こんにちは、Insigth EdgeでData ScientistをしているKNです。 本日は、Las Vegasで11月28日から12月2日まで行われたAWS re:Invent 2022に参加してきましたので、その報告をいたします。今回発表された新サービスについての深堀りやサービスの技術的な詳細については言及しません。私個人の感想、お気持ちメインとなりますのでご了承ください。
本記事の構成としては、まず最初にre:Inventの全体的な感想を述べた後、私が参加した講演の気になった点について報告させていただきます。
全体所感
今回、re:Inventには初参加です。まず、最初に驚いたのはそのスケールのデカさです。ラスベガスの複数のホテルに渡って会場になっており(日本の感覚からするとそのホテル自体十分大きいのですが)、来場者数も5万人超と圧巻でした。 イベントは、AWSの新しいサービスや新機能の発表のKeynoteが複数あり、AWSの各サービスの概要やユースケース紹介を教育を兼ねたSessionや実際に手を動かして使ってみるワークアウト等が常時複数開催されています。また、AWSに関連するサービスを展開する企業展示ブースがあります。
re:Inventの位置付けとしては巨大なファンイベントという感じで、AWS側からすると紹介や教育を通してもっとサービスを使ってもらおうという意図を感じました。 一企業のイベントでここまでの規模の人数を集客できる例はなかなか無いので、改めてAWSのサービス規模の大きさを実感しました。
確かに、KeynoteやSession等の発表を視聴するという意味ではオンラインでも十分かと思います(ましてや、人数多すぎて入ることすらできない発表があったり、会場の移動が遠くて次の講演に間に合わないといった問題があるくらいです)。 ですが、KeynoteでのリアクションやSessionの混み具合等でサービスへの期待度が分かったり、現地の担当者や参加者とコミュニケーションができたりしたので、そういったことは現地参加ならではかなと思います。また、4日間集中してどっぷりAWSに浸かることで、知識が深まりますし、今後試してみたいと思う機能も見つけることができました。
 図:Keynoteの様子。期待度が高いサービスの発表のときは会場が盛り上がります。そうでないときは...
図:Keynoteの様子。期待度が高いサービスの発表のときは会場が盛り上がります。そうでないときは...
 図:デバイス等の展示。Insight Edgeでは工場関連のプロジェクトも扱っているので気になるところです。
図:デバイス等の展示。Insight Edgeでは工場関連のプロジェクトも扱っているので気になるところです。
 図:ホテル会場の様子。緑のバケツはS3のマスコットのようです。
図:ホテル会場の様子。緑のバケツはS3のマスコットのようです。
 図:ホテル会場ではお菓子や飲み物が取り放題です。カロリーが無限に取れますね。
図:ホテル会場ではお菓子や飲み物が取り放題です。カロリーが無限に取れますね。
 図:打ち上げのイベントの入り口様子。ライブ会場ではEDMがガンガン流れて大変盛況でした。
図:打ち上げのイベントの入り口様子。ライブ会場ではEDMがガンガン流れて大変盛況でした。
各セッションについて
Improve customer retention with AI-powered contact centers
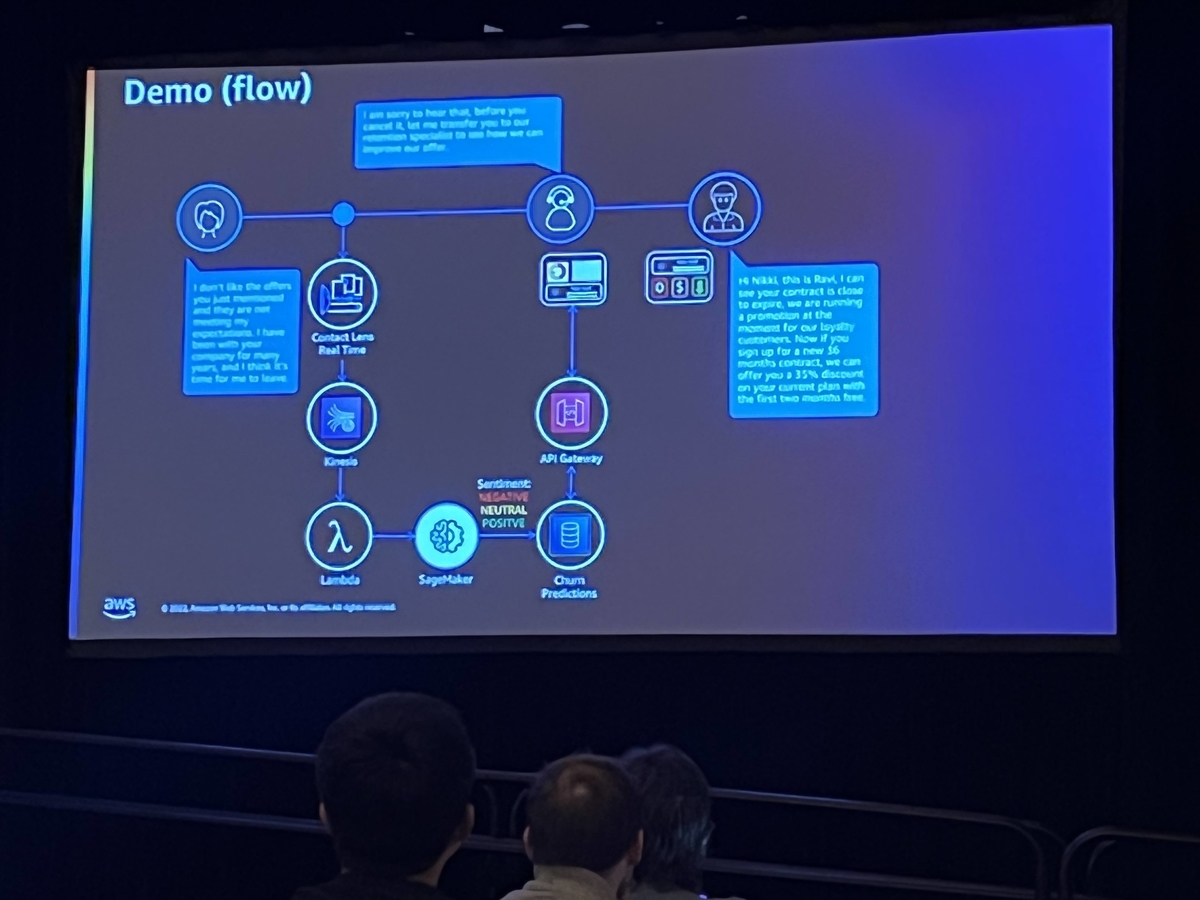
この講演はワークショップで、最初の30分で概要を聞いて、残り90分で指定された教材に従って問題を解くというものです。 内容はコールセンターにおける顧客のチャーン(離反)率をリアルタイムで予測して、それに対してアクションとれるようなシステムを構築するものでした。
予測モデル作成には「Amazon SageMaker」を、コールセンターの作成には、「Amazon Connnect」を使用しています。Amazon Connectを今まで使ったことはなかったのですが、数クリックするだけでそれらしいものができるのは新鮮でした。最後の方は各々携帯で架電して、自分の作ったコールセンターの機能を確認しました。
Use AWS IoT TwinMaker to easily create digital twins for aerospace uses
IoTデバイスの実物機のデジタル版(双子)を作ることができる、「AWS IoT Twin Maker」のワークショップでした。AWS Twin Makerの詳細については こちら 。
ここでは、ISS(国際宇宙ステーション)のストリームデータを対象に、ISSのモデルを作成して、Grafana上で確認できるようにしました。作業としては、ポチポチ押していくだけですが、簡単にわかりやすいダッシュボードを作れるのは良いですね。
 図:Twin Makerの作業画面。ISSのモデル化の様子。
図:Twin Makerの作業画面。ISSのモデル化の様子。
Workshopはネタとして面白いのが多かったです。しかし、時間の関係上、大部分は既にCloudFormationでリソースは自動作成されています。テキストに従って作業していくだけで、理解しないまま進めることができるので注意が必要です。勉強のためにも後で資料を公開してほしいところです。
Reliable scalability: How Amazon.com scales in the cloud
Amazonがどのように安定的にスケールするアーキテクチャを設計しているかについて紹介しているセッションです。AWSではアーキテクチャ設計のベストプラクティス方法を公開(リンクは こちら )していますが、ここでは具体的にAmazon.comでどのように実践されているかについて紹介されていました。
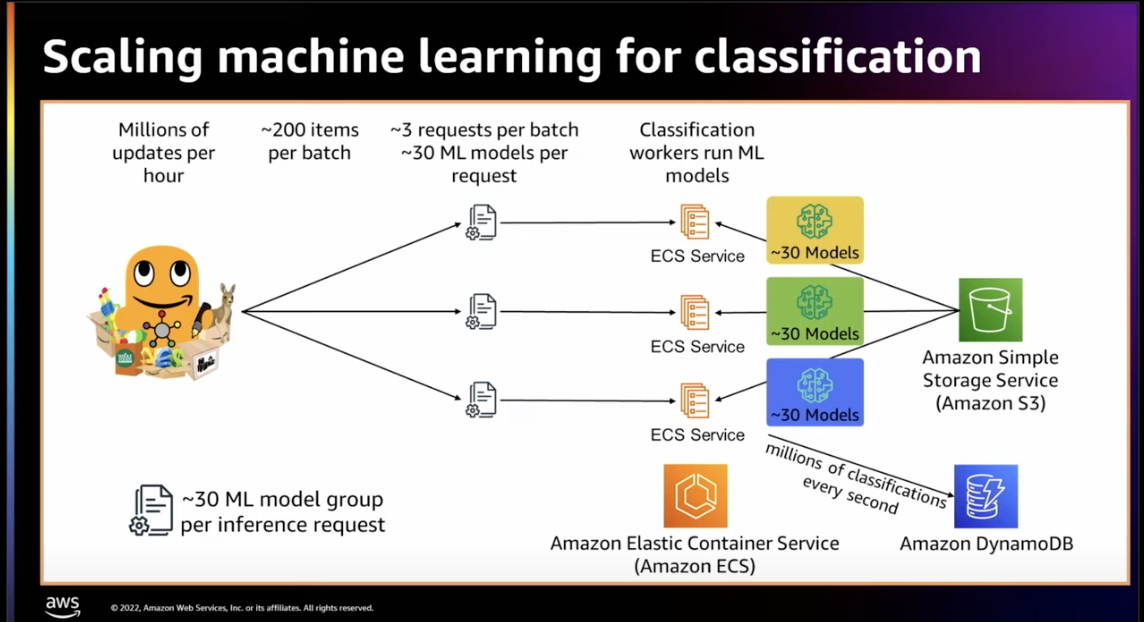
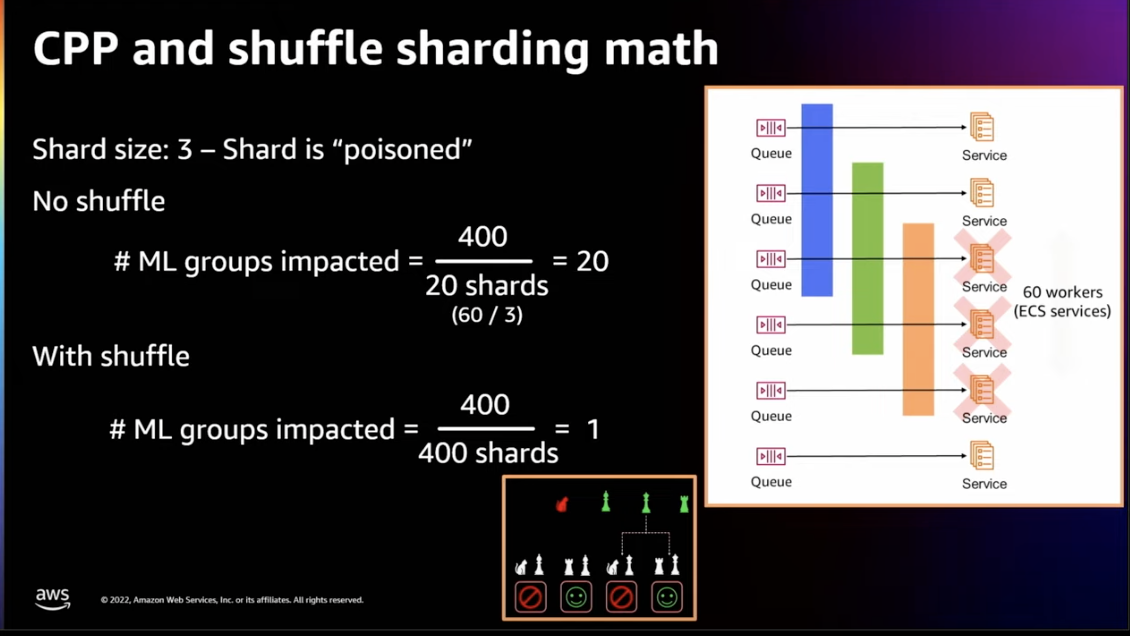
MLに関連するところでは、Amazonの商品のカテゴリ分類のアーキテクチャです。Amazonでは常時、商品ごとに1000モデルのカテゴリ分類を行なっていますが、そのバッチ処理の障害が他のワーカーに伝播しないようにShulle Shardingを採用しているとのことです。これにより、分散システム内での障害が伝播することを防げます。シンプルだけど、強力ですね。
How Stable Diffusion was built: Tips & tricks to train large AI models
日本でも話題になった「Stable Diffusion」のような大規模モデルの学習環境について紹介していました。 AWSの基盤を使って構築され、A100GPUの4000並列のクラスターを構成して学習されたようです。ネットワークは「Elastic Fablic Adapter」で接続して、ファイルシステムは「FSx for Lustre」です。クラスターの構成自体は「AWS ParallelCluster」の機能を使って、yamlファイルで簡単に記述できるようです。また、「Stable Diffusion」を作成した「Stablity AI」のCEOが参加して、今後の生成系AIの展望を語ってくれました。

他にも数多くセッションに参加しましたが、今回はここまでにしたいと思います。別途機会があれば、イベントで紹介された新機能について紹介できればと思います。