で囲まれた部分をリストとして抽出します。 - 正解データと部分一致でマッチングを行い、マッチング率を算出します。
- 抽出したテキストの
- 書き込みテキスト(annotation_texts)
- 抽出した書き込みテキストのリストを正解データと部分一致でマッチングを行い、マッチング率を算出します
2-2. 正解データの修正と追加
評価基準の修正に伴い、正解データのフォーマットも修正します。
# 出力フォーマットの修正 # - 本文の中で線引きされている領域は<highlighted></highlighted>で囲むように指示する class ExtractedPageContentV2(BaseModel): page_number: str = Field(..., description="ページ番号") context: str = Field(..., description="書面の画像から抽出された本文") has_figures: bool = Field(..., description="図表の有無") figures_summary: str = Field(..., description="図表の要約") annotation_texts: List[str] = Field(..., description="書き込みテキストのリスト") #正解データのフォーマットの修正 class GroundTruthV2(BaseModel): page_number: str = Field(..., description="ページ番号") context_first_line: str = Field(..., description="本文の最初の行") context_last_line: str = Field(..., description="本文の最後の行") has_figures: bool = Field(..., description="図表の有無") annotation_texts: List[str] = Field(..., description="書き込みテキストのリスト") highlighted_texts: List[str] = Field(..., description="線引きテキストのリスト") ground_truth_dataset_v2 = [ { "input_path": "./data/中国農村の現在/中国農村の現在 - 70.jpg", "ground_truth": { "page_number": "56", "context_first_line": "とぎ汁などを混ぜてグツグツ煮て作るので、そのコストはゼロである。", "context_last_line": "っているのである。トウモロコシは養豚の飼料となり、もし余れば販売することも可能。そ", "has_figures": False, "annotation_texts": [], "highlighted_texts": [ "のちにようやく料理の塩辛さの一要因がわかった。", "「負担」とは、就学年齢の子供がいて現金収入が必要な事を指し", ], }, }, # ... (他の9件も同様に追加) ]
2-3. アプリの改善
改善方針を受けて、LLMアプリケーションを以下のように修正します。 出力形式とプロンプトのみ修正しています。
def extract_page_content_v2(image_path: str) -> ExtractedPageContentV2: with open(image_path, "rb") as f: image_bytes = f.read() response = client.models.generate_content( model="gemini-2.5-flash", config={ "response_mime_type": "application/json", "response_json_schema": ExtractedPageContentV2.model_json_schema(), }, contents=[ types.Part.from_bytes( data=image_bytes, mime_type="image/jpeg", ), "あなたは、書面の画像から記述内容を抽出する専門家です。" "page_numberには、このページのページ番号を整数で入れてください。" "もし、ページ番号がわからない場合は空欄にしてください。\n\n" "contextには、記載されている日本語をすべて抽出してください。" "ただし抽出するテキストは本文だけで、ヘッダーやフッター、ページ番号などは含めないでください。" "改行がある位置には改行コードを入れてください。" "段落の最初の空欄には全角スペースを入れてください。" "蛍光ペンや赤ペンで線引きされている部分は<highlighted>と</highlighted>で囲んでください。" "抽出するテキストは本文のみであり、図や表の情報に含まれるテキストは含めないでください。\n\n" "has_figuresには、このページに図表が含まれている場合はTrue、含まれていない場合はFalseを入れてください。\n\n" "figures_summaryには、図表がある場合、その内容を簡潔に要約して記述してください。\n\n" "annotation_textsには、このページに手書きの書き込みがある場合、その内容をすべてリスト形式で入れてください。" "もし書き込みがない場合は空のリストを入れてください。\n\n" ], ) response_json = response.parsed result = ExtractedPageContentV2.model_validate(response_json) return result
出力結果は以下のようになりました。今回もパッと見は期待通りの情報が抽出できていますが、実際の精度はどうでしょうか?
ExtractedPageContentV2( page_number='56', context=( 'とぎ汁などを混ぜてグツグツ煮て作るのとで、...途中略...' 'もし余れば<highlighted>販売</highlighted>することも可能。' ), has_figures=False, figures_summary='', annotation_texts=[], )
2-4. 評価
精度評価した結果は以下の通りです。 本文テキストの性能はやや改善されているように感じます。しかし、そろそろデータ数を増やして行かないと本当に適切なのか、わからなくなってきました。 また、線引きテキストや書き込みテキストの抽出性能も計測できています。
| No. | ページ番号一致 | 図有無の判定 | 本文開始行スコア | 本文最終行スコア | 線引きテキストスコア | 書き込みテキストスコア |
|---|---|---|---|---|---|---|
| 1 | True | True | 93.75% | 92.68% | 13.46% | 100.00% |
| 2 | True | True | 100.00% | 97.56% | 100.00% | 100.00% |
| 3 | True | True | 100.00% | 94.12% | 0.00% | 100.00% |
| 4 | True | True | 100.00% | 97.37% | 6.90% | 0.00% |
| 5 | True | True | 100.00% | 90.24% | 87.50% | 100.00% |
| 6 | True | True | 90.24% | 100.00% | 100.00% | 68.75% |
本文抽出に関しても90%程度は達していますが、20文字に1文字は誤認識があると考えるとまだまだ改善の余地があります。 またこの評価用データはひとつの本から抽出したものなので、他の本に対しても同様の精度が出るかは不明です。 次のバージョンからは、データを増やし課題に漏れがないかなど再度見直しながら改善を進めていきます。
線引きテキストや書き込みテキストスコアの精度はまだまだ改善の余地があります。 特に書き込みテキストスコアは、書き込みが無いページを書き込みなしと判断すれば100%となるため、現在の指標は不適切な気がします。
バージョン3, 4, 5, 6:ひたすらサイクルを回す
バージョン3以降は、次の表のとおり細かく修正していきました。線引きや書き込みの精度は割愛し、本文抽出についてだけ紹介します。
| バージョン | 方針と結果 |
|---|---|
| 3 | 方針 ・正解データを6件→50件に増やす。 ・新書以外にも技術書、横書きの本など多様な形態を追加する。 結果 ・データ種類を増やしたg、平均精度は概ね良好 ・一部大外しするケースが発生(原因:長い脚注など特殊なレイアウト) |
| 4 | 方針 ・長い脚注を無視するようプロンプトに追記する。 ・具体的には「各頁にある脚注など本文外のテキストは含めてはならない」と記載。 結果 ・大外しするケースは激減した。 ・数字や記号の全角半角の表記ゆれなど細かいミスが目立つ。 |
| 5 | 方針 ・プロンプトが長くなってきたため、Geminiのベストプラクティスに従い全体的に修正 ・参考: https://ai.google.dev/gemini-api/docs/prompting-strategies 結果 ・ 段落開始の全角スペース入れの遵守率が大幅に改善 |
| 6 | 方針 ・数字や記号の全角半角の表記ゆれが起きないよう細かくプロンプトに指示する。 結果 ・ 記号数字での減点が減少し、さらに精度が向上 |
これらの修正によって、下記のグラフの通り精度を着実に改善できました。
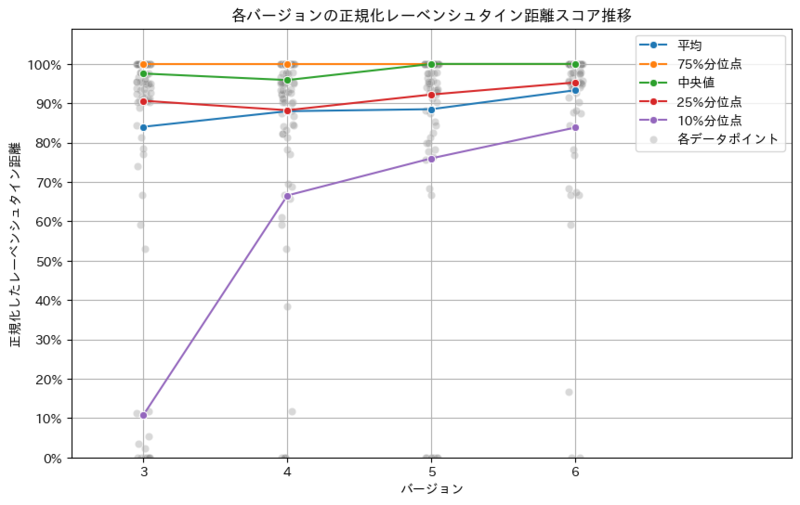
一方で依然として生成AI特有の課題は残っています。この点はGeminiではなく、専用のOCRモデルを組み合わせるなどの対策が必要と考えられます。
- 読みにくい箇所を想像する(前に述べたようにを前述したように)など
- 有名人と1文字違いの人名を誤認識する
まとめ
本記事では、「書き込みや線引きがある紙面画像から、情報を抽出するアプリ」を題材に、評価駆動開発でLLMアプリを実用化レベルまで育てるプロセスを解説しました。
評価駆動開発の3つのメリット
改善の方向性が明確になる
- LLMアプリはなんとなく良さそうと確認しながら進めがちですが、明確に方向性を決めることができます。
反復的な改善が可能
- LLMアプリ開発ではプロンプトを細かく調整していきますが、改善を確認しながら着実に改善できるようになります。
ステークホルダーとの合意形成がしやすい
- 定量的な指標により、開発進捗や品質を客観的に共有できるようになります。
実践での学び
- 正解データの作成コストは侮れない。最初は評価データを絞った方が良い
- 評価指標は、最終的な用途と乖離しないよう注意深く設計する
- 少数のデータで素早くサイクルを回し、課題を発見してから本格的にデータを増やす
おわりに
LLMアプリケーションを「とりあえず動く」状態から「実用レベル」に育てるプロセスを紹介しました。 本記事で紹介したプロセスを参考に、皆さんもLLMアプリケーションを着実に実用レベルまで育ててみてください。
明日のInsight Edge Advent Calendar 3日目は、因果推論とLLMに関する記事です!お楽しみに🎄🎄🎄🎄🎄