はじめに
本稿は、確率単体へ射影するアルゴリズムを調査した内容をまとめたものになります。この記事を書くきっかけは、知り合いから共有された(Wang, 2013)がシンプルでわかりやすく、他の手法にも興味が出てきたことです。調べていく中で、各アルゴリズムの計算速度も気になったので、簡易な性能比較も行いました。
確率単体への射影
問題設定
確率単体への射影(以下、本問題)は以下に示す凸最適化問題です。
但し、
とします。確率単体は上記の制約条件を満たす領域を指します。
最適解の導出方法
本問題の最適解はとなります。この
をどのように求めるかがポイントとなっており、さまざまなアプローチがあります。
ラグランジュ関数
(Boyd)ではラグランジュ関数を以下のように変形することで最適解を導出しています。
はラグランジュ乗数です。
((Boyd)では第3項目の係数は
でしたが、私の方で計算をすると
となりました。)
この関数を先にについて解くことで、上記の最適解
が得られます。
は、
を代入したラグランジュ関数を基に二分法などを用いることで求められます。
Sort and Scan
Sort and Scanという分類名称は(Yongzheng, 2022)に倣いました。
こちらの手法では最適解の導き方などがラグランジュ関数で示したものと異なります。詳細は割愛しますが、(Duchi, 2008)ではKKT条件をうまく組み合わせることにより、(Chen, 2011)では制約を指示関数として加えた目的関数に対するモーロー分解により、最適解を求めています。先と同様に、こちらもの値を求めないといけませんが、以下を計算することで容易に得られます。
入力の要素を大きいものから順番に並び替えてできた変数を
(
)とすると、
に対し、
となります。
KKT条件を解く場合、有効になる不等式制約がわからないと非常に解きにくいです。の定義に含まれる式は、それを効率よく見つけるものになっており、
はその個数を示しています((Chen, 2011)にはKKT条件が出てきませんが、入力に対する決定変数の大きさで同様の議論がなされています)。見つけられる理由は(Wang, 2013)にて、
の定義に含まれる式の挙動を確認するといった、シンプルでわかりやすい証明がなされています。
このアルゴリズムは入力のソートが計算時間のボトルネックになるため、ソートの仕方を工夫する研究が多く見られます。例えば、(Duchi, 2008)ではソートの計算量がになるような手法が提案されています。(Condat 2016)(Yongzheng, 2022)にはその他ソート手法や疑似コードなどがまとめられていますので、ご興味のある方はご覧になってください。
その他
(Wang, 2013)で述べられているように、有効制約法や内点法、一次法などの一般的なアルゴリズムでも本問題を解くことができます。それらのアルゴリズムは多くの文献で丁寧に説明がなされているため、詳細はそちらに譲ります。
性能比較
方法
上記で説明した(Boyd)、(Duchi, 2008)(ソート方法:ヒープソート)と一次法との計算速度を比較しました。計算速度の指標は、アルゴリズムを実行してから解が出力されるまでの計算時間としています。確率単体へ射影するは、
次元の一様乱数をその
ノルムで正規化し、各要素を
倍して得られるベクトルとしました。また性能比較では次元数
に対する計算時間を確認しており、各
での計算時間は
を
回生成し、個別に最適化した時の計算時間の平均値とします。
本稿での性能比較の目的は、(Boyd)、(Duchi, 2008)らの手法がよく使われるライブラリ(ソルバー)よりどのくらい速いのかを知ることとしています。これらの手法は「参考:実装コード」に示している通り、Python言語で実装しています。一方、今回はよく使われるライブラリにCVXPYを採用しており、そのソルバーであるOSQPはC言語で実装されています。実装言語は異なりますが、を十分大きくすると実装言語による影響は小さくなると考えられ、十分比較できるものと考えています。(OSQPは、本問題のような二次計画問題のデフォルトで使用されるソルバーで、一次法であるADMMをベースとしています。)
結果、所感
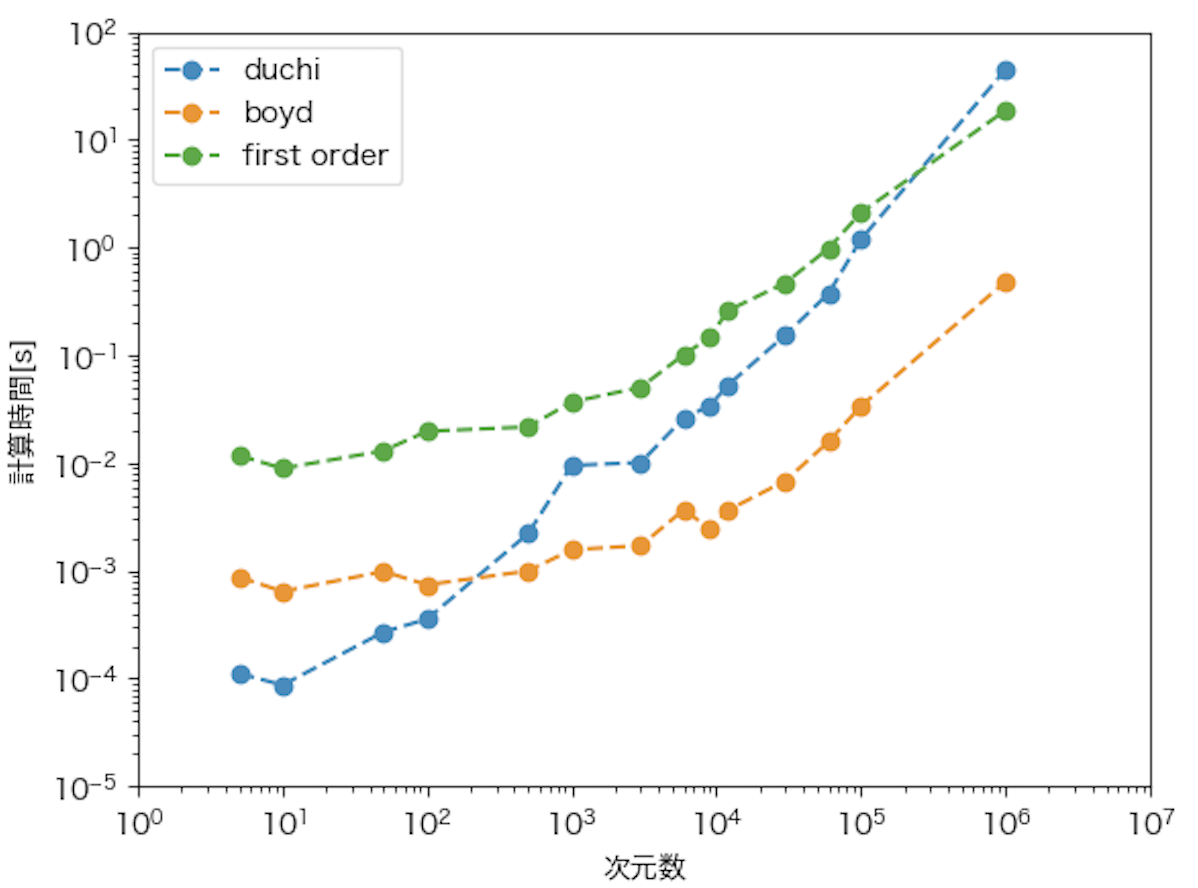
下のグラフは、を変えた時の各手法の計算速度を示しています。
が
程度までの時は(Duchi, 2008)が最も計算時間が速く、それ以降では(Boyd)が最も速いという結果が得られました。この原因の1つとして、今回の(Duchi, 2008)では計算量が
のヒープソートを用いている一方、(Boyd)では初期の探索範囲に依存する二分探索を用いており、
の影響を受けにくいためと思われます。また
を大きくしていくと
程度の時に(Duchi, 2008)の計算時間は一次法を上回りました。一方、一次法と(Boyd)はグラフを見る限り、計算時間の増加度合いが同様に見られるため、(通常一概に言えませんが)本問題において計算量は同様のオーダーだと思われます。
今回、(Duchi, 2008)や(Boyd)はPythonで実装していたため、より高速に計算する必要が出てきた場合はCythonを用いたり、また(Duchi, 2008)などで提案されているソート方法を用いるのが良いかと思います。
まとめ
本稿では、確率単体へ射影するアルゴリズムを調査し、その計算時間の速さを確認しました。確率単体へ射影する問題は凸最適化問題であり、(一般的な手法を除いて)アルゴリズムの主な違いは最適解に含まれるパラメータを求める方法の違いになっていました。また動作確認を行なった結果、本実験では次元数が程度までの時は(Duchi, 2008) (ソート方法:ヒートソープ) が最も早く、それ以降は二分法を用いた(Boyd)の方法が最も早いことがわかりました。ソート方法や実装方法などによっても結果は大きく変わり得ますが、この結果を今後の業務に役立てられたらと思います。
参考文献
- Wang Weiran, and Miguel A. Carreira-Perpinán. "Projection onto the probability simplex: An efficient algorithm with a simple proof, and an application." arXiv preprint arXiv:1309.1541 (2013).
- Boyd Stephenの講義資料
- Yongzheng Dai, Chen Chen. "Distributed Projections onto a Simplex.", (2022).
- Duchi John, et al. "Efficient projections onto the l 1-ball for learning in high dimensions." Proceedings of the 25th international conference on Machine learning. (2008).
- Chen Yunmei, and Xiaojing Ye. "Projection onto a simplex." arXiv preprint arXiv:1101.6081 (2011).
- Condat Laurent. "Fast projection onto the simplex and the $\pmb {l} _\mathbf {1}$ ball." Mathematical Programming 158.1 (2016): 575-585.
- CVXPY
- Stellato, Bartolomeo, et al. "OSQP: An operator splitting solver for quadratic programs." Mathematical Programming Computation 12.4 (2020): 637-672.
参考:実装コード
以下、参考として掲載いたします。動作確認はしていますが、実運用を見据えたコードではないためご使用の際はご注意ください。 特に、二分法は初期点のチェックをしておらず、探索範囲を固定していますので、入力によっては解が得られない(計算が終わらない)場合があります。
import numpy as np import pandas as pd import cvxpy as cp class DuchiMethod(): def __init__(self, input_vector): self.input_vector = input_vector self.length_vector = len(input_vector) self.sort_vector = None def _sub_function(self, index): # 昇順であるため、分母の形が論文と異なる return ( 1/(self.length_vector - index) )* \ (1 - np.sum(self.sort_vector[index:])) def _function(self, index): return self.sort_vector[index] + self._sub_function(index) def main(self): self.sort_vector = np.sort(self.input_vector, kind = 'heap_sort') target_index = self.length_vector - 1 while self._function(target_index) >= 0: target_index -= 1 if target_index < 0: break target_index += 1 # lambdaと最適解 _lambda = self._sub_function(target_index) return np.array( [max(_lambda + component, 0) for component in self.input_vector] ) class BoydMethod(): def __init__(self, input_vector): self.input_vector = input_vector self.length_vector = len(input_vector) self.EPS = 1e-5 ## 変数の準備 # _lambda self._lambda_upper = (2**4) # 初期点は固定した。 self._lambda_lower = -1 * self._lambda_upper self._lambda_medium = 0 ## 関数の値 # 箱 self.value_upper = self._grad_dual_function(self._lambda_upper) self.value_lower = self._grad_dual_function(self._lambda_lower) self.value_medium = self._grad_dual_function(self._lambda_medium) ## 初期点が適切かどうかを確認するコード。 ## 適切でなかった際、初期点を変更する関数は追加で書く必要がある。 #self.check = self._initial_check() #def _initial_check(self): # return np.sign(self.value_upper) * np.sign(self.value_lower) def _grad_dual_function(self, _lambda): ## 第一項 # 準備 inner = self.input_vector - _lambda positive_mask = inner > 0 # 計算 term_1 = inner term_1[positive_mask] = 0 term_1 = -1 * np.sum(term_1) ## 第2項 term_2 = np.sum(self.input_vector) - 1 ## 第3項 term_3 = -1 * self.length_vector * _lambda return term_1 + term_2 + term_3 def _compare_value(self): if np.sign(self.value_upper) == np.sign(self.value_medium): return 'change upper' else: return 'change lower' def _cal_solution(self, _lambda): solution = np.zeros([self.length_vector, 2]) solution[:,0] = self.input_vector - _lambda solution = np.max(solution, axis = 1) return solution def main(self): while np.linalg.norm(self.value_medium) > self.EPS: # _lambda, valueの確認・更新 if self._compare_value() == 'change lower': self._lambda_lower = self._lambda_medium self.value_lower = self.value_medium elif self._compare_value() == 'change upper': self._lambda_upper = self._lambda_medium self.value_upper = self.value_medium # 残りの変数の更新 self._lambda_medium = (self._lambda_lower + self._lambda_upper) / 2 self.value_medium = self._grad_dual_function(self._lambda_medium) return self._cal_solution(self._lambda_medium) class FirstOrderMethod(): def __init__(self, input_vector): self.input_vector = input_vector self.length_vector = len(input_vector) def main(self): x = cp.Variable(self.length_vector) prob = cp.Problem( cp.Minimize((1/2)*cp.sum_squares(x - self.input_vector)), [cp.sum(x) == 1, x >= 0] ) prob.solve(solver=cp.OSQP) return x.value if __name__ == '__main__': ## サンプル例 n = 10 coef = 10 #coef = 0.1 # 動作確認 random_y = np.random.rand(n) y = coef * ( random_y / np.linalg.norm(random_y, ord = 1)) # 確認 duchi_method = DuchiMethod(y) d_output = duchi_method.main() print('DuchiMethodの動作確認結果', '\n出力の合計は:', np.sum(d_output), '\n全て正の値:', np.all(d_output >= 0) ) boyd_method = BoydMethod(y) b_output = boyd_method.main() print('BoydMethodの動作確認結果', '\n出力の合計は:', np.sum(b_output), '\n全て正の値:', np.all(b_output >= 0) ) first_method = FirstOrderMethod(y) f_output = first_method.main() print('FirstOrderMethodの動作確認結果', '\n出力の合計は:', np.sum(f_output), '\n全て正の値:', np.all(f_output >= 0) # 負の値が存在するが、絶対値は十分小さい )